



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
从 AWS 当机到 193 亿美元清算风暴,加密基础设施的「隐形炸弹」
时间:2025-10-22 08:40:09 编辑:袖梨 来源:一聚教程网
AWS 中断服务引发数十个加密平台瘫痪,揭露加密基础设施对中心化云服务的依赖成为系统性弱点。本文源自 YQ 所着文章,由Yuliya,PANews整理、编译及撰稿。
(前情提要:造市商 Wintermute 回顾「1011」加密史上最大清算日)
(背景补充:以太坊核心开发者Péter Szilágyi怒轰:ETH基金会薪酬不公、权力围绕Vitalik Buterin集中..)
本文目录
- 2025 年 10 月 10 至 11 日的清算瀑布
- 链下失灵:中心化交易所的架构问题
- 基础设施过载与速率限制
- 预言机操纵与定价漏洞
- 自动减仓(ADL)机制
- Solana:共识瓶颈
- 以太坊:Gas 费爆炸
- Layer 2:排序器瓶颈
- Polygon:共识版本不匹配
亚马逊云服务(AWS)于昨日(20)再次经历了一次重大中断,严重影响了加密货币基础设施。北京时间下午 16 点左右开始,AWS 位于 US-EAST-1 区域(北维吉尼亚数据中心)的问题导致了 Coinbase 以及包括 Robinhood、Infura、Base 和 Solana 在内的数十个主要加密平台的当机。
AWS 已经承认其核心资料库和计算服务——Amazon DynamoDB 和 EC2——出现了「错误率增加」的情况,而这正是成千上万家公司所依赖的服务。这次实时发生的中断,为本文的核心论点提供了直接而鲜明的印证:加密基础设施对中心化云服务提供商的依赖,创造了系统性的脆弱点,这些脆弱点在压力下会反复暴露出来。
这个时机极具警示意义。在价值 193 亿美元的清算瀑布暴露了交易所层面的基础设施失灵仅十天后,AWS 中断表明,问题已经从单个平台延伸到了基础的云基础设施层面。当 AWS 出现故障时,其连锁反应会同时冲击中心化交易所、去中心化「但仍依赖中心化组件」的平台,以及无数依附其上的服务。
这并非孤立事件,而是长期模式的延续。2025 年 4 月、2021 年 12 月以及 2017 年 3 月均发生过类似的 AWS 当机事件,每次都导致主流加密服务中断。问题已不在于「是否」会再次发生,而在于「何时」以及「由何触发」。
2025 年 10 月 10 至 11 日的清算瀑布
这场发生于 2025 年 10 月 10 日至 11 日的清算连锁事件,成为基础设施失效机制的典型案例。UTC 时间 10 月 10 日 20:00(北京时间 10 月 11 日 4:00),一项重大地缘政治公告引发市场普遍抛售。在短短一小时内,清算规模高达 60 亿美元。当亚洲市场开盘时,槓桿头寸的总体蒸发额已达 193 亿美元,波及 160 万名交易者帐户。
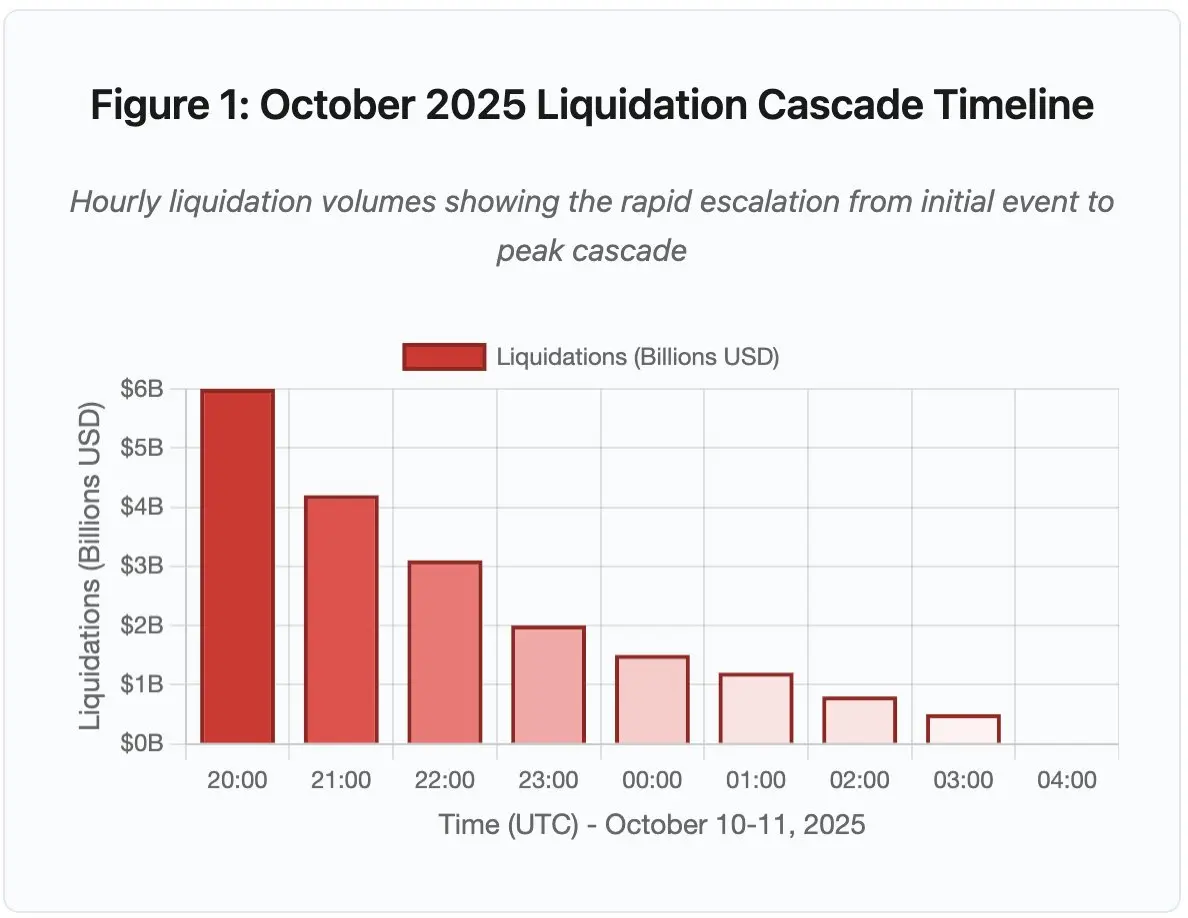
图 1:2025 年 10 月清算瀑布时间线(UTC 时间)
关键转折点包括 API 限速、做市商退出、订单簿流动性急剧下降。
- 20:00-21:00:初期冲击——清算 60 亿美元(红区)
- 21:00-22:00:清算高峰——42 亿美元,API 开始限流
- 22:00-04:00:持续恶化——91 亿美元,市场深度极度稀薄
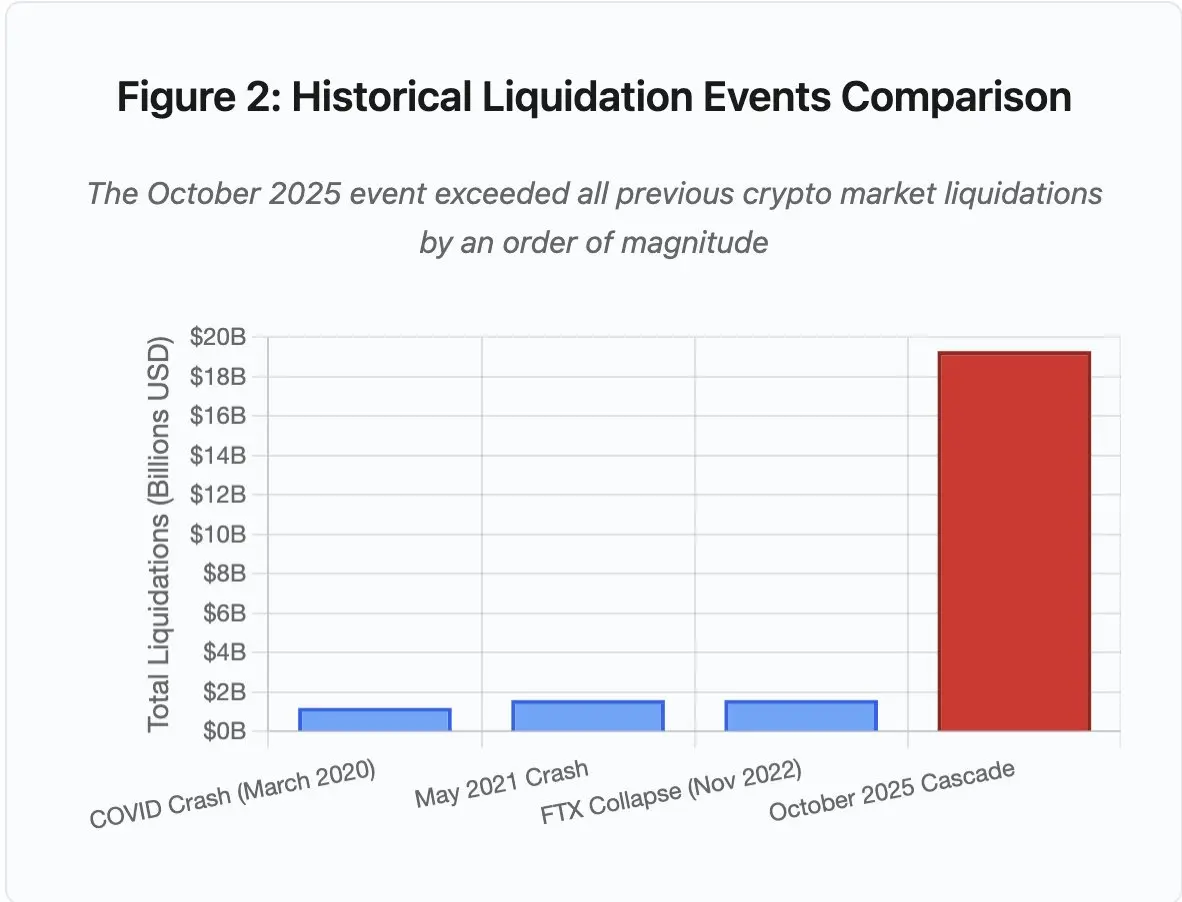
图 2:历史清算事件比较
此次事件的规模超越以往任何加密市场事件至少一个数量级。纵向比较可见这一事件的跳跃式特徵:
- 2020 年 3 月(疫情期间):12 亿美元
- 2021 年 5 月(市场暴跌):16 亿美元
- 2022 年 11 月(FTX 崩溃):16 亿美元
- 2025 年 10 月:193 亿美元,为此前纪录的 16 倍
然而,清算数据只是表象。更关键的问题在于机制层面:外部市场事件为何能触发如此特定的失效模式?答案揭示了中心化交易所架构与区块链协议设计中存在的系统性弱点。
链下失灵:中心化交易所的架构问题
基础设施过载与速率限制
交易所的 API 通常设有限速机制,用于防止滥用并维持伺服器负载稳定。在常规环境下,这种限制可阻止攻击并确保交易顺畅。然而在极端波动期间,当成千上万交易者同时尝试调整仓位时,这一机制反而成为瓶颈。
在此次清算期间,CEX(中心化交易所)将清算通知限速为每秒一单,而系统实际需处理数千单。结果,资讯透明度骤降,用户无法实时了解连锁清算的严重程度。第三方监控工具显示每分钟数百笔清算,而官方数据却少得多。
API 限速导致交易者在最关键的首小时内无法调整仓位。连接请求超时、下单失败、止损指令未能执行、仓位数据延迟更新——所有这些都将市场事件转化为操作性危机。
传统交易所通常为「常规负载+安全冗余」进行资源配置,但常规负载与极端负载之间差距极大。日均交易量不足以预测极端压力下的需求峰值。在连锁清算期间,交易量可激增 100 倍,仓位查询次数甚至飙升 1000 倍。每个用户同时检查帐户,令系统几近瘫痪。
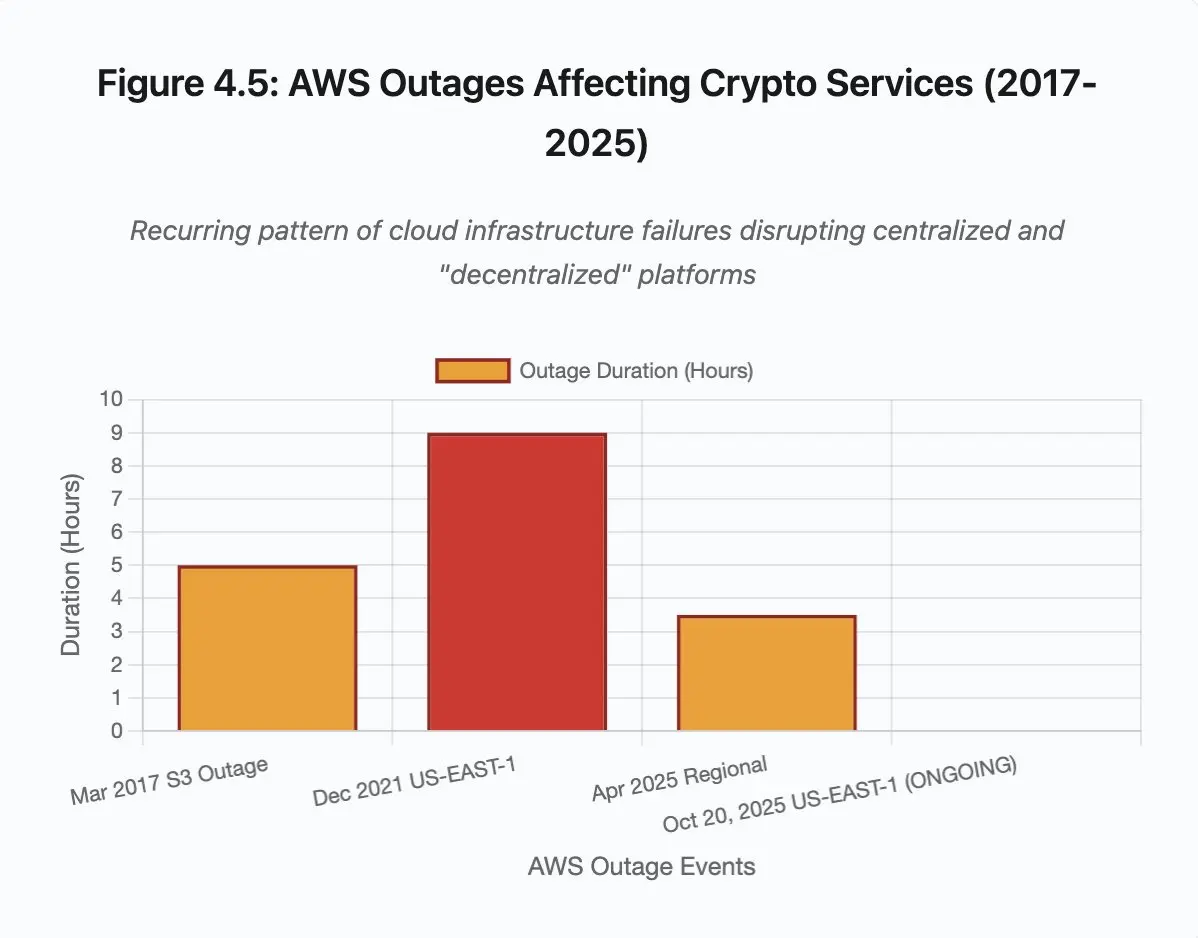
图 4.5:影响加密服务的 AWS 中断事件
云端基础设施的自动扩容虽有帮助,但无法即时响应。创建额外资料库副本需要几分钟,生成新的 API 网关实例同样需数分钟。而在这段时间内,保证金系统仍基于因订单簿拥堵而失真的价格数据对仓位进行结算标记。
预言机操纵与定价漏洞
在 10 月清算事件中,保证金系统的一个关键设计缺陷被暴露:部分交易所依据内部现货价格而非外部预言机价格来计算抵押品价值。在常规市场环境下,套利者能维持不同交易所间的价格一致性,但当基础设施承压时,这一联动机制失效。
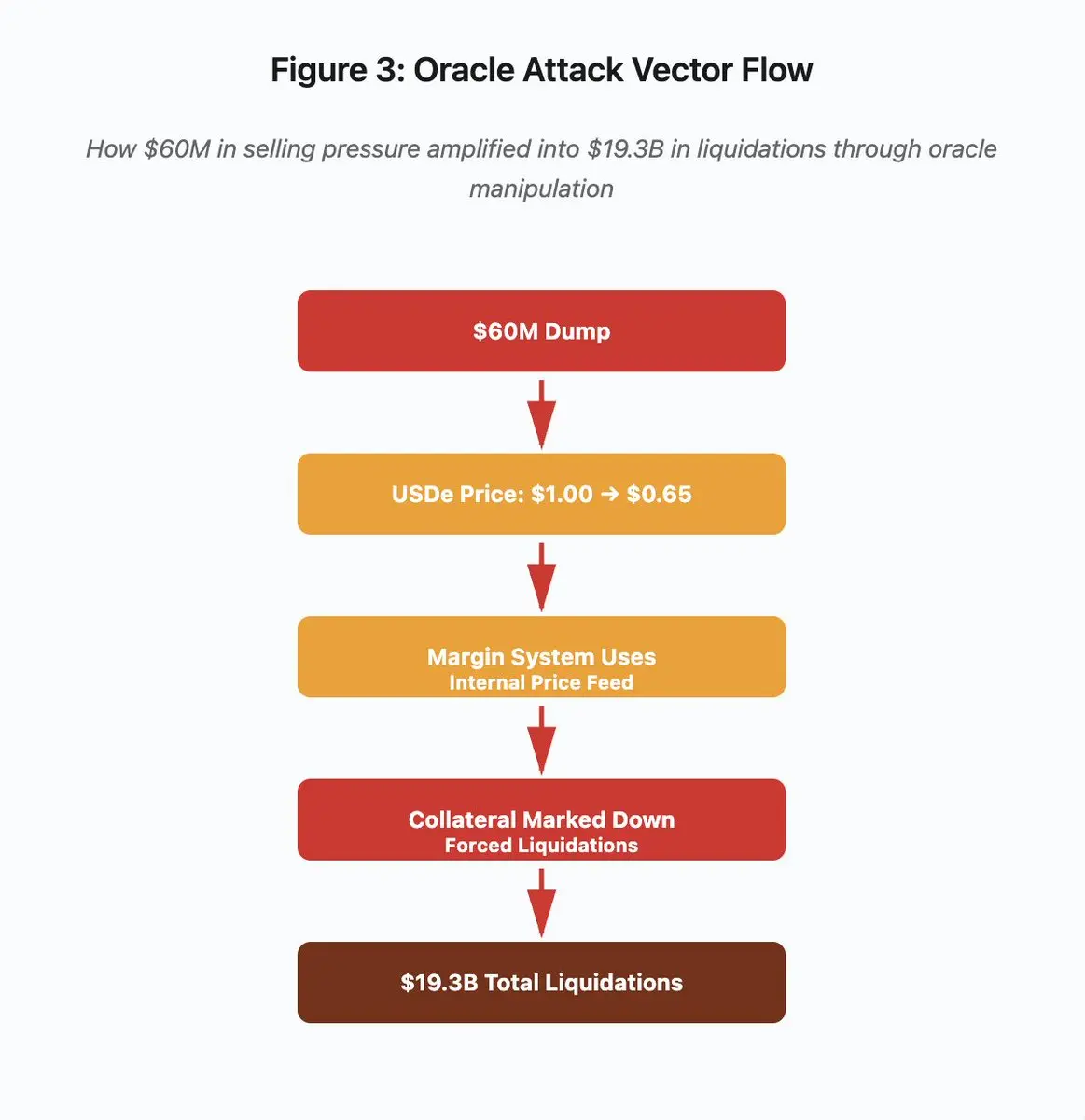
图 3:预言机操纵流程图
攻击路径可分为五个阶段:
- 初始抛售: 对 USDe 施加 6000 万美元的卖压
- 价格操纵: USDe 在单一交易所从 1.00 美元暴跌至 0.65 美元
- 预言机失灵: 保证金系统採用被篡改的内部价格
- 触发连锁:抵押品被低估,引发强制清算
- 放大效应: 总计 193 亿美元的清算(322 倍的放大)
这次攻击利用了币安使用现货市场价格来为封装的合成抵押品定价的机制。当一名攻击者将价值 6000 万美元的 USDe 抛售到流动性相对稀薄的订单簿中时,现货价格从 1.00 美元暴跌至 0.65 美元。被配置为按现货价格标记抵押品的保证金系统,将所有以 USDe 为抵押品的头寸价值下调了 35%。这引发了追加保证金通知和数千个帐户的强制清算。
这些清算迫使更多卖单进入同一个缺乏流动性的市场,进一步压低了价格。保证金系统观察到这些更低的价格,并减记了更多的头寸。这个反馈循环将 6000 万美元的卖压放大了 322 倍,最终导致了 193 亿美元的强制清算。

图 4:清算瀑布反馈循环
这个循环反馈图说明了瀑布的自我强化性质:
价格下跌 → 触发清算 → 强制卖出 → 价格进一步下跌 → [循环重複]
如果有一个设计合理的预言机系统,这种机制是行不通的。如果币安使用了跨多个交易所的时间加权平均价格(TWAP),那么瞬间的价格操纵就不会影响抵押品的估值。如果他们使用了来自 Chainlink 或其他多源预言机的聚合价格资讯,这次攻击也会失败。
几天前的 wBETH 事件亦暴露类似问题。Wrapped Binance ETH(wBETH)本应与 ETH 保持 1:1 的兑换率。但在瀑布期间,流动性枯竭,wBETH/ETH 的现货市场出现了 20% 的折价。保证金系统因此相应地减记了 wBETH 抵押品,触发了对那些实际上由底层 ETH 完全抵押的头寸的清算。
自动减仓(ADL)机制
当清算无法以当前市价执行时,交易所会实施自动减仓(ADL)机制,将损失在盈利的交易员中进行社会化分摊。ADL 会以当前价格强制平掉盈利的头寸,以弥补被清算头寸的亏空。
在 10 月的瀑布期间,币安在多个交易对上执行了 ADL。持有盈利多头头寸的交易员发现他们的交易被强制平仓,不是因为他们自身的风险管理失败,而是因为其他交易员的头寸变得资不抵债。
ADL 反映出中心化衍生品交易的底层架构选择:交易所保证自身不亏损,因而损失必然由以下几种方式承担:
- 保险基金(交易所为弥补清算亏空而预留的资本)
- ADL(强制盈利交易员平仓)
- 社会化损失(将损失分摊给所有用户)
保险基金规模相对于未平仓合约的比例决定了 ADL 的发生频率。2025 年 10 月,币安的保险基金总额约为 20 亿美元。相对于 BTC、ETH 和 BNB 永续合约 40 亿美元的未平仓合约,这提供了 50% 的覆盖。但在 10 月的瀑布期间,所有交易对的未平仓合约总额超过了 200 亿美元,保险基金无法覆盖亏空。
10 月瀑布事件后,币安宣布,当 BTC、ETH 和 BNB 的 U 本位永续合约总未平仓量低于 40 亿美元时,他们将保证不发生 ADL。这一政策虽提升信任,但也暴露了结构性矛盾:若交易所要完全避免 ADL,必须持有更大规模保险基金,而这会占用本可盈利运用的资金。
链上故障:区块链协议的局限性
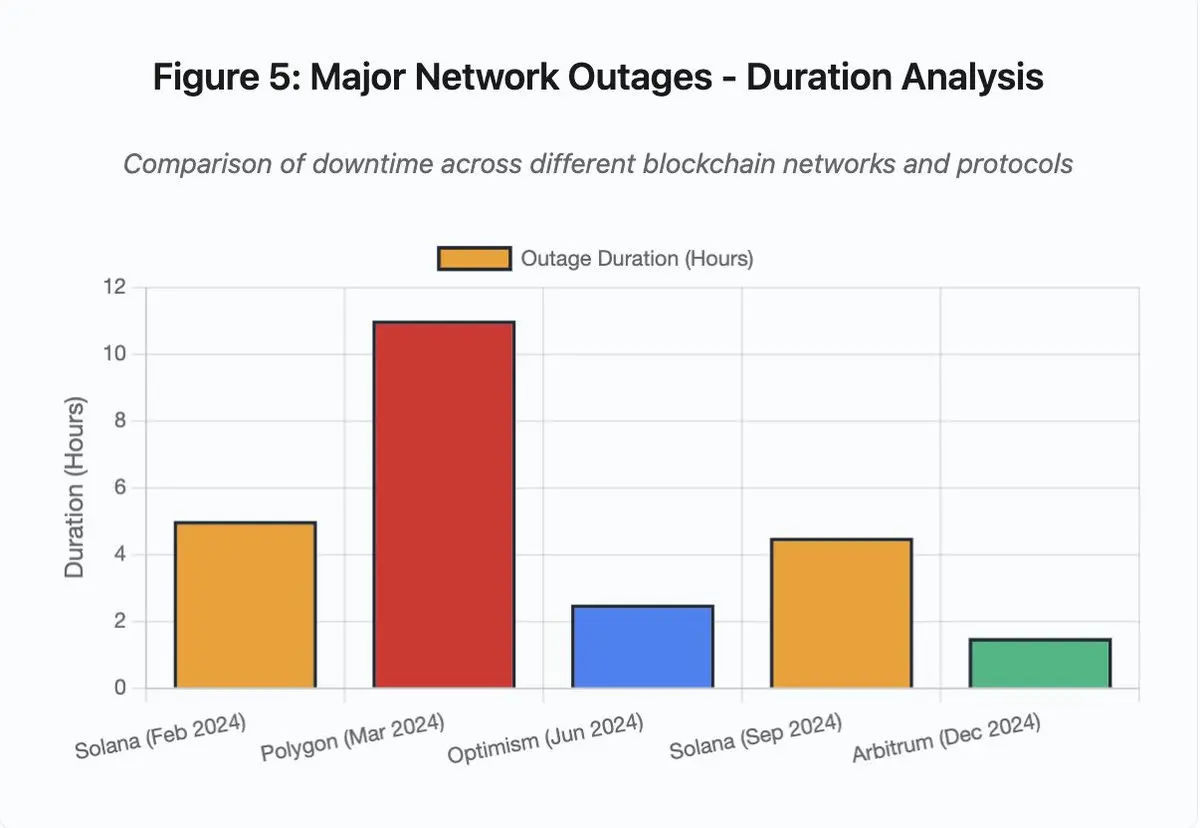
图 5:主要网路中断 – 持续时间分析
- Solana (2024 年 2 月): 5 小时 – 投票吞吐量瓶颈
- Polygon (2024 年 3 月): 11 小时 – 验证者版本不匹配
- Optimism (2024 年 6 月): 2.5 小时 – 排序器过载(空投)
- Solana (2024 年 9 月): 4.5 小时 – 垃圾交易攻击
- Arbitrum (2024 年 12 月): 1.5 小时 – RPC 提供商故障
Solana:共识瓶颈
Solana 在 2024-2025 年间经历了多次中断。2024 年 2 月的中断持续了约 5 小时,9 月的中断持续了 4-5 小时。这些中断源于相似的根本原因:网路在遭受垃圾交易攻击或极端活动时无法处理交易量。
Solana 的架构为高吞吐量进行了优化。在理想条件下,网路每秒可处理 3000-5000 笔交易,并实现亚秒级最终确定性。这一性能比以太坊高出几个数量级。但在压力事件中,这种优化反而製造了漏洞。
2024 年 9 月的中断是由大量的垃圾交易淹没了验证者的投票机制所致。Solana 的验证者必须对区块进行投票以达成共识。在正常操作中,验证者会优先处理投票交易以确保共识进程。但此前的协议在费用市场上将投票交易与常规交易同等对待。
当交易记忆池(mempool)被数百万笔垃圾交易填满时,验证者难以广播投票交易。没有足够的投票,区块就无法最终确定。没有最终确定的区块,链就停止出块。用户的待处理交易卡在记忆池中,新的交易也无法提交。
第三方监控工具 StatusGator 记录 Solana 在 2024-2025 年多起服务中断,而 Solana 官方并未发布正式说明。这造成资讯不对称,用户无法区分自身连接问题与网路整体问题。儘管第三方服务提供了监督,但平台自身应具备完善状态页面以建立透明度。
以太坊:Gas 费爆炸
以太坊在 2021 年 DeFi 热潮期间经历了极端 Gas 费飙升。简单转帐的交易费超过 100 美元,複杂智能合约互动甚至高达 500-1000 美元。这使网路对小额交易几近不可用,同时催生了另一种攻击媒介:MEV(最大可提取价值)提取。
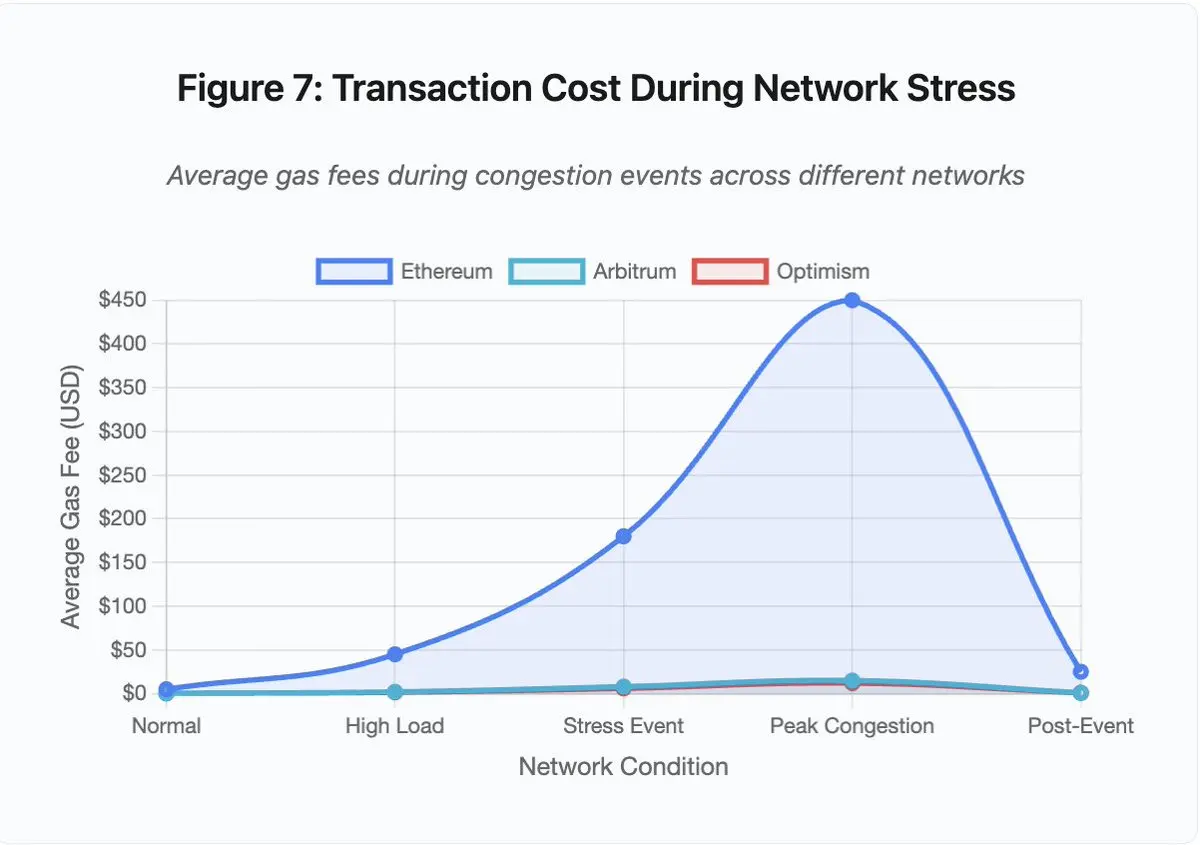
图 7:网路压力下的交易成本
- 以太坊: 5 美元 (正常) → 450 美元 (拥堵峰值) – 增长 90 倍
- Arbitrum: 0.50 美元 → 15 美元 – 增长 30 倍
- Optimism: 0.30 美元 → 12 美元 – 增长 40 倍
在高 Gas 费环境下,成为验证者的重要利润来源。MEV 指的是验证者通过重新排序、包含或排除交易来获取的额外收益。在这种情况下,套利者竞相抢跑大型 DEX 的交易,清算机器人则争相率先清算抵押不足的头寸。这种竞争导致 Gas 费竞价战加剧,即使是较低成本的 Layer 2 解决方案也会因高需求而出现显着的费用增长。高 Gas 费环境进一步放大了 MEV 的盈利机会,相关活动的频率和规模均有所提升。
在拥堵期间希望确保交易被打包的用户必须出价比 MEV 机器人更高。这就造成了交易费超过交易价值本身的情景。想领取你 100 美元的空投?请支付 150 美元的 Gas 费。需要添加抵押品以避免清算?请与支付 500 美元以获得优先权的机器人竞争。
以太坊的 Gas 限制代表每个区块可执行的计算总量。在拥堵期间,用户为稀缺的区块空间竞价。费用市场按设计运行:出价更高者优先。然而,这一设计使网路在使用高峰时期变得越发昂贵,而正是在用户最需要接入时。
Layer 2:排序器瓶颈
Layer 2 解决方案试图通过将计算移至链下,同时通过定期结算继承以太坊的安全性来解决这个问题。Optimism、Arbitrum 和其他 Rollups 在链下处理数千笔交易,然后将压缩后的证明提交给以太坊。这种架构在正常操作中成功降低了单笔交易的成本。
但 Layer 2 解决方案引入了新的瓶颈。2024 年 6 月,当 25 万个地址同时申领空投时,Optimism 经历了一次中断。负责在提交到以太坊之前对交易进行排序的组件——排序器——不堪重负。用户在几个小时内无法提交交易。
这次中断揭示了将计算移至链下并不能消除对基础设施的需求。排序器必须处理传入的交易,对其进行排序、执行,并为以太坊结算生成欺诈证明或零知识证明。在极端流量下,排序器面临着与独立区块链相同的扩展挑战。
必须有多个 RPC 提供商保持可用。如果主提供商失败,用户应能无缝切换到备用方案。在 Optimism 中断期间,一些 RPC 提供商仍在运行,而另一些则失败了。那些钱包默认设置为失败提供商的用户,即使链本身仍然存活,也无法与链进行互动。
AWS 当机反复揭示加密生态中的集中基础设施风险:
- 2025 年 10 月 20 日: US-EAST-1 区当机,影响 Coinbase、Venmo、Robinhood、Chime 等。AWS 承认 DynamoDB 与 EC2 服务错误率上升。
- 2025 年 4 月: 区域性当机影响币安、KuCoin、MEXC 等多家交易所同日中断。各大交易所 AWS 託管组件故障。
- 2021 年 12 月: US-EAST-1 中断导致 Coinbase、Binance.US 和「去中心化」交易所 dYdX 当机 8-9 小时,同时也影响了亚马逊自己的仓库和主流流媒体服务。
- 2017 年 3 月: S3(Simple Storage Service)中断导致用户在长达五小时内无法登入 Coinbase 和 GDAX,同时引发了广泛的网路中断。
这些交易所将关键组件託管在 AWS 基础设施上。当 AWS 经历区域性中断时,多个主要交易所和服务会同时变得不可用。在中断期间——恰恰是市场波动可能需要立即採取行动的时候——用户无法存取资金、执行交易或修改头寸。
Polygon:共识版本不匹配
Polygon 在 2024 年 3 月因验证器版本不一致问题发生了长达 11 小时的停机事故。这是主要区块链网路中分析的事故中最长的一次,凸显了共识失败的严重性。问题的根源在于部分验证器运行旧版本软体,而其他验证器已升级至新版本。由于两种版本对状态转换的计算方式不同,导致验证器对正确状态的结论不一致,从而引发共识失败。
链无法产生新区块,因为验证者无法就区块的有效性达成一致。这造成了一个僵局:运行旧软体的验证者拒绝来自新软体验证者的区块,而运行新软体的验证者也拒绝来自旧软体的区块。
解决方案需要协调验证者进行升级。但在中断期间协调升级需要时间。每个验证者运营商都必须被联繫上,必须部署正确的软体版本,并重启他们的验证者。在一个拥有数百个独立验证者的去中心化网路中,这种协调需要数小时甚至数天。
硬分叉通常使用区块高度作为触发器。所有验证者在特定的区块高度前完成升级,确保同时激活。但这需要提前协调。而增量升级,即验证者逐步採用新版本,则存在造成像 Polygon 中断那样的版本不匹配风险。
架构的权衡
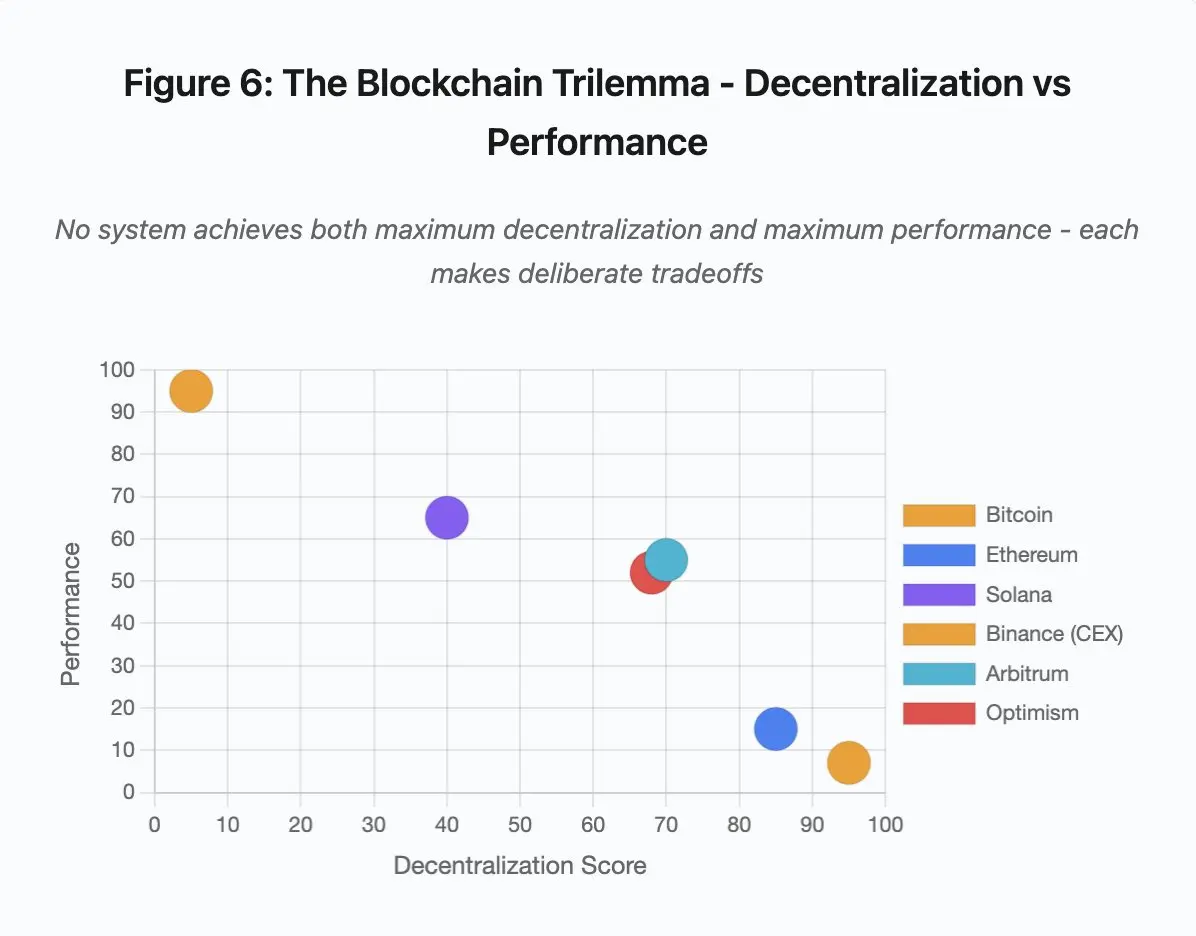
图 6:区块链三难困境 – 去中心化 vs. 性能
- 比特币: 高度去中心化,低性能
- 以太坊: 高度去中心化,中等性能
- Solana: 中等去中心化,高性能
- 币安 (CEX): 最低程度的去中心化,最高性能
- Arbitrum/Optimism: 中高程度去中心化,中等性能
核心洞见: 没有系统能同时实现最大程度的去中心化和最高性能。每种设计都为不同的用例做出了刻意的权衡。
中心化交易所通过架构的简单性实现低延迟。撮合引擎以微秒级处理订单,状态存在于中央资料库中,没有共识协议引入开销。但这种简单性也造成了单点故障。当基础设施承受压力时,级联故障会通过紧密耦合的系统传播。
去中心化协议将状态分布在验证者之间,消除了单点故障。高吞吐量链在中断期间也能保持这一特性(资金不会丢失,只是活性暂时受损)。但在分布式验证者之间达成共识会引入计算开销。在状态转换最终确定之前,验证者必须达成一致。当验证者运行不兼容的版本或面临压倒性的流量时,共识过程可能会暂时停止。
增加副本可以提高容错性,但会增加协调成本。在拜占庭容错系统中,每增加一个验证者都会增加通信开销。高吞吐量架构通过优化的验证者通信来最小化这种开销,从而实现卓越性能,但也使其对某些攻击模式变得脆弱。而注重安全的架构则优先考虑验证者的多样性和共识的稳健性,限制了基础层的吞吐量,同时最大化了弹性。
Layer 2 解决方案试图通过分层设计来同时提供这两种特性。它们通过 L1 结算继承以太坊的安全属性,同时通过链下计算提供高吞吐量。然而,它们在排序器和 RPC 层引入了新的瓶颈,表明架构的複杂性在解决一些问题的同时,也创造了新的故障模式。
扩展性仍是根本问题
这些事件揭示出一个反复出现的模式:区块链及交易系统在常规负载下运行良好,但在极端压力下往往出现崩溃。
- Solana 能有效处理日常流量,但在交易量增加 10000% 时崩溃了。
- 以太坊 的 Gas 费在 DeFi 应用普及前保持合理,但随后因拥堵大幅上涨。
- Optimism 的基础设施在正常情况下运行顺畅,但在 25 万地址同时领取空投时出现问题。
- 币安 的 API 在正常交易中功能正常,但在清算潮中因流量激增而受限。尤其是在 2025 年 10 月的事件中,币安的 API 速率限制和资料库连接在常规操作中足够,但清算潮中所有交易者同时调整仓位,导致这些限制成为瓶颈。此外,为保护交易所设计的强制平仓机制在危机时刻反而加剧了问题,迫使大量用户在最差时刻成为卖方。
自动扩容在面对突发性负载激增时显得不足,因为新增伺服器需要数分钟时间上线。在这期间,保证金系统可能基于流动性不足的订单簿生成错误的价格数据进行仓位标记。当新伺服器上线时,清算连锁反应已经扩散。
为应对罕见的压力事件而进行过度配置会增加日常运营成本,因此交易所通常优化系统以应对典型负载,并接受偶尔的失败作为一种经济上的合理选择。然而,这种选择将停机的成本转嫁给用户,造成用户在关键市场波动期间面临清算、交易卡顿或无法存取资金的问题。
基础设施的改进
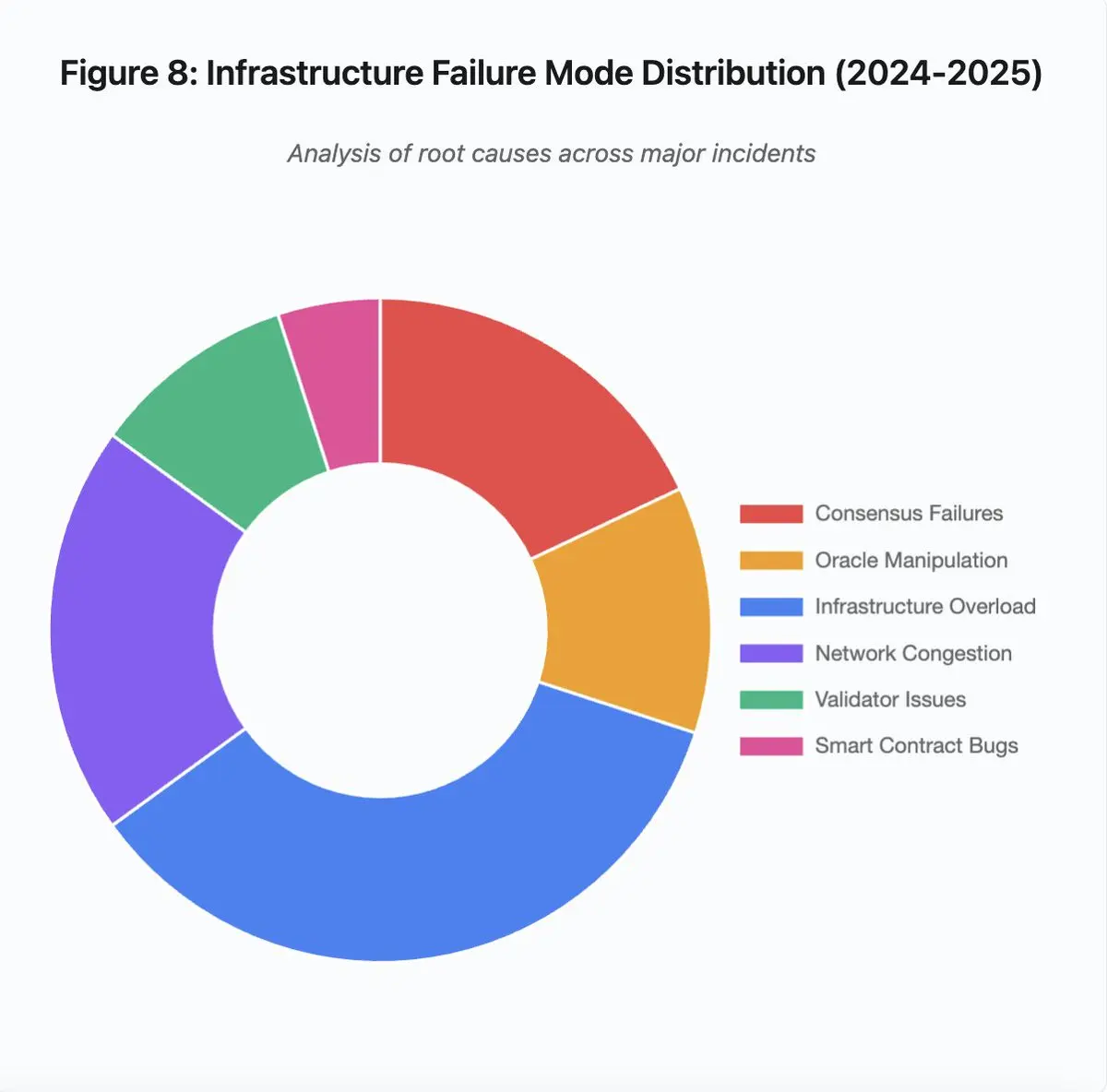
图 8:基础设施故障模式分布 (2024-2025)
2024-2025 年间基础设施故障的主要原因包括:
- 基础设施过载: 35% (最常见)
- 网路拥堵: 20%
- 共识失败: 18%
- 预言机操纵: 12%
- 验证者问题: 10%
- 智能合约漏洞: 5%
可採取若干架构改进以减少失败频率与严重程度,但每项均伴随权衡:
1.分离定价与清算系统
10 月事件部分起因在于将保证金结算绑定至现货市场价格。若使用封装资产兑换率而非现货价格,可避免 wBETH 估值失真。更广义地说,关键风险管理系统不应依赖可能被操纵的市场数据。採用独立预言系统、多源聚合、TWAP 计算可提供更可靠价格。
2.超额配置与冗余基础设施
2025 年 4 月影响币安、KuCoin 和 MEXC 的 AWS 中断事件,展示了集中的基础设施依赖风险。在多个云端提供商之间运行关键组件会增加运营複杂性和成本,但能消除相关性故障。Layer 2 网路可以维护多个具有自动故障切换功能的 RPC 提供商。在正常运营期间,额外的开销似乎是浪费,但在需求高峰期可以防止数小时的停机。
3.加强压力测试与容量规划
系统「运行良好直到失效」的模式表明压力测试不足。模拟 100 倍正常负载应成为标準做法。在开发中识别瓶颈比在实际中断中发现它们的成本要低得多。然而,真实的负载测试仍然具有挑战性。生产环境的流量表现出合成测试无法完全捕捉的模式。用户在真实崩盘期间的行为与测试期间不同。
前进之路
区块链系统在技术上取得了显着进步,但在应对压力测试时仍存在显着不足。当前系统依赖于传统业务时间设计的基础设施,而加密市场却是全球性、持续运行的,这导致在非正常工作时间发生压力事件时,团队需要紧急处理问题,而用户则可能面临巨大损失。传统市场在压力情况下会暂停交易,而加密市场只会熔断。这种情况究竟是系统特性还是缺陷,取决于不同角度和立场。
超额配置是解决问题的可靠方案,但与经济激励相冲突。维持超额容量的成本高昂,且仅为应对罕见事件。除非灾难性故障带来的成本足够高,否则行业可能不会主动採取措施。
监管压力可能成为改变的推动力,例如要求 99.9% 的正常运行时间或限制可接受的停机时间。然而,监管通常是在灾难发生后才出台,例如 Mt. Gox 在 2014 年倒闭后促使日本制定了加密货币交易所的正式监管政策。预计 2025 年 10 月的连锁反应将引发类似的监管回应,至于这些回应是规定结果(如最大可接受停机时间、清算期间的最大滑点),还是规定实施方式(如特定的预言机提供商、熔断器阈值),目前尚不确定。
行业需要在牛市中优先考虑系统的稳健性,而非增长。在市场繁荣时,停机问题往往被忽视,但下一轮週期的压力测试可能会暴露新的弱点。业界是会从 2025 年 10 月的事件中吸取教训,还是会重蹈覆辙,这仍然是一个悬而未决的问题。历史表明,行业通常通过数十亿美元的失败来发现关键漏洞,而非主动改进系统。区块链系统若要在压力下保持可靠性,需要从原型架构转向生产级基础设施,这不仅需要资金支持,还需要在开发速度与稳健性之间找到平衡。
相关文章
- 注册即送高达 100 USDT 奖励!加入币安,开启全球加密资产投资之旅! 06-09
- 下载币安APP,立享高达 100 USDT 新手奖励! 06-09
- uc浏览器网页版入口官网-手机/电脑uc浏览器网页版入口地址 05-26
- little fox官方网站入口地址-little fox网页版中国官网入口地址 05-26
- 樱花动漫网官网在线观看入口-樱花动漫网最新网页版入口地址2026 05-26
- 剑桥少儿英语官网入口网址-剑桥少儿英语网页版入口地址 05-26
- 手机百度网盘登录入口地址-百度网盘手机网页版登录入口地址 05-26
- 192.168.1.1无线路由怎么访问?192.168.1.1无线路由器设置登录入口地址 05-26