



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
语境腐烂 - 单次对话
时间:2026-07-05 11:19:05 编辑:袖梨 来源:一聚教程网

大模型的上下文腐烂(context rot)是指随着输入文本越来越长,其理解和推理性能反而逐渐下降。
简单来说,就是给模型的信息越多,它可能越糊涂,而不是越聪明。
像食物腐烂变质一样,是渐进式的,随着深度的增加而逐渐崩溃。
主要症状有:
核心指令遗忘中间迷失信息选择性失明逻辑断层前后矛盾幻觉激增复读机陷入死循环风格与人格偏移
举个例子
假设你向 AI 一次性输入了一份 20 万字的商业报告原文。
在提示词最开头,你写下严格指令:“请用表格形式输出总结,并务必提取出文中提及的财务造假证据。”
然而,AI的输出结果却是一大段普通的纯文本。
它不仅完全忘记了开头要求的表格格式。
而且虽然准确提炼了报告开篇的背景和末尾的结论,却对藏在文本数十万字中段的财务造假证据视而不见。
甚至按行业套路捏造了一个无关的常规风险来敷衍了事。
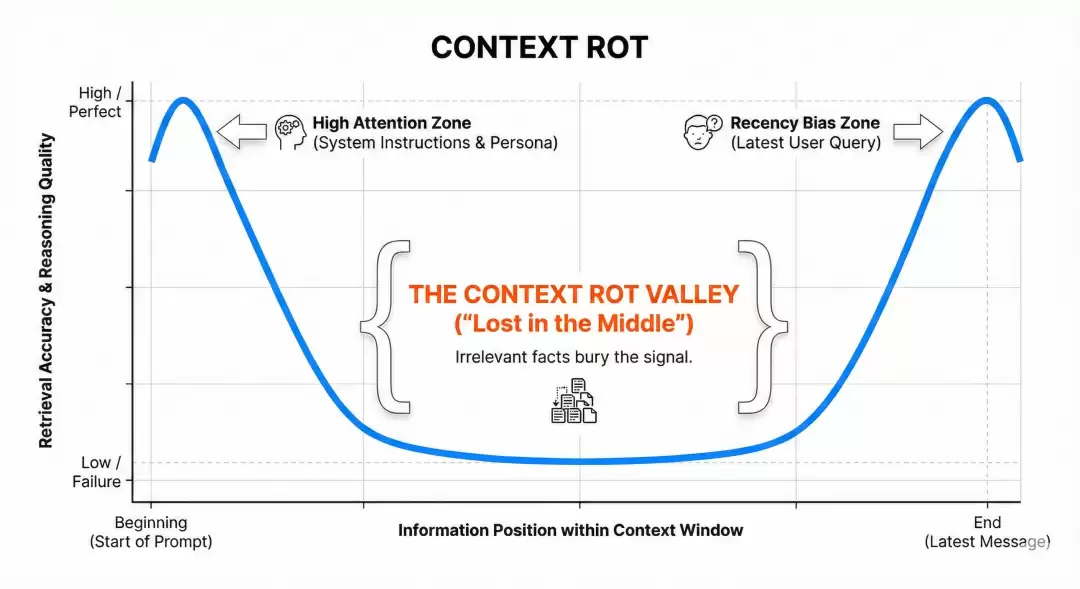
从这张图可以看出,单次输入中,大模型对不同位置信息处理能力的曲线呈现一个明显的U型。
左边开头部分质量高,中间核心位置最差,右边结尾又变好。
这种现象的数学本质是,位置偏置把权重抬到两端,softmax把差距指数放大,有限容量让中间首先被压缩掉。
上下文腐败是 Transformer 娘胎里带出来的,是由其数学形式直接决定。
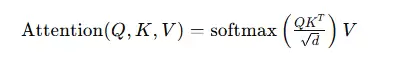
哪怕工程优化到极致,它也只会缓解,不会消失。

本质原因大致有三个:
原因1:Attention资源有限
Transformer 的注意力不是平均分配的。
前面有结构性权重,后面有时间性权重,中间啥都没有
模型倾向于认为开头是定义任务的,结尾是当前需要解决的问题,而中间的大段文本往往被视为背景噪音。
好比,你看一份很长的材料,然后回答问题。
因为要理解规则或背景,开头,你肯定看得很认真。
结尾,你也会认真看,因为要知道问什么。
精力有限,中间,可能就一扫而过了。

原因2:信号被噪声淹没
中间放的通常是长文档、RAG检索内容或历史对话等。
问题是,相关信息 ≠ 显著信息。
模型无法稳定判断中间部分,哪一句关键,哪一句是废话。
就好像,让你在100句话里找有用的那1句。
你不一定能一眼看出来哪句最重要。
模型的问题更严重。
模型不是理解后筛选,而是先算相似度,再决定看谁。
但是,关键句 ≠ 与问题最像的句子。
废话有时候说不定更像。
所以,模型不是找不到信息,而是分不清谁更重要。

原因3:压缩和总结机制带来的信息损失
长上下文会被模型隐式压缩,中间内容最容易被模糊化。
如同,你让一个人把100页内容记住,然后回答问题。
他不可能逐字记,一定会总结、抽象、忽略细节,特别是中间。
模型也是一样。
长上下文进入模型后,本质上会变成一个低维压缩表示。
在这个过程中细节会被丢掉、相似内容被混在一起,中间内容最容易被平均化,被压成一团分不清的东西。
本文参与腾讯云自媒体同步曝光计划,分享自微信公众号。原始发表:2026-03-25,如有侵权请联系[email protected] 删除相关文章
- 宠物三合一躺平到五星2026可用礼包码清单 07-05
- 王者荣耀世界中东方曜如何配队 07-05
- 口袋妖怪无限融合结缘岛可学技能及条件 07-05
- 伯吉的温馨厨房顾客的酱料如何选择 07-05
- 罗布变身模拟器必杀技怎么释放 07-05
- 夜幕之下无光之阶EX10层过关搭配 07-05