



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Together AI 推出 FlashAttention-4 及 ATLAS 加速器,推理速度提升 1.3-4 倍
时间:2026-05-31 08:36:01 编辑:袖梨 来源:一聚教程网
Together AI 日前正式推出FlashAttention-4及ATLAS加速I器,基于NVIDIA Blackwell架构的FlashAttention-4在推理性能上比cuDNN提升最高1.3倍,而ATLAS通过运行时学习机制实现最高4倍的LLM推理加速。这两项技术同步上线,意味着AI模型部署效率迎来一次实实在在的跃升。
FlashAttention-4:Blackwell上的速度革新
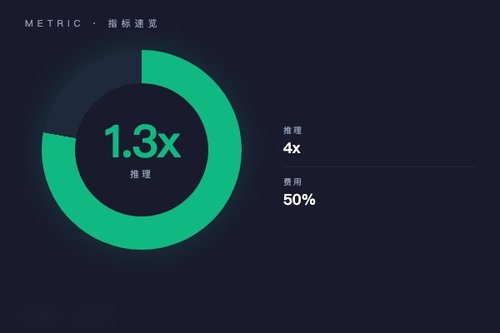
这套新版本的注意力机制算法专门针对NVIDIA Blackwell GPU做了优化。在同等硬件条件下,FlashAttention-4比cuDNN快出最多1.3倍,这对于处理长上下文的大语言模型来说很关键——想想看,每次推理节省一点时间,积累起来就是巨大的吞吐量提升。其实Together AI在GPU集群方面也有布局,他们的自服务NVIDIA GPU现已全面开放,这跟FlashAttention-4算是软硬结合的一套方案。
ATLAS加速I器:动态学习的推理引擎
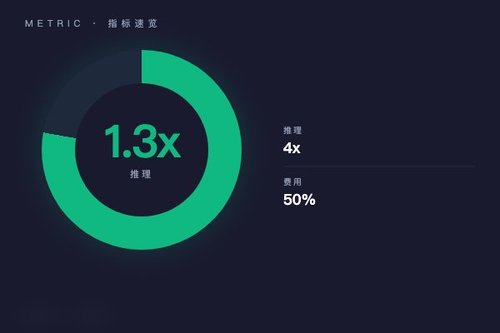
ATLAS这名字挺有意思,它代表运行时可学习的加速I器,能在推理过程中动态调整计算策略。官方数据显示,ATLAS能让LLM推理速度提升4倍,这可不是简单地缓存或量化能实现的——它凭什么做到?关键在于ATLAS能根据当前输入实时优化执行路径,相当于模型自己在运行时找到了更快的计算方式。不得不说,这种思路比起传统的静态优化方案要灵活得多。
Batch Inference API:大数据量场景的成本利器
在批量推理方面,Together AI推出了新的Batch Inference API,能够处理数十亿token数据。成本上更直接——大部分模型的推理费用降低了50%。这对于需要大量调用API的开发者来说确实是好消息,咱们做一次大规模数据处理,费用直接砍半,这就很实在了。难道这不比单纯追求单次推理速度更有吸引力吗?
Together GPU Clusters:自服务算力新选择
除了算法层面的更新,算力基础设施也有动作。Together GPU Clusters提供自服务式的NVIDIA GPU资源,这意味着开发者不用再通过繁琐的审批流程就能直接获取高性能算力。算是一种降低AI部署门槛的尝试——你手头有一个模型要跑推理,直接租用集群就行,没有中间商赚差价的感觉。
从FlashAttention-4到ATLAS再到Batch Inference API,Together AI这波更新覆盖了算法、推理引擎和基础设施三个层面。推理速度提升1.3到4倍的同时,成本也降了一半,算是一套完整的效率升级组合拳。如果你正在做LLM部署或者大规模推理任务,这些新东西确实值得关注起来。