



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
python中文编码乱码问题解决方法
时间:2022-06-25 01:33:58 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下python中文编码乱码问题解决方法,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
一、什么是字符编码。
要彻底解决字符编码的问题就不能不去了解到底什么是字符编码。计算机从本质上来说只认识二进制中的0和1,可以说任何数据在计算机中实际的物理表现形式也就是0和1,如果你将硬盘拆开,你是看不到所谓的数字0和1的,你能看到的只是一块光滑闪亮的磁盘,如果你用足够大的放大镜你就能看到磁盘的表面有着无数的凹凸不平的元件,**凹下去的代表0,突出的代表1,**这就是计算机用来表现二进制的方式。
1.ASCII
现在我们面临了第一个问题:如何让人类语言,比如英文被计算机理解?我们以英文为例,英文中有英文字母(大小写)、标点符号、特殊符号。如果我们将这些字母与符号给予固定的编号,然后将这些编号转变为二进制,那么计算机明显就能够正确读取这些符号,同时通过这些编号,计算机也能够将二进制转化为编号对应的字符再显示给人类去阅读。由此产生了我们最熟知的ASCII码。ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。这样在大部分情况下,英文与二进制的转换就变得容易多了。
2.GB2312
然而,虽然计算机是美国人发明的,但是全世界的人都在使用计算机。现在出现了另一个问题:如何让中文被计算机理解?这下麻烦了,中文不像拉丁语系是由固定的字母排列组成的。ASCII 码显然没办法解决这个问题,为了解决这个问题中国国家标准总局1980年发布《信息交换用汉字编码字符集》提出了GB2312编码,用于解决汉字处理的问题。1995年又颁布了《汉字编码扩展规范》(GBK)。GBK与GB 2312—1980国家标准所对应的内码标准兼容,同时在字汇一级支持ISO/IEC10646—1和GB 13000—1的全部中、日、韩(CJK)汉字,共计20902字。这样我们就解决了计算机处理汉字的问题了。
3.Unicode
现在英文和中文问题被解决了,但新的问题又出现了。全球有那么多的国家不仅有英文、中文还有阿拉伯语、西班牙语、日语、韩语等等。难不成每种语言都做一种编码?基于这种情况一种新的编码诞生了:Unicode。Unicode又被称为统一码、万国码;它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode支持欧洲、非洲、中东、亚洲(包括统一标准的东亚象形汉字和韩国表音文字)。这样不管你使用的是英文或者中文,日语或者韩语,在Unicode编码中都有收录,且对应唯一的二进制编码。这样大家都开心了,只要大家都用Unicode编码,那就不存在这些转码的问题了,什么样的字符都能够解析了。
4.UTF-8
但是,由于Unicode收录了更多的字符,可想而知它的解析效率相比ASCII码和GB2312的速度要大大降低,而且由于Unicode通过增加一个高字节对ISO Latin-1字符集进行扩展,当这些高字节位为0时,低字节就是ISO Latin-1字符。对可以用ASCII表示的字符使用Unicode并不高效,因为Unicode比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。而我们最常用的UTF-8就是这些转换格式中的一种。在这里我们不去研究UTF-8到底是如何提高效率的,你只需要知道他们之间的关系即可。
总结:
1. 为了处理英文字符,产生了ASCII码。
2. 为了处理中文字符,产生了GB2312。
3. 为了处理各国字符,产生了Unicode。
4. 为了提高Unicode存储和传输性能,产生了UTF-8,它是Unicode的一种实现形式。
二、Python2中的字符编码
1.Python2中默认的字符编码是ASCII码,也就是说Python在处理数据时,只要数据没有指定它的编码类型,Python默认将其当做ASCII码来进行处理。这个问题最直接的表现在当我们编写的python文件中包含有中文字符时,在运行时会提示出错。如图:


这个问题出现的原因是:Python2会将整个python脚本中的内容当做ASCII码去处理,当脚本中出现了中文字符,比如这里的“小明”,我们知道ASCII码是不能够处理中文字符的,所以出现了这个错误。解决的办法是:在文件头部加入一行编码声明,如图:
# -*- coding: utf-8 -*-

这样,Python在处理这个脚本时,会用UTF-8的编码去处理整个脚本,就能够正确的解析中文字符了。
2. Python2中字符串有str和unicode两种类型。
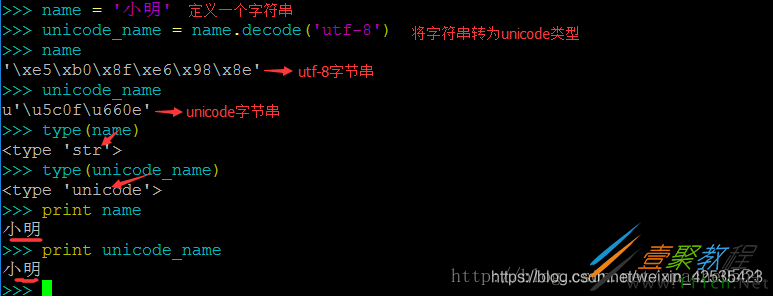
上图中展现出了Python2中字符串的两种类型:
name变量被赋予了一个字符串“小明”;
unicode_name是name变量的unicode格式,这里我们使用了decode()方法,我们会在后面的内容中详细讲解;
两者在终端中返回了不同的字节串,type返回了不同的数据类型,但print打印出了相同的输出。
这里我们注意到一个“字节串”的名称,字节串是指该字符串在python中的标准形式,也就是说无论一个字符串是什么样的编码,在python中都会有一串字节串来进行表示。字节串是没有编码的,对应的最终交给计算机处理的数据形式。
3. Python2中可以直接查看到unicode的字节串。
在上图中,输入unicode_name的返回值,是一个unicode字节串,我们能够直接看到这个字节串。而在python3中,我们将不能直接看到unicode字节串,它会被显示为中文的“小明”;因为python3默认使用unicode编码,unicode字节串将被直接处理为中文显示出来。
总结:
1. Python2中默认的字符编码是ASCII码。
2. Python2中字符串有str和unicode两种类型。str有各种编码的区别,unicode是没有编码的标准形式。
3. Python2中可以直接查看到unicode的字节串。
三、decode()与encode()方法
前面我们说了这么多都是为了这一节做铺垫,现在我们开始来处理Python2中的字符编码问题。我们首先要学习Python为我们提供的两个转换编码的方法decode()与encode()。
decode()方法将其他编码字符转化为Unicode编码字符。
encode()方法将Unicode编码字符转化为其他编码字符。
话不多说,直接上图:

chardet模块可以检测字符串编码,没有该模块的可以用pip install chardet安装。
首先解释一下为什么name=”小明” 这里的小明是一个utf-8编码的字符。因为我使用的是Ubuntu14.04操作系统,系统默认的字符编码就是UTF-8,所以当我在终端将一个中文输入时,系统就会自动将这个中文字符以UTF-8的编码传递给Python。所以如果你的系统是windows操作系统,而大多数情况下windows的系统编码默认是gb2312,那么在windows下做上图的测试“小明”这个字符就是gb2312编码。
上图中我们将utf-8编码的name通过decode()方法转换为unicode_name,然后通过encode()方法将unicode_name转换为gb2312_name。这时我们再用print去输出gb2312编码的字符时缺产生了一个奇怪的输出。这是因为我的操作系统使用的是UTF-8编码,对于gb2312编码的字符自然不能够正确解析,如果我们将该gb2312的字节串放在windows下输出就能够得到我们想要的中文,如图:

所谓乱码本质上是系统编码与所提供字符的编码不一致导致的,我们举一个例子:
小明的电脑中存了一个utf-8的字母A,存储在计算机中是1100001;
小红的电脑中也存了一个gb2312的字母A,存储在计算机中是11000010;
当小明与小红交换信息时,各自的计算机就不会把对方传递过来的A识别为字母A,可能认为这是字母B。
所以当我们需要操作系统正确的输出一个字符时,除了要知道该字符的字符编码,也要知道自己系统所使用的字符编码。如果系统使用的是UTF-8编码,处理的却是gb2312的字符就会出现所谓“乱码”。
一个Tips:decode()方法与在字符串前加u的方法实现的效果相同比如u'小明'

总结:
Python2的对于字符编码的转换要以unicode作为“中间人”进行转化。
知道自己系统的字符编码(Linux默认utf-8,Windows默认GB2312),对症下药。
四、一个字符编码的例子
在Linux操作系统下使用python2下获取网易首页的title,并以正确的中文显示出来

163的首页使用的字符编码是gb2312,而我们前面提到过Linux下的默认字符编码为UTF-8,我们测试一下直接提取会不会出现乱码问题。

我们发现确实提取到的title并不能正确显示,因为网页中已经声明了它是一个gb2312的字符编码,而我的系统中默认的字符编码为UTF-8显然,我必须要将title转换为UTF-8的字符。
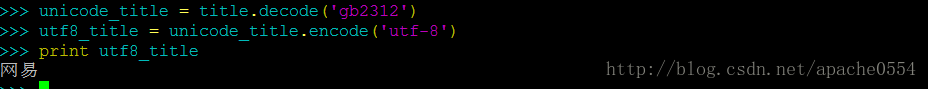
其实由于utf-8属于unicode字符编码,在Linux中我们可以直接打印出unicode编码的字符。如:

现在我们在Windows用Python2来做另一个实验,这次我们换成百度首页的title:
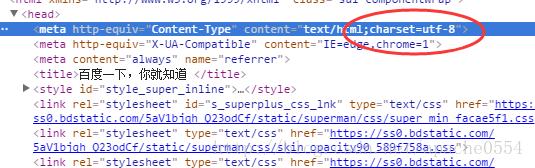
这次我们发现网页上的字符编码为utf-8,那么我在Windows下会不会出现乱码:
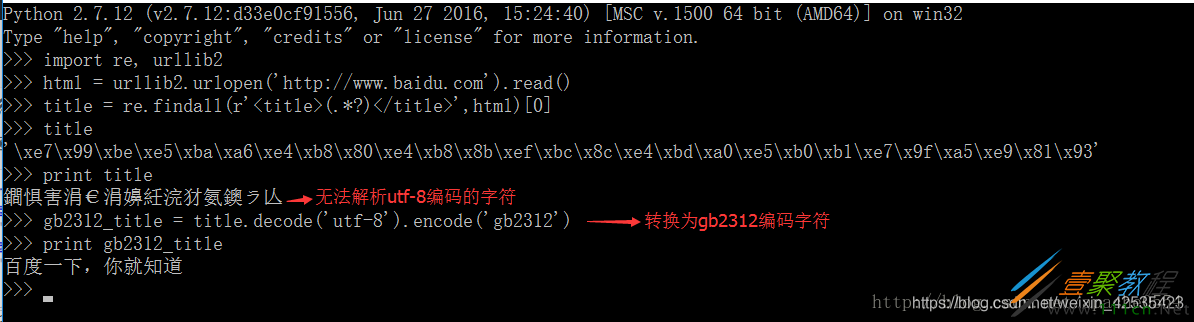
所以我们再次强调:乱码本质上是系统编码与所提供字符的编码不一致导致的
在Pyhon3中字符编码有了很大改善最主要的有以下几点:
Python 3的源码.py文件 的默认编码方式为UTF-8,所以在Python3中你可以不用在py脚本中写coding声明,并且系统传递给python的字符不再受系统默认编码的影响,统一为unicode编码。
将字符串和字节序列做了区别,字符串str是字符串标准形式与2.x中unicode类似,bytes类似2.x中的str有各种编码区别。bytes通过解码转化成str,str通过编码转化成bytes。
PS:有一个小问题被许多新手所困扰,我们来看一下图片
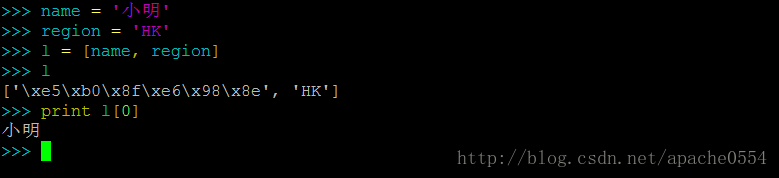
我们看到当一个中文字符出现在一个list(或tuple、dict)中时,它并不会被显示为一个中文而是字节串。但当该字符串从list中提取出来再print时就能够正常显示为中文。字节串是所有字符在python中的“本质”形态,所以你可以简单的理解为list中呈现出的字节串是给计算机看的。
相关文章
- 如鸢新活动游春集远房亲戚攻略 低配置无核爆通关攻略 08-03
- 燕云十六声免费外观攻略 最难拿到的三个免费套怎么拿 08-03
- 《弧光突袭者》 Arc Raiders “往昔药方”任务攻略 08-03
- 虚无世界宝宝技能搭配攻略(发掘宝宝技能的无限可能) 08-03
- 颠覆认知 曝PS6双机型定价悬殊 多数玩家恐难承受 08-03
- 《盾勇队长技能更换攻略》(优化战斗力,拓展战术选择,走上巅峰之路) 08-03