



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
从 Axure HTML 到 Ardot:一次 AI 原型迁移的实践
时间:2026-07-02 11:02:46 编辑:袖梨 来源:一聚教程网
迁移Axure原型的挑战,AI如何帮你高效完成?核心内容:1. 从Axure转向Ardot的动因与工具限制2. 建立AI驱动的规则框架,确保组件复用与可编辑性3. 静态页面复现与文件组织策略,避开复杂交互
Axure 是我日常工作使用的原型软件,有两个原因让我考虑迁移到新工具。
一个原因是我当前使用的版本是 Axure 9,它是 Intel 应用。Apple 已明确表示,Rosetta 对应用的支持将在 macOS 27 之后结束,也就是说,后续依赖 Rosetta 运行的 Intel 应用会面临兼容性问题。
而 Axure 从 10 版本开始虽然有 macOS 原生应用,但只提供订阅制,每月 29 美元,这对于平平打工人一枚的我来说太贵了(付费上班不可接受)。
另一个原因是我近期正在探索的 Ardot,它的形态更像 Figma,并且提供了本地 MCP 让 AI 直接操作设计文件。也就是说,只要你的 Token 足够,你就可以让 AI 一直帮你改原型。
于是我决定尝试让 AI 帮我将已有的 Axure 原型迁移到 Ardot 里。但 Axure 的
腾讯 Ardot 官方文档[1] 中提供了 H2D,也就是 HTML to Design 功能,可以将 HTML 代码或网页 URL 转成可编辑设计文件。但它更适合单个页面的视觉恢复。我的目标是批量迁移后台系统页面,并且要求组件复用、sidepanel 统一、表格结构可维护、manifest 可交接,所以这次没有把 H2D 作为主方案。
所以这次实践的核心问题就变成了,如何从 Axure HTML 出发,借助 MCP 工具,让 AI 在 Ardot 里重新生成一套可编辑原型。
这件事做下来,我最大的感受是,难点不在于让 AI 画出一个像样的页面,而在于让它每一次都按同样的规则画页面。
如果只追求看起来差不多,AI 能做到 60-70 分。
如果要求图层清楚、组件可复用、内容能继续编辑、后续页面还能交给别的模型接着做,那就必须先建立规则。
做这类转换前,我觉得最重要的不是马上让 AI 开工,而是帮 Agent 梳理好整个任务的框架。
首先是对任务边界的限定。
Ardot 当前还没有上线类似 Figma 的「连线」功能,即便后续支持,让 AI 去理解 Axure 中的复杂交互再还原到 Ardot 中也是一件费力不讨好的事情,很可能消耗大量 Token 也没能实现。因此我只要求 AI 帮我复现静态页面,复杂的交互逻辑则一概忽略。
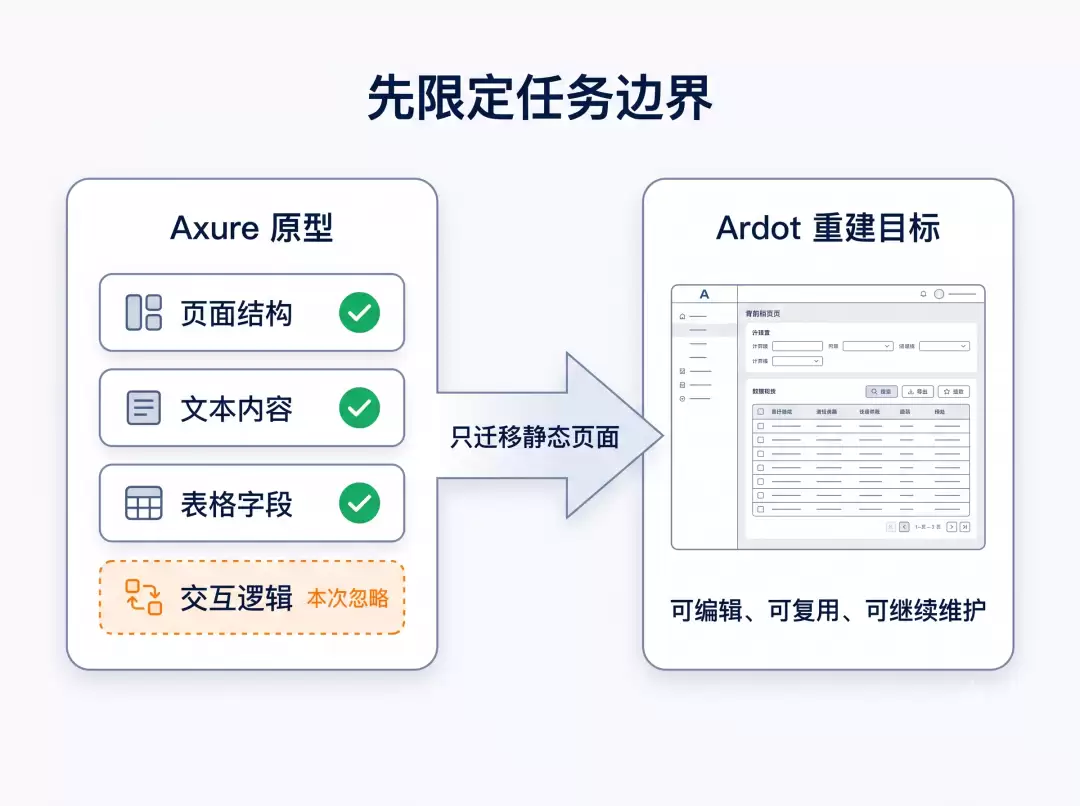
其次是文件组织。
我当前的工作涉及到多个系统的原型设计,移动端、PC 端,业务系统、财务系统,每个系统都有多个一级菜单以及子菜单。
在 Axure 中,一个页面本质上是一个独立的文档,只有在打开时才需要渲染当前页面。即使项目里有 500 个页面,真正占用资源的通常只有你正在编辑的那一页。因此我在 Axure 中的做法是将所有系统的原型页面都放在一个 RP 文件中,这样方便交付和团队协作。
但 Ardot 和 Figma 类似,一个文件相当于一个无限大的画布,里面所有的 Page、Frame、Component、Variable、Prototype 都属于同一个文档。虽然 Page 可以帮助组织内容,但它们并没有把文档真正拆开。比如一个 File 拥有三个 Page,每个 Page 包含 400 个 Frame,这对 Figma 来说仍然是一个拥有 1200 个 Frame 的文件。
因此我需要把每个系统拆成独立的文件,这一点也需要提前规划并向 AI 澄清。
再次是对 Axure 导出的 HTML 文件的处理。
Axure 导出的 HTML 不是一个单纯的静态页面。
它有页面入口,有资源目录,有脚本,有图片,有页面之间的跳转关系。有些页面里的内容不是直接写在 HTML 里,而是需要浏览器把脚本跑起来之后才能看到最终结果。
所以只让 AI 读 HTML 文件是不够的。
我后来采用的做法是,用本地 HTTP 服务把 Axure HTML 跑起来,再用 Playwright 打开页面,把渲染后的元素信息和截图导出来。
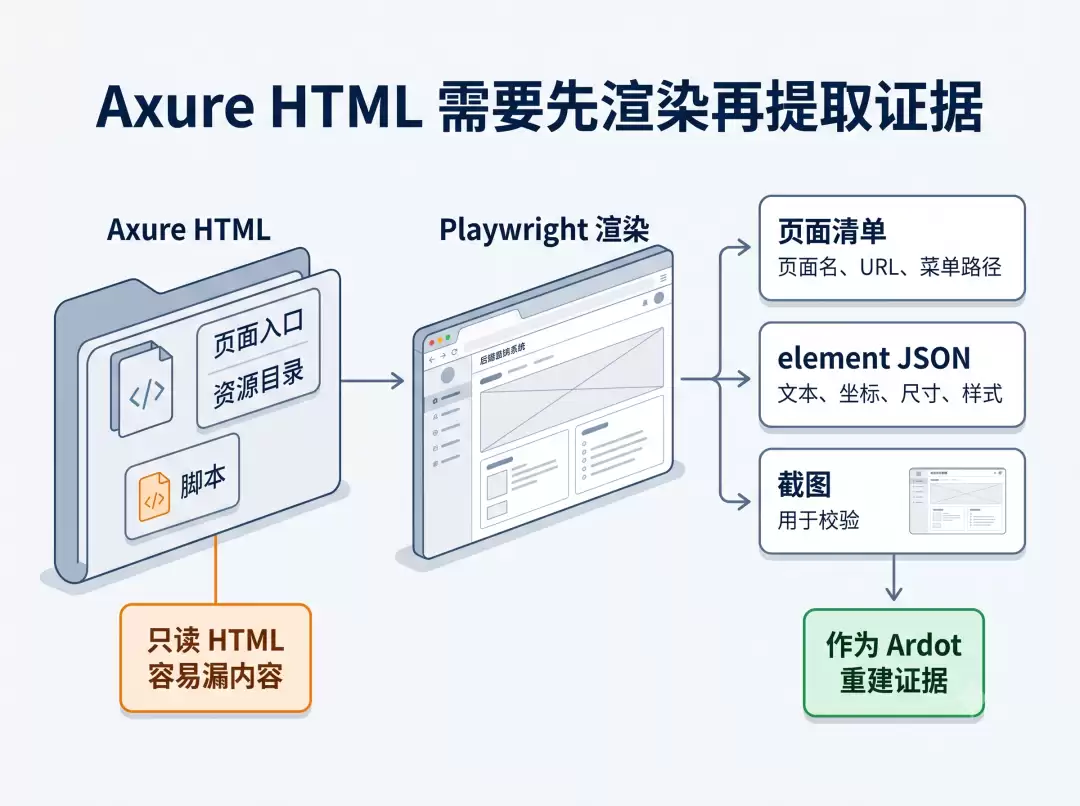
这里会得到三类材料。
第一类是页面清单,也就是每个页面叫什么、URL 是什么、属于哪个菜单、父级路径是什么。
第二类是 element JSON,也就是页面渲染后有哪些文本、坐标、尺寸、图片和样式。
第三类是截图,用来和 Ardot 重建后的结果做对比。
这三类材料的作用不一样。
页面清单解决命名和归属问题。比如某个页面其实是三级菜单,就不能只按页面标题命名,而要带上它的上级菜单。
element JSON 解决内容问题。表格有哪些列,筛选区有哪些字段,按钮叫什么,样例数据是什么,都从这里来。
截图解决校验问题。AI 说自己完成了不算,至少要看一下重建后的页面有没有明显错位、遮挡、漏区域。
还有一个关键点,是提前准备本地组件库。
如果不给 AI 组件,它很容易自己画按钮、输入框、下拉框、表格和分页。看起来可能差不多,但后面基本没法维护。
所以我在 Ardot 文件里准备了本地 TDesign 组件库。按钮用 Button,输入框用 Input,选择器用 Select,分页用 Pagination,表格列用 table column。侧边栏这种系统相关组件,则先手动画一个示例组件,然后让页面去复用这个组件实例。
再往下,就是设计变量。
颜色、间距、圆角这些东西,不要让 AI 每次自己填数值。比如 Content 内边距统一 24,绑定 spacing-xl。TitleBar 的底部分隔线使用 border-default。页面背景、边框、文字颜色都尽量走变量。
这些准备工作看起来有点啰嗦,但它们是整个任务的基石,直接决定了 AI 的执行效率和交付效果。
整个任务执行过程中最重要的步骤,是在任务完成后让 AI 复盘。
在面对一个新的探索任务时,我的常规做法都是先让 AI 做一轮 DeepResearch,之后创建一个
一开始由于没有任何标准流程,AI 可能会出错,可能消耗大量 Token 但交付结果很差,这都没关系,只需要在每次任务结束时发挥 AI 最擅长的能力「总结复盘」,让 AI 提炼 SOP 流程,将犯过的错转换成预防性的规则,最终就能建立一套规则体系,让 AI 每次接手时都知道应该读什么、按什么规则做、做完以后把状态写到哪里。

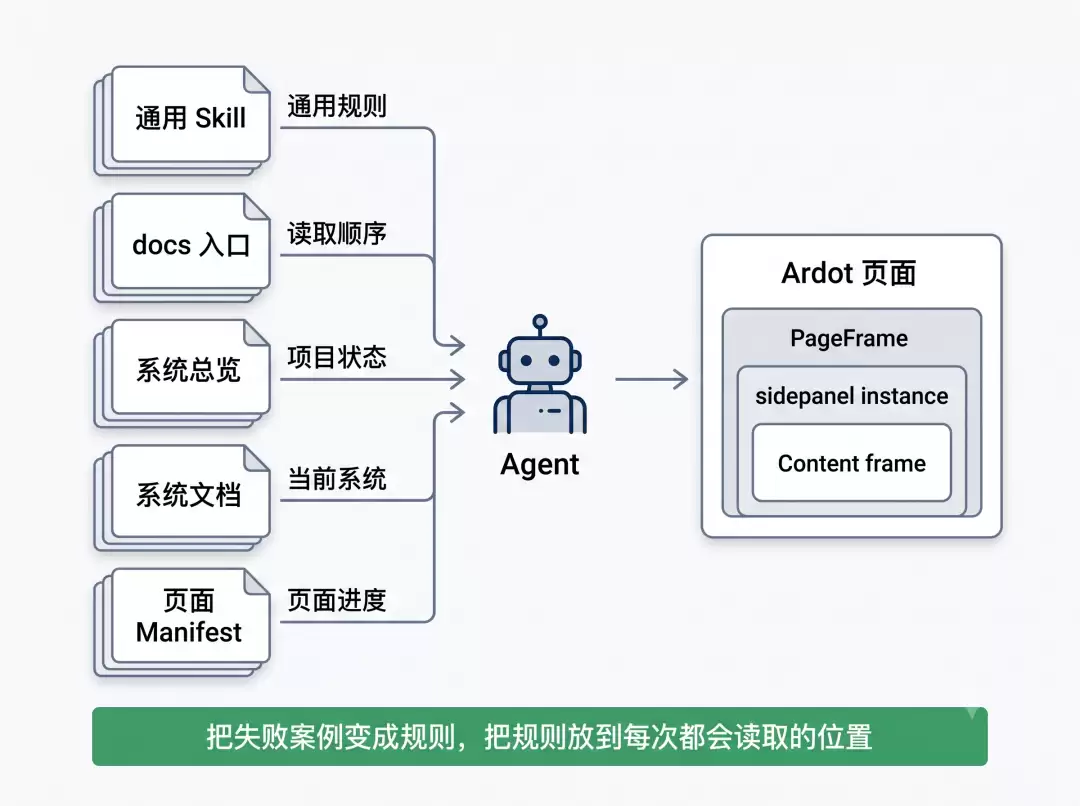
具体到本次任务,我最终形成了两部分内容:项目里的轻量文档,和可复用的 skill。
最先读的是通用 skill,也就是
这里沉淀了 HTML 文件转换过程可直接遵循的规则。
比如 HTML 必须先用 Playwright 渲染,不能只靠文件名和静态 HTML 猜页面。
比如 Ardot 页面必须是
比如 Content 不转组件,列表页、表单页、详情页、报表页各自有页面规范,表格必须用
再比如执行前后要检查什么,常见失败模式有哪些,怎样避免大段 HTML、压缩
每次开启任务,AI 都会自动激活 skill,遵循其中的规则执行转换任务。
项目里的文档主要负责介绍项目背景,记录任务进度和保存可复用的知识。
它告诉后续 agent 按什么顺序读:先读
第二层是
它像一个项目看板,记录 CRM、OMS 这些系统分别做到哪里。
这里会写每个系统对应的 Ardot 文件、fileId、manifest、页面总数、已完成数量、当前批次、下一步和主要风险。
它不写详细 SOP,只回答一个问题:这个项目现在是什么状态。
第三层是系统文档,比如
它只保留某一个系统当前实施状态。
包括 Ardot 文件、页面范围、已确认的 sidepanel、已完成批次、已知限制和下一步。
比如 OMS 已完成销售订单管理和计划管理,下一批是报表录入、月报和经营分析。开始前要确认对应 sidepanel,并抓取 element JSON 和截图。
再往下是系统 manifest。
Markdown 是给人和 agent 快速接手看的,manifest 是机器可读的进度表。
每一页的 pageId、PageFrame、Content、素材路径、状态和验证结果,都应该以
这样一来,文档之间就有了清楚分工。
docs/README.md 负责告诉 agent 先读什么。 docs/系统转换总览.md 负责记录多个系统的整体进度。 docs/systems/OMS.md 负责记录单个系统的当前状态和交接信息。 out/ardot_manifest_ .json 负责保存页面级的机器可读进度。 ardot-html-prototype-converter skill 负责沉淀通用 SOP、页面规范、执行检查清单、失败模式和 Token 约束。
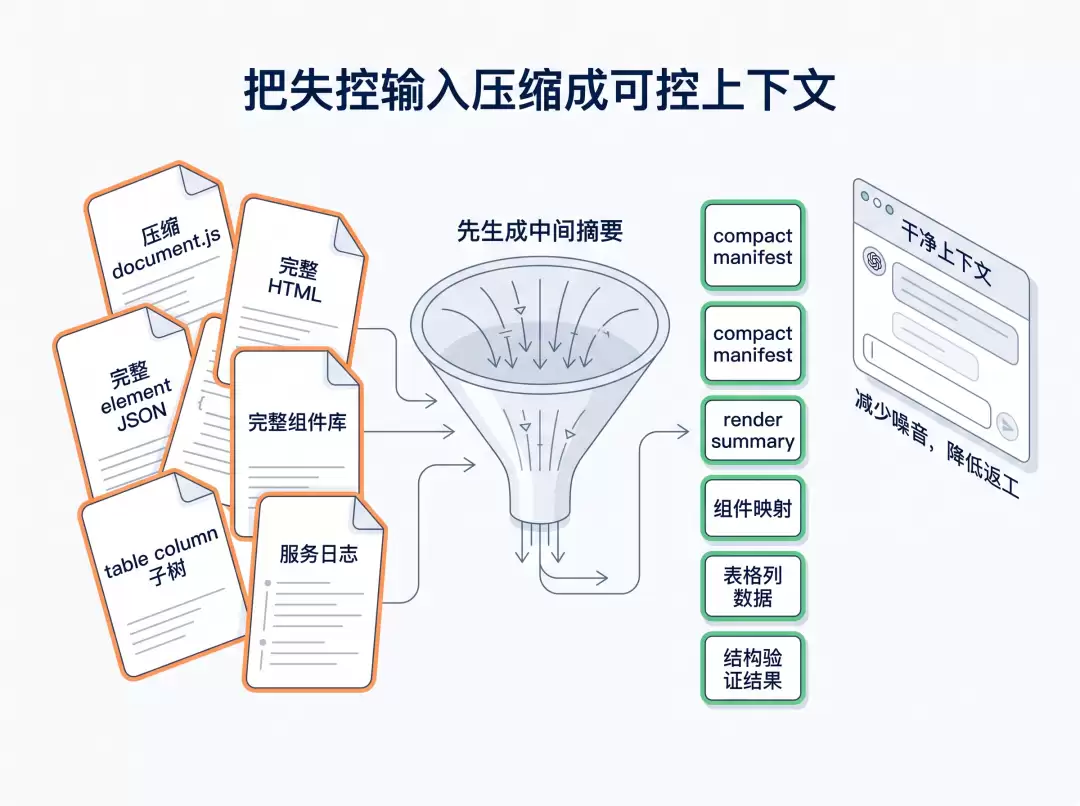
把 Axure HTML 原型迁移到 Ardot,最容易失控的地方其实是上下文。
这类任务会同时牵涉 HTML、页面树、渲染结果、截图、组件库、Ardot 节点结构和验证结果。每一类材料单独看都不小,合在一起就很容易把上下文撑爆。更麻烦的是,很多原始材料并不是为模型阅读准备的。Axure 导出的页面树可能是一大段压缩后的 document.js,Ardot 组件库也可能是一层层嵌套的实例树。如果不加限制,模型还没开始真正生成页面,token 就已经大量消耗在工具输出的噪音上。
多次任务总结下来,我发现很多 Token 不是花在「让模型思考」上,而是花在了工具输出的噪音上。
因此节省 Token 最关键的一点,是把「直接读取原始材料」改成「先生成中间摘要」。
比如页面树不直接塞给模型,而是先解析成 compact manifest。这个 manifest 只保留当前任务需要的 pageId、页面名、HTML 路径、完整菜单 path、页面类型和处理状态。这样模型看到的是一张清楚的任务清单,而不是一整坨压缩 JS。
Playwright 渲染也是一样。完整 element JSON 和截图必须保留,因为它们是重建页面的证据。但这些证据不需要全部进入对话。真正交给模型的,应该是 render summary:页面标题、筛选项、按钮、表格列、样例数据、页面宽高,以及这个页面是否接近截图型页面。完整材料落到本地,摘要进入上下文,这样既不丢证据,也不会让模型被无关节点淹没。
组件库也要控制读取次数。
Ardot 文件里的 Button、Input、Select、DatePicker、Pagination、table column 等组件,第一次需要读取,用来确认组件 ID 和基本用法。但读完之后,应该马上整理成最小组件映射。后续页面只引用这张映射,除非组件缺失或属性不明确,否则不要每做一页都重新展开完整组件库。
表格是最容易烧 token 的部分。尤其是 table column 组件,内部通常带有很多默认行和默认文本。只要深读完整子树,就会看到大量 header cell、content cell、text 节点。如果每一列都这样读,token 会消耗得很快。
更好的做法是,只深读一个代表性的 table column,确认表头文本和单元格文本的路径,后续复用这条路径,不逐列展开。同时,表格数据提前整理成结构化列数据。模型拿到的是列名和列数据,任务就会变成按结构填表,而不是从一堆 DOM 文本里临时判断。
验证环节也要窄。
验证当然要做,但不应该每次都重新读取整棵页面树。真正需要检查的是几个关键点:页面根节点是不是只有一个 PageFrame,sidepanel 是不是组件实例,Content 是不是普通 frame,Table 的直接子节点是不是 table column 实例,Pagination 是否存在,表格可见区域有没有露出默认占位文本。
只需要知道节点类型时,就不要展开完整样式。只需要验证表格结构时,就不要读取每个单元格。只有定位具体问题时,才短暂深读相关节点。
还有一些小噪音也要避开。比如本地 HTTP 服务和 Playwright 抓取页面时会产生大量访问日志,这些 GET 请求对页面重建几乎没有帮助。除非渲染失败需要排查,否则不要把服务日志带进对话。
最后是交接状态。
有些页面可能只能部分结构化重建,有些截图可能不是最后一次修正后的结果。这些情况必须写进 manifest。页面是 completed,还是 completed_with_limitations,截图是否为最终状态,哪些字段需要人工补全,都要明确记录。
这同样是在节省 token。因为开启一个新会话时,AI 不需要从很长的聊天记录里猜当前状态,只要读 manifest 就知道应该从哪里继续。
这套方案不是一键转换,它更像是把 Axure HTML 当成素材来源,再让 AI 按一套规则在 Ardot 里重建,所以不可能百分百还原。
有些页面本身就是截图型内容,HTML 里只有一张大图和少量覆盖层文字。这种页面 AI 很难还原成完整可编辑结构。能做的是先搭出页面框架,把能提取的字段提出来,然后标记为需要人工补全。
有些复杂表格也需要人工看一眼。尤其是宽表、合计行、跨列内容、异常布局,AI 可以根据规则生成一个基础版本,但不一定能完全符合真实业务页面。后面还是要手动调整列宽、内容、按钮位置。
还有一点是模型能力差异很明显。
在本次 Ardot MCP 迁移任务里,我测试过 Kimi k2.7 code 和 MiniMax-M3。即便已经有比较明确的规范、SOP 和检查清单,它们的执行效果仍然比较差。值得一提的是,GLM-5.2 的效果没有这两个模型好,我猜测可能是 Kimi 和 MiniMax 是多模态模型,因此在原型设计这类任务上理解能力更强,至少它们能根据截图来对比复现效果。
常见问题包括没有完整读取文档、没有严格复用组件、没有正确理解页面类型、缺少验证步骤、完成后不更新进度。有时它们看起来是在按要求做,但细看图层结构,还是会回到散节点堆页面的老问题。
我也把这次沉淀出来的规则整理成了一个 skill:
它不是一个一键转换工具,更像是一套给 agent 使用的工作规程,里面包括 HTML 渲染流程、页面类型规范、执行检查清单、常见失败模式,以及上面提到的上下文控制规则。
如果你也在尝试把 Axure HTML 原型迁移到 Ardot,可以参考这个 skill 的结构,按自己的组件库和页面规范改一版。
GitHub 地址:https://github.com/balabalabalading/ardot-html-prototype-converter
- https://docs.ardot.tencent.com/ai-features/h2d.html ↩
- https://apps.apple.com/cn/app/%E6%B5%81%E9%87%8F%E6%97%A5%E8%AE%B0/id6753135743?mt=12 ↩
登录查看剩余 70% 内容
相关文章
- REPLACED第九章全部收集品位置一览 07-02
- 轻漫岛app目录如何调正序 07-02
- 功夫熊猫神龙大侠新服何时开启 07-02
- 白银之城尔阁酒保 白银之城尔阁酒保角色背景与剧情解析 07-02
- 崩坏星穹铁道鼹鼠党宝藏任务怎么做 鼹鼠党宝藏任务流程分享 07-02
- 别再只接个 API 了!我用 EdgeOne Makers 手搓了一个懂业务的官网售前 AI 07-02