



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Google AX 控制面拆解:分布式 Agent 如何把断点恢复、审计策略和执行调度收进同一条链路
时间:2026-07-02 09:39:09 编辑:袖梨 来源:一聚教程网
很多 Agent 框架都在解决“怎么把模型用起来”。真到线上,麻烦往往不在提示词,也不只在工具编排,而是在另一层:任务跑得久了,状态怎么留;执行跨进程、跨节点以后,谁来兜住调度和故障;一旦 Agent 能碰 Bash、MCP 和外部 API,权限、审计、限流又该放在哪里。
Google AX 这套东西,价值不在于再发明一个 Agent 框架。它更像是在现有框架、模型和工具之上,补了一层真正能拿去跑生产任务的 Agent Runtime + Execution Control Plane。你可以把它理解成:上面接各种 Agent 形态,下面落到真实执行环境,中间用一条 可恢复、可审计、可扩展 的执行链把事情串起来。
AX 放在技术栈的哪个位置
先看它在技术栈里的位置。AX 既不是模型层,也不是某个具体框架的替代品。 它插在 Agent 应用和底层基础设施中间,负责把上层的任务意图翻译成一套可追踪的执行过程。
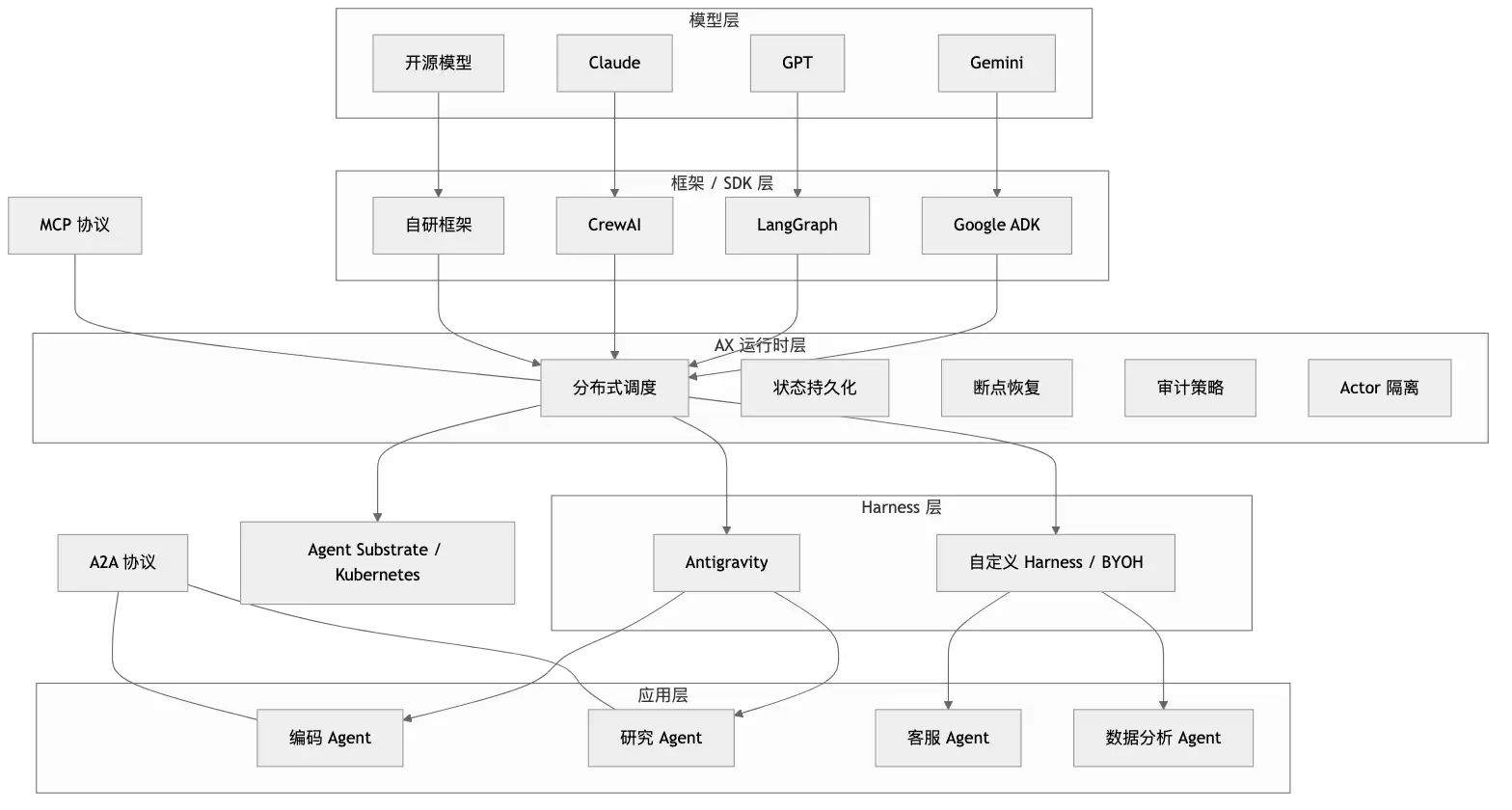
图:AX 位于 Agent 应用与底层执行基础设施之间,负责托住执行过程。
这层位置很关键。它意味着 AX 对上层 Agent 实现基本保持中立,对下层模型也不强绑定。你可以继续用 ADK、LangGraph,甚至是自己的 Harness;也可以换模型,而不必动到 AX 的核心职责。换句话说,它想管的是 执行,不是 思考。
真正的核心不是 Agent,而是 Controller
系统里最重要的组件不是某个 Planner Agent,而是 Controller。因为一旦把 Agent 执行当成生产系统问题,第一优先级就不再是“会不会推理”,而是“谁在协调、记账、路由和兜底”。
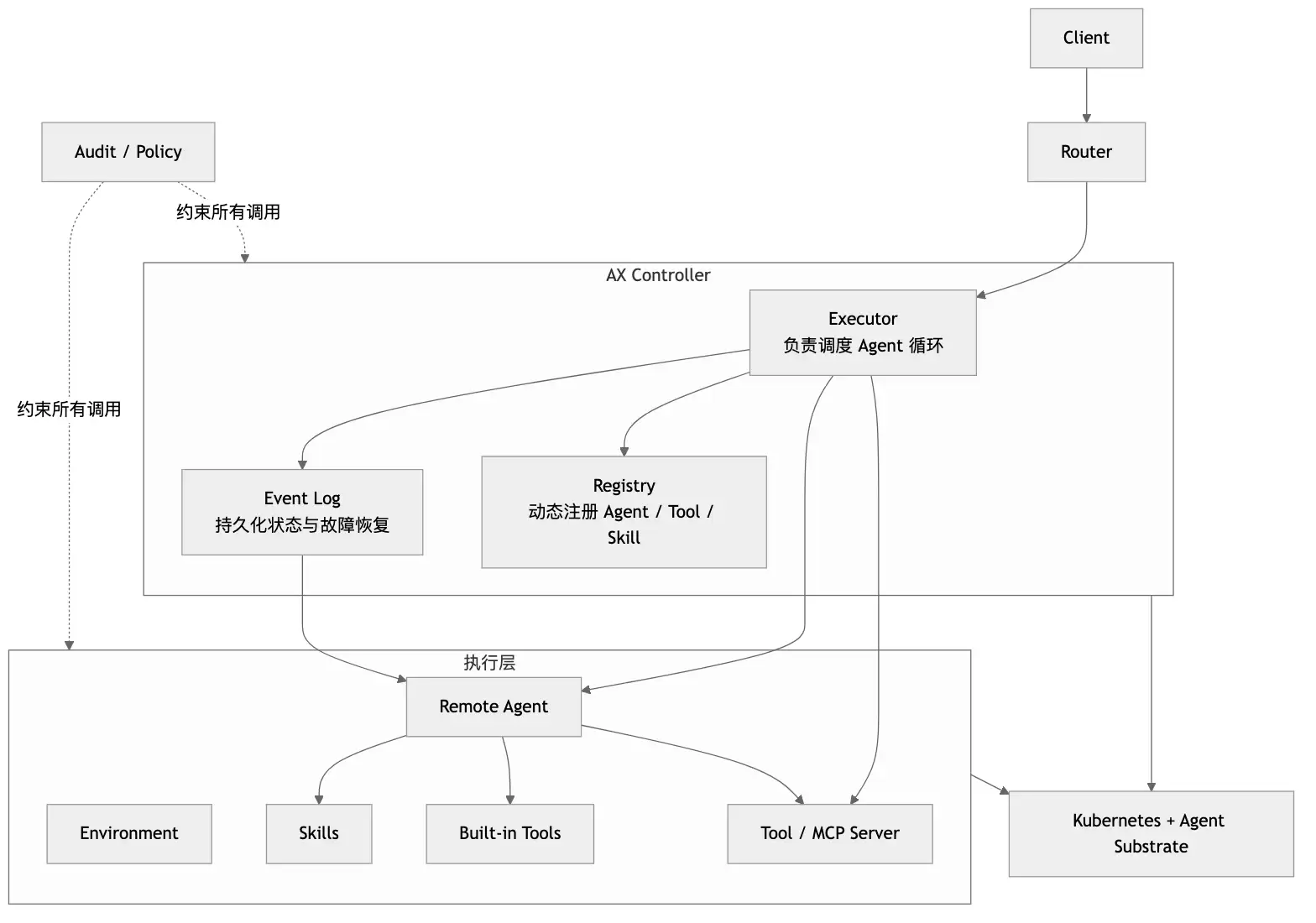
图:Controller 通过 Executor、Registry 和 Event Log 统一托管执行链。
这里有三个角色值得单拎出来:
Executor决定这次任务该往哪里跑,什么时候继续,什么时候停。Registry把可用的Agent、Tool、Skill暴露成一张可查询的能力表,运行时不用写死依赖。Event Log不是普通日志,它记录的是 执行进度本身,所以它参与恢复,不只是排错。
这也是 AX 和不少“框架式 Agent 编排器”的分水岭。后者更关心节点之间怎么流转,AX 更关心 流转发生以后,系统能不能把整个过程可靠地托住。
一次任务真正怎么跑完
AX 并不是把所有事塞给单个 Agent,而是把请求拆成几段:入口路由、Planner 分析、远程 Agent 执行、Tool 调用、状态回写。中间哪一段出问题,Controller 都能知道当前停在什么位置。
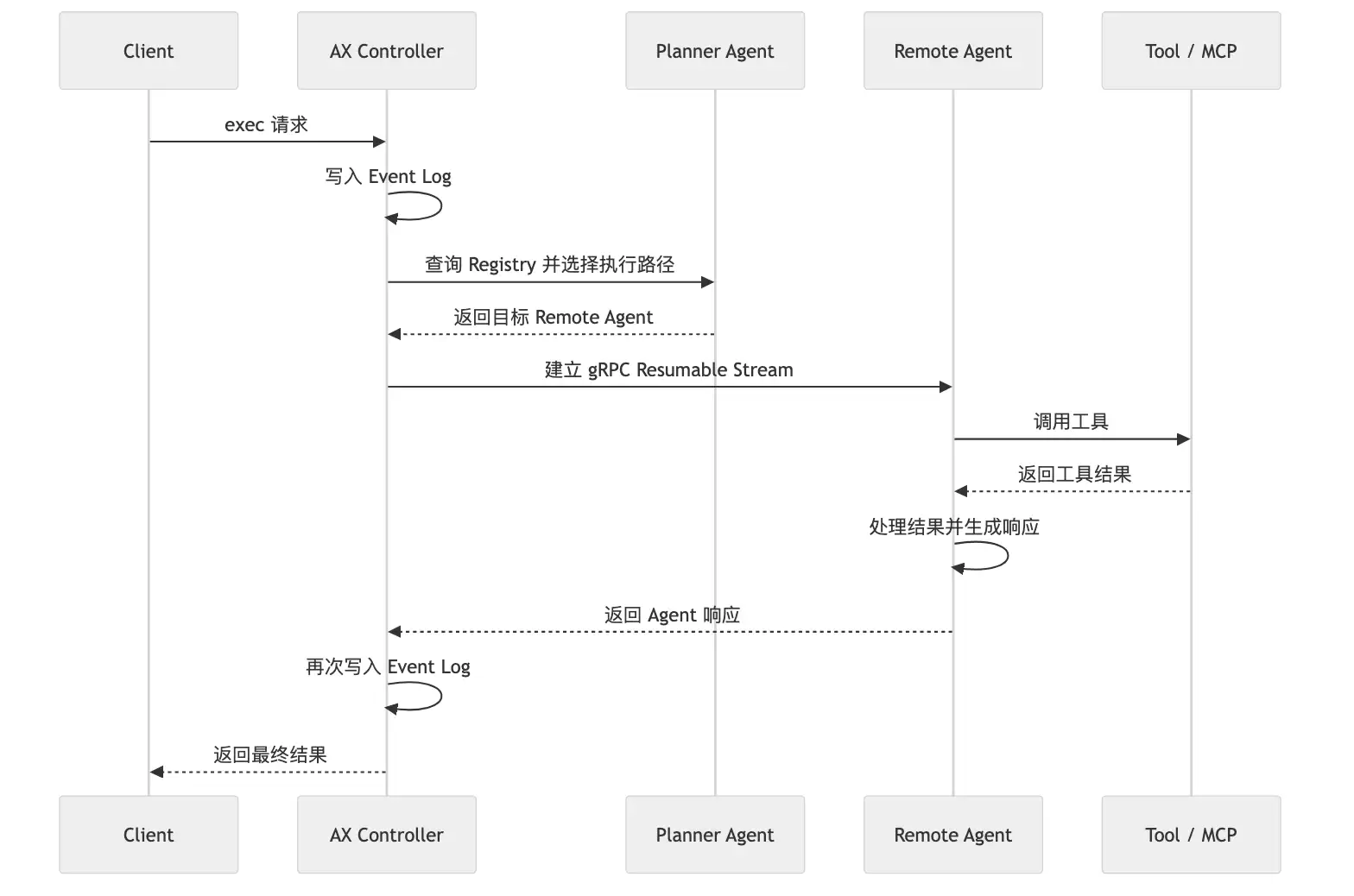
图:一次任务会经过路由、规划、远程执行、工具调用和状态回写。
这条链路里最容易被低估的是 Resumable Stream。如果只是普通 RPC,连接断了就断了,调用方只能重试。AX 把执行过程做成 可恢复的流,等于承认一件很现实的事:长任务在真实环境里就是会被打断,系统应该把“中断”当成常态,而不是异常。
分布式不是卖点,是隔离故障域的手段
很多人一看到“分布式运行时”,会先想到扩容。AX 这套设计更实在,它首先解决的是 隔离。Controller、Skills、Tools、Agents 都可以独立部署在不同进程甚至不同节点,远程 Agent 通过 gRPC 和 Controller 通信,失败边界天然被切开了。
这带来几个直接好处:
- 远程 Agent 跑崩,不会把 Controller 一起拖下去。
- 高风险工具可以丢到单独环境里跑,权限边界更干净。
- 资源型任务和轻量型任务能分开调度,不必共享一个执行池。
- 某个 Agent 的噪声日志、内存暴涨、重试风暴,不会污染整条链路。
不少介绍会把它放成一个单独能力点,但我觉得它其实是整套系统的基础假设:Agent 不该默认和调度器同生共死。
Event Log 不是辅助信息,它就是恢复现场
真正让长任务可恢复的,不是简单保存一个“任务成功 / 失败”状态,而是把执行过程按序号持续落盘,让系统随时知道上次稳定位置停在哪。
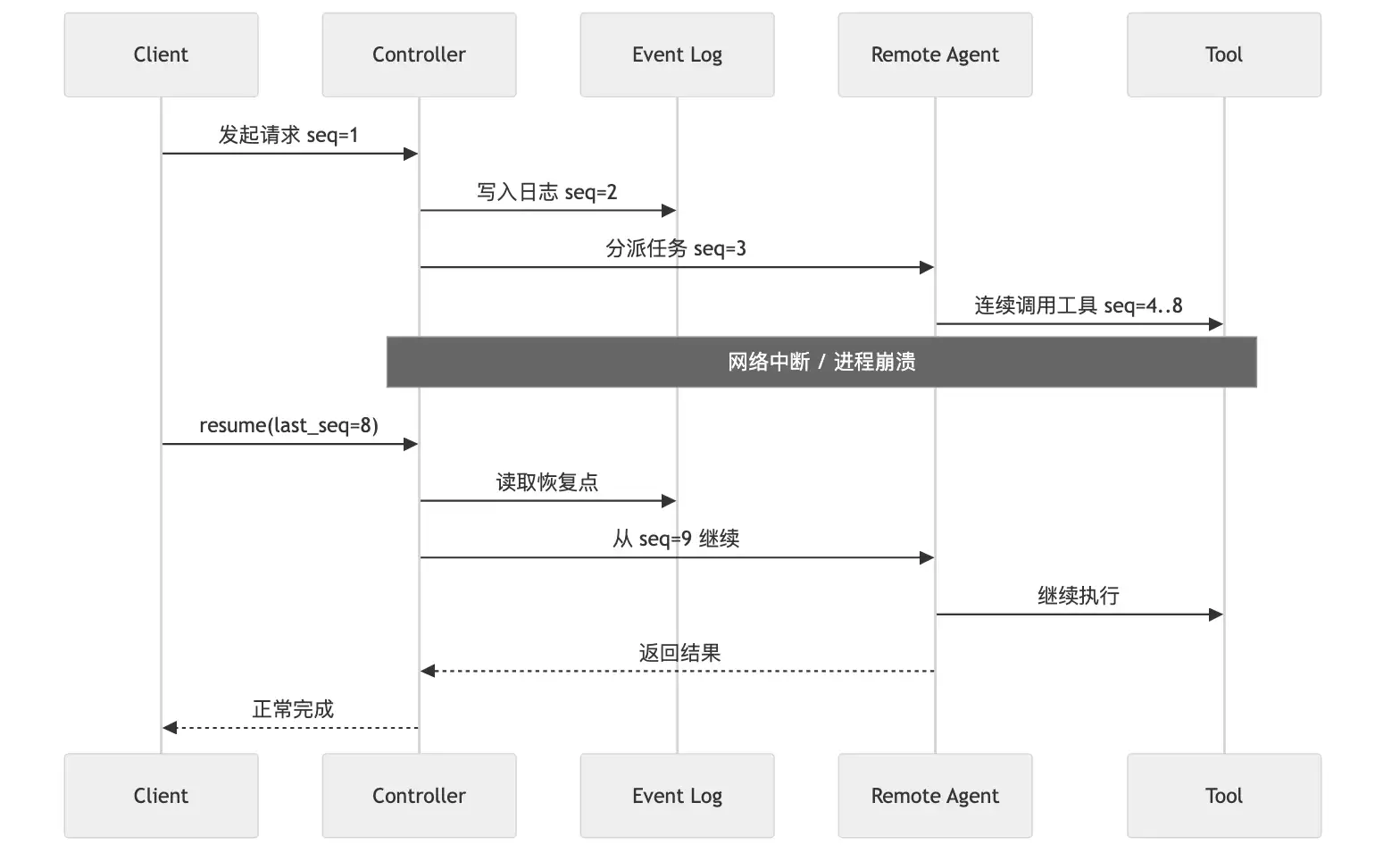
图:Event Log 记录稳定序号,让长任务能从中断点继续。
这类设计在几个场景里尤其有用:
- 深度研究类任务 动辄跑几十分钟,中途掉线很常见。
- 多工具链路 往往包含外部 API,失败率不受你控制。
- 人工介入审批后继续执行,天然就是分段运行。
Event Log 是 single source of truth。这不是修辞。只要你真的想做恢复、回放、审计和分叉,系统就必须承认有一份权威执行历史存在,而且它不能只放在内存里。
AX 为什么坚持做框架无关接入
AX 的接入方式做得很杂,但这个“杂”是有理由的。它不要求所有 Agent 都按一种写法来实现,而是给了四条进场路径:
| 接入方式 | 适合什么场景 | 运行时特征 |
|---|---|---|
| 原生远程 Agent | 已经有独立 Agent 服务 | 通过 AgentService.Connect 建立 gRPC 双向可恢复流 |
| Google ADK Agent | Python 生态里的 ADK 项目 | 由 Python ADK Agent 直接接入,底层通信封装为 gRPC |
| A2A Bridge Agent | 团队已有 A2A 兼容 Agent | 通过 A2A Bridge 转换协议与标头 |
| Colab Agent | 研究和实验任务 | 支持把 Python 脚本或 Notebook 作为执行入口 |
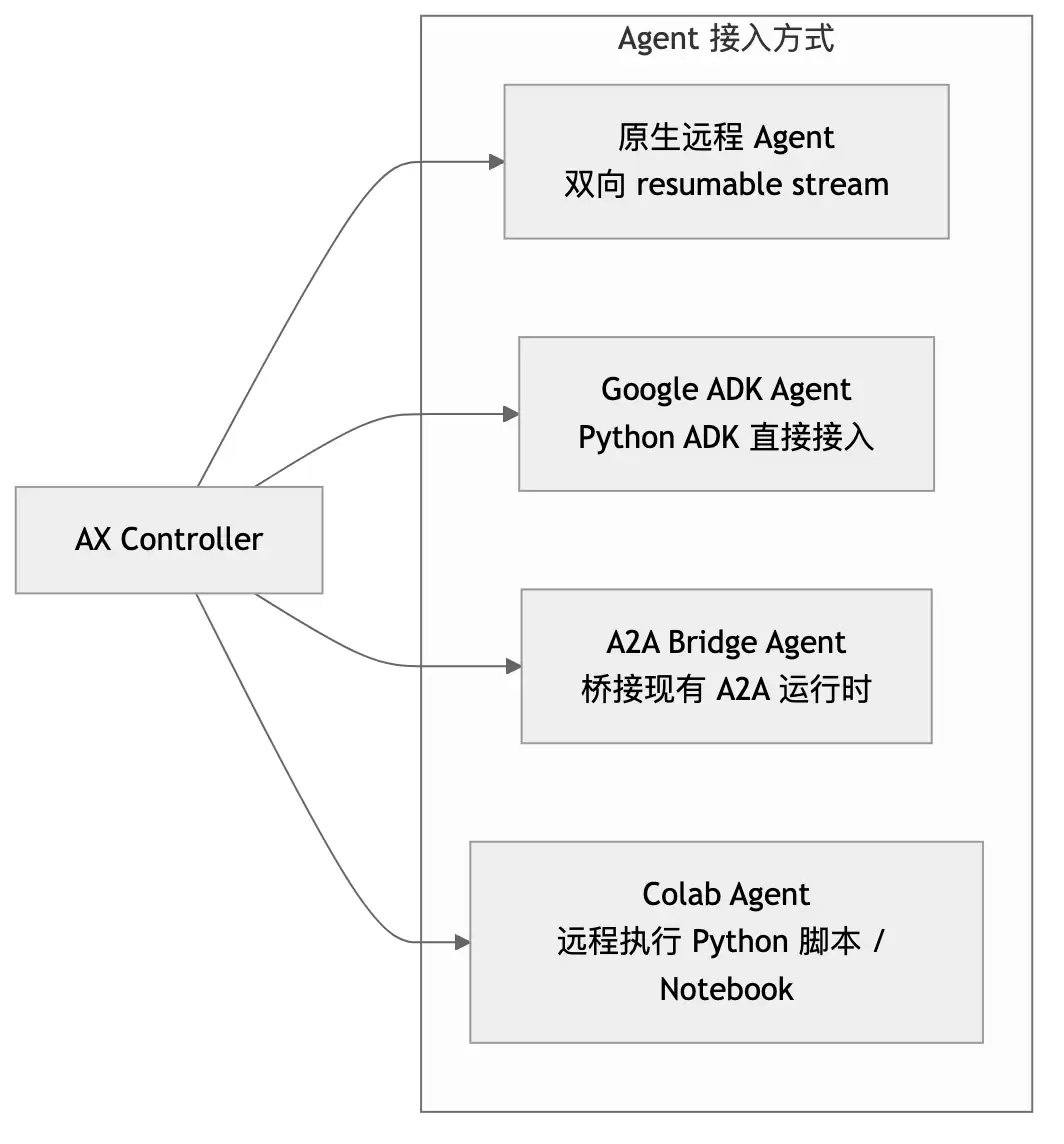
图:AX 通过多种接入模式兼容已有 Agent 生态,而不要求统一重写。
这背后的判断很工程化:企业里不会只有一种 Agent 形态。 有人用 Python,有人已经做了 A2A 协议,有人只是想把现成脚本纳入统一调度。让这些东西都重写一遍,系统很难落地。把协议边界做厚一点,反而更现实。
审计和权限别散在各个 Tool 里
AX 最像“基础设施”而不是“框架”的地方,就在 审计与策略控制。所有用户请求、Agent 请求、Tool 调用都经过 Controller 这一个控制面,于是权限校验、调用记录、执行限流和审批流可以集中处理。
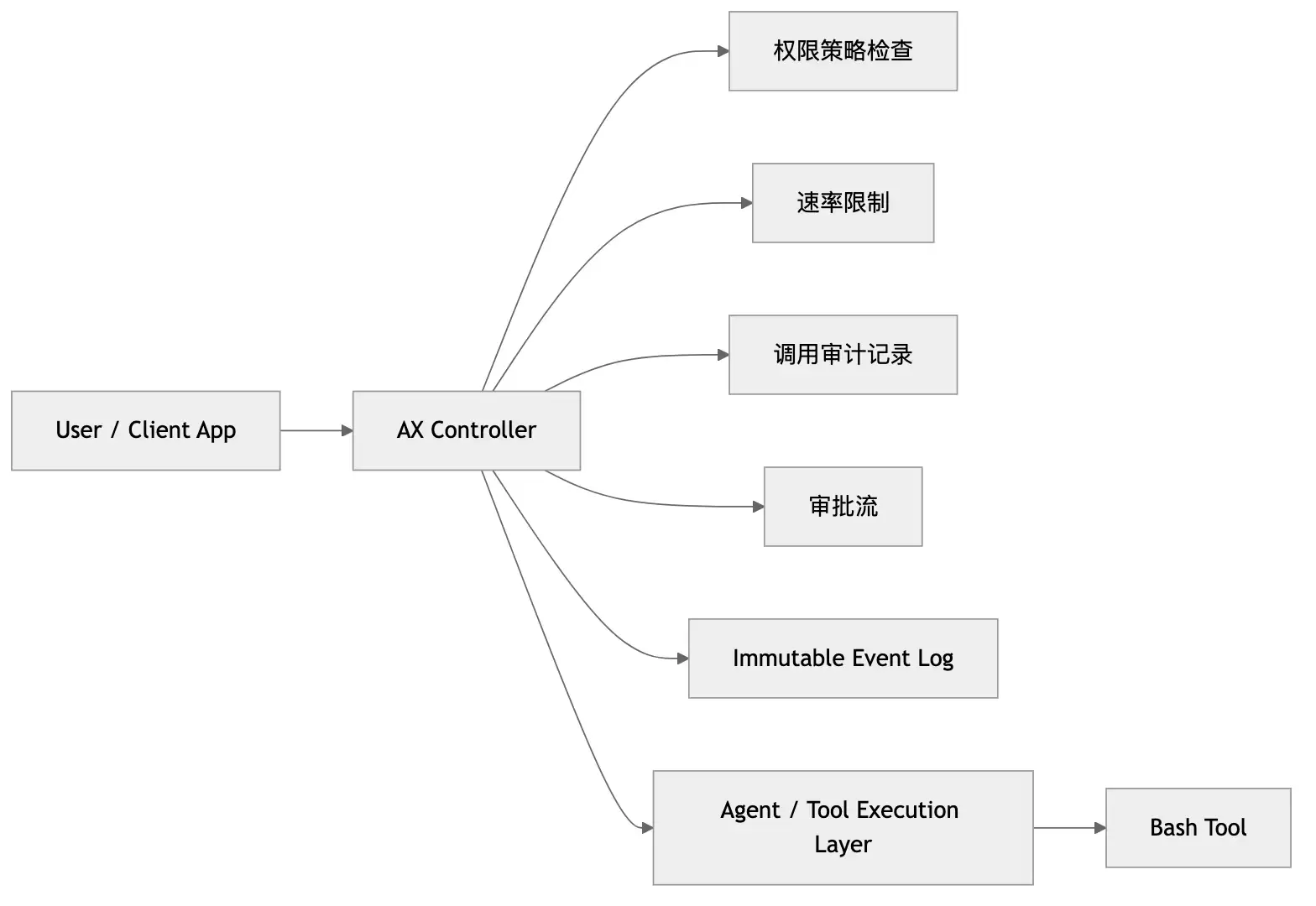
图:把权限、限流、审计和审批放回控制面,才能真正治理 Agent 行为。
这套做法的好处很直接:
- 安全规则不会散落在每个 Tool 的私有实现里。
- 需要人工确认的危险操作,比如
Bash执行,可以被统一拦下来。 - 出了问题以后,能回溯到是哪次请求、哪个 Agent、哪一步工具调用触发的。
尤其是 Bash Tool 的“需用户确认才能执行”,看起来像个小功能,其实透露出整套系统的安全姿势:默认不信任 Agent 的执行冲动,必须给控制面留一个人工刹车。
Session Fork 解决的不是重试,而是低成本试错
如果只想断点恢复,事件日志已经够用了。AX 还额外做了 会话分叉,这说明它想支持的不只是“接着跑”,还有“从历史某一点拐出去跑另一条线”。

图:同一份执行历史既能恢复原链路,也能从稳定点分叉试错。
这在几个地方很有用:
What-if分析,不想污染原任务链路。- 回溯重试,直接从失败前的稳定点重开。
- 长任务跑到一半想验证另一套参数,不必整段重来。
这也是为什么 Fork 和 Resumption 必须分开看。恢复解决的是可靠性,分叉解决的是探索效率。 两者依赖同一份事件历史,但目标并不一样。
如果把 AX 当成一句话,它在补“Agent 缺的控制面”
Google AX 想解决的不是 Agent 是否足够聪明,而是 Agent 一旦进入真实执行环境,系统还缺哪几块硬骨头。它给出的答案也很明确:
- 用 Controller 把执行调度从 Agent 本体里抽出来。
- 用 Event Log 把任务状态外化,支持恢复、回放和分叉。
- 用 分布式部署 和 Actor 隔离 切开故障域。
- 用 统一控制面 接住审计、权限、限流和审批。
- 用 多种接入方式 兼容已有 Agent 生态,而不是要求世界重写。
这套设计最适合那类已经迈过“做个 Demo”阶段、开始在乎 稳定性 和 可治理性 的团队。你可以不采用 AX 的全部形态,但它提出的问题躲不掉:任务长了怎么办,状态丢了怎么办,Agent 能动真工具以后谁来兜底,出了事故以后靠什么回放现场。
如果说大模型在补“推理能力”,AX 这种运行时做的事更像补 工程常识。没有这层,Agent 很容易停在漂亮演示;有了这层,才算真正碰到生产系统的门槛。
推荐阅读
业务 Agent 搭建指南:别急着重造 Agent,用知识、工具与评测跑通闭环
AI Native 竞争力:真正稀缺的不是会用 AI,而是把事往前推的人
Harness Engineering:Agent 真正能交付,靠的不是更强模型,而是上下文、执行协议和验收闸门
AI Coding 如何影响交付链路重构:写代码更快了,为什么人反而觉得更累了?
Agentic Skill Routing 实战:别再把所有 Skill 塞进 AI Agent 上下文
相关文章
- 忘川风华录2026名士培养 开局天级名士选择指南 07-02
- 网传 Karpathy 的 CLAUDE.md 曝光: 10条铁律管住Claude Code! 07-02
- 知识库 OfficeCLI:一行命令搞定 Word/Excel/PPT:AI 时代的文档处理利器 07-02
- 从 Axure HTML 到 Ardot:一次 AI 原型迁移的实践 07-02
- 游戏卡片 07-02
- 手机壳花纹 07-02