



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
03-SingleController一个大脑如何调配一群GPU工人
时间:2026-07-02 11:51:54 编辑:袖梨 来源:一聚教程网
Single Controller:一行 Python 调用如何变成多 GPU RPC
上一篇我们把 RLHF 看成一条高层 Dataflow:rollout 生成样本,reward/ref/value/advantage 补齐训练信号,actor/critic 再更新权重。这篇回答下一层问题:如果 PPO 主循环看起来像普通 Python 代码,verl 到底怎样把其中一行 actor_rollout_wg.compute_log_prob(batch_td)变成多 GPU worker 上的远程调用?
本文的核心判断是:verl 的 single controller 不是把训练“单机化”,而是把阶段顺序留在一个 controller 进程里,把实际计算交给 WorkerGroup 袋里的远端 worker。它的关键接口不是 Ray 本身,而是 worker 方法上的 @register:这里声明输入如何分发、远端方法如何执行、输出如何收回。
读这篇时可以先抓住一条主线:
代码语言:javascript复制TaskRunner 装配角色和资源-> RayPPOTrainer.init_workers() 创建 WorkerGroup-> worker 方法用 @register 声明分布式调用契约-> WorkerGroup 动态绑定同名袋里方法-> PPO 主循环像本地调用一样驱动远端 worker
这张图先给出本文的源码阅读地图。重点不是记住所有类名,而是看清:PPO 主循环、WorkerGroup 袋里、@register契约、Ray actor 执行分别站在哪一层。
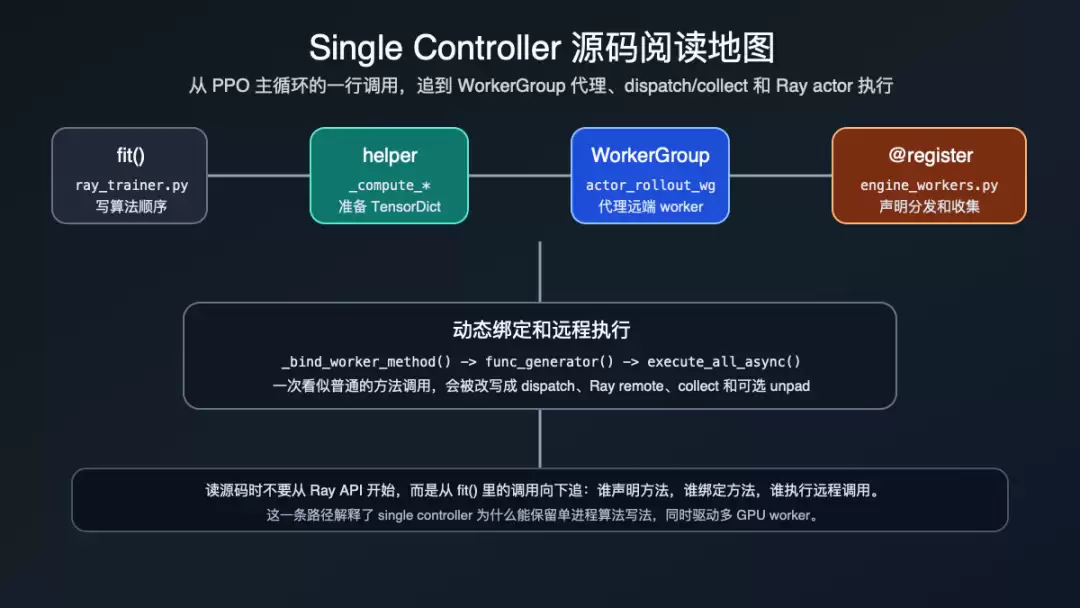
Single Controller 源码阅读地图
这条路径解释了后面的所有现象:fit()里看到的是一行普通方法调用;WorkerGroup 里看到的是 dispatch、remote execute、collect;worker 类里看到的是某个具体引擎的推理或训练逻辑。不要从 Ray API 入口开始读,要从 fit()里那一行调用往下追。
1. 它为什么不是普通 DDP
普通 DDP 的心智模型是:多张卡执行同一段训练循环,只是在梯度同步时通信。RLHF 不完全适合这种模型,因为一次 PPO step 不是单纯的 forward/backward/step,而是阶段化的系统流程:生成、奖励、重算 logprob、reference/value、优势估计、actor/critic update、权重同步,且不同阶段可能使用不同角色和不同资源。
verl 文档直接说明,RayPPOTrainer.fit()是单进程运行的 PPO 主循环,WorkerGroup 作为 controller 进程访问远端 workers 的袋里;worker 方法需要绑定到 WorkerGroup,并定义数据分发和收集方式(docs/hybrid_flow.rst:107-117)。源码里也能看到这一点:fit()在一个 Python 循环中串起 rollout、reward、old logprob、ref logprob、values、advantage、critic update、actor update 和 weights update(verl/trainer/ppo/ray_trainer.py:1274-1583)。
下面这张图要看的不是“哪边更高级”,而是控制流放在哪里:DDP 复制训练循环;single controller 只复制计算 worker,不复制 PPO 阶段编排。
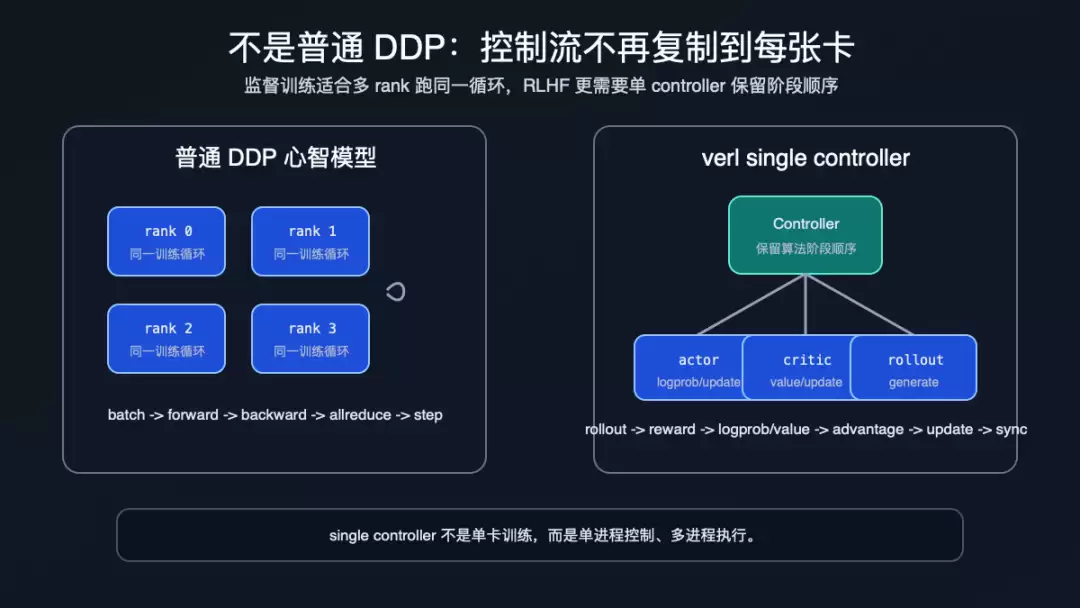
DDP 和 Single Controller 的控制流差异
所以 single controller 的价值不是“少写分布式代码”这么简单。更准确地说,它把 RLHF 的系统状态放在一个地方:哪些数据已经生成、哪些信号已经补齐、什么时候更新 actor、什么时候把权重同步给 rollout,都由 controller 串起来。GPU worker 只负责执行被分派过去的计算。
2. 先摆角色和资源,再进入 PPO 主循环
真正进入 fit()之前,verl 先完成两件事:角色映射和资源映射。
TaskRunner在 main_ppo.py中建立 role_worker_mapping和 mapping。例如 actor/rollout/ref 角色会映射到 Ray remote worker class,并放到 "global_pool";critic 会映射到 TrainingWorker;resource pool spec 则按节点数和每节点 GPU 数构造(verl/trainer/main_ppo.py:118-186)。随后 TaskRunner.run()创建 tokenizer、dataset、ResourcePoolManager,再把这些交给 RayPPOTrainer,最后调用 trainer.init_workers()和 trainer.fit()(verl/trainer/main_ppo.py:219-311)。
RayPPOTrainer.init_workers()继续把抽象角色落到可调用的 WorkerGroup:先创建 resource pool,再把 actor/critic/ref 等角色包装成带初始化参数的 Ray class,必要时用 create_colocated_worker_cls()合并到同一个 Ray actor 类,最后 spawn()出按角色命名的 WorkerGroup(verl/trainer/ppo/ray_trainer.py:688-807)。
这张生命周期图要看的重点是:PPO 主循环并不知道每个角色如何 colocate、占几张卡、落在哪个 pool;这些都在进入主循环前被 WorkerGroup 封装掉了。
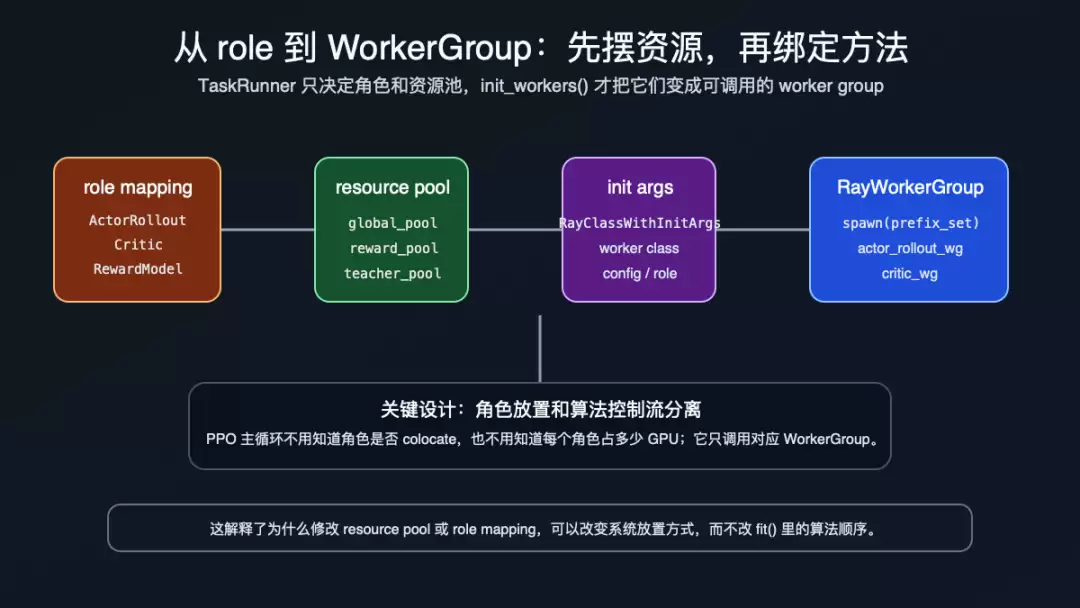
从 role 到 WorkerGroup 的生命周期
这就是 HybridFlow 文档所说的灵活放置:改变 WorkerGroup 和 ResourcePool 的 mapping,可以调整资源部署,而不必改 controller 里的控制流程(docs/hybrid_flow.rst:206)。后面文章会继续拆 ResourcePool/WorkerGroup;本文只需要记住,它们是 single controller 可以“像本地对象一样调用远端角色”的前置装配层。
3. @register才是一行调用的契约
WorkerGroup 为什么会突然拥有 compute_log_prob()、update_actor()这类方法?答案不在 RayPPOTrainer,而在 worker 方法的 @register。
以 ActorRolloutRefWorker为例,compute_log_prob()和 update_actor()都用 @register(dispatch_mode=make_nd_compute_dataproto_dispatch_fn(mesh_name="actor"))标记;reference logprob 则使用 mesh_name="ref"(verl/workers/engine_workers.py:631-650)。TrainingWorker里的 train_mini_batch()、train_batch()、infer_batch()也用同一类分发函数声明 train mesh 上的计算(verl/workers/engine_workers.py:238-385)。
register()本身不直接发起远程调用。它做的是把 dispatch_mode、execute_mode、blocking挂到函数的 MAGIC_ATTR上(verl/single_controller/base/decorator.py:398-444)。真正消费这些元信息的是 WorkerGroup._bind_worker_method():它扫描 worker class 上带 MAGIC_ATTR的方法,解析 dispatch/collect 函数和 execute 函数,再用 func_generator()生成 controller 侧的同名袋里方法,最后 setattr(self, method_name, func)绑定到 WorkerGroup 实例上(verl/single_controller/base/worker_group.py:185-255)。
下面这张图补上“声明”和“绑定”之间的缺口。看图时可以把 @register理解成 worker 方法贴给 controller 的调用说明书。
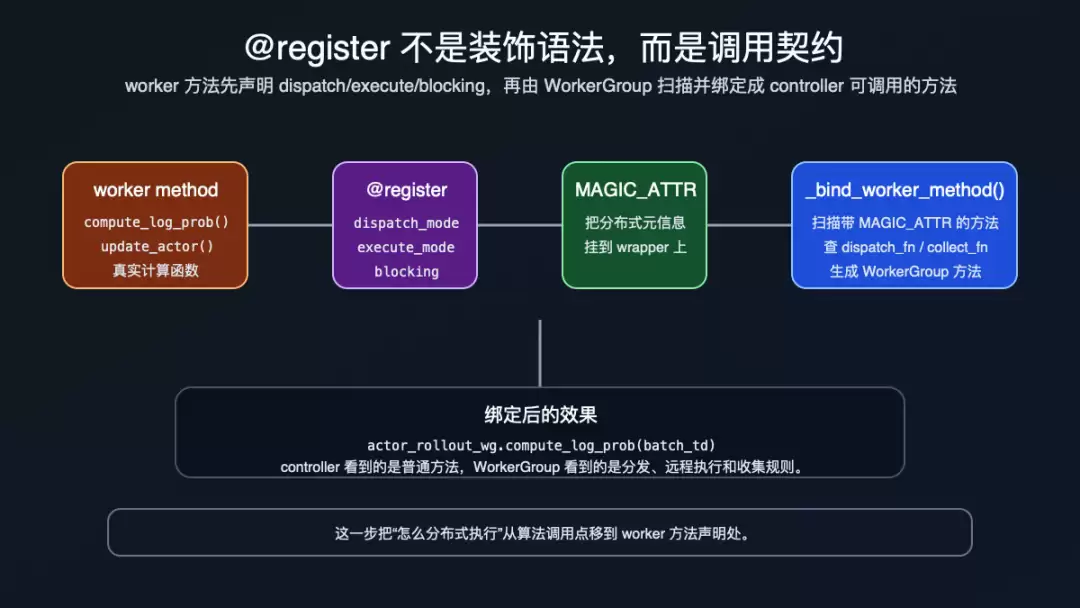
register 和 WorkerGroup 动态绑定契约
这解释了一个容易误解的点:actor_rollout_wg.compute_log_prob()不是手写在 RayPPOTrainer里的普通方法,也不是 Ray 自动生成的单 actor RPC。它是 WorkerGroup 根据 worker class 上的 @register元信息动态生成出来的多 worker 袋里方法。
4. 以 compute_log_prob追一次完整调用
现在回到 PPO 主循环中的一行调用。
RayPPOTrainer._compute_old_log_prob()先把 DataProto转成 TensorDict,做 no-padding 转换,塞入 calculate_entropy、compute_loss=False等非 tensor 元信息,然后调用 self.actor_rollout_wg.compute_log_prob(batch_td)。结果回来后,它再取出 entropy/log_probs,转回 padding 形态,重新封装成 DataProto(verl/trainer/ppo/ray_trainer.py:1168-1203)。
这里 helper 做的是数据语义适配;远程执行语义由 WorkerGroup 接管。func_generator()生成的袋里方法会按固定顺序工作:先 dispatch_fn切输入,再 execute_fn发远程调用;如果是 blocking 模式就 ray.get();之后 collect_fn合并输出,并处理 auto padding 产生的额外样本(verl/single_controller/ray/base.py:48-66)。在 Ray backend 下,execute_all_async()会把参数列表逐个切给对应 worker,再调用 Ray actor 的 remote method(verl/single_controller/ray/base.py:864-892)。
这张调用路径图把 helper、WorkerGroup、Ray actor 分开看。它回答的是“一行 Python 为什么没有停在本地”。

一行 WorkerGroup 调用的真实路径
这条链路也解释了为什么 verl 的 PPO 主循环可读:主循环只写阶段顺序,helper 只处理当前阶段需要的 TensorDict/DataProto 形态,分布式细节被压到 WorkerGroup 的 dispatch/execute/collect 中。
5. dispatch/collect 带来灵活性,也留下中心化边界
single controller 的灵活性来自 dispatch/collect,而不是来自某个神奇的 Ray 调用。
最简单的 ONE_TO_ALL会把同一份参数复制给所有 worker;DP_COMPUTE_PROTO会把 DataProto 按 worker 数切开并在 collect 时拼回;当前训练 worker 常用的 make_nd_compute_dataproto_dispatch_fn(mesh_name=...)会先查询 worker group 的 DP rank mapping,再按 mesh 的 DP 维度做分发和收集(verl/single_controller/base/decorator.py:120-199,verl/single_controller/base/decorator.py:202-345)。RayPPOTrainer._balance_batch()还会从 WorkerGroup 查询 dispatch info,拿到实际 DP size 后按有效 token 数重排 batch,以降低不同 DP rank 的负载差异(verl/trainer/ppo/ray_trainer.py:1040-1078)。
下面这张图要看的不是“哪里慢”,而是边界:controller 必须知道如何切、如何收、哪里需要 padding/unpadding,才能让 PPO 主循环继续拿到完整的 DataProto。
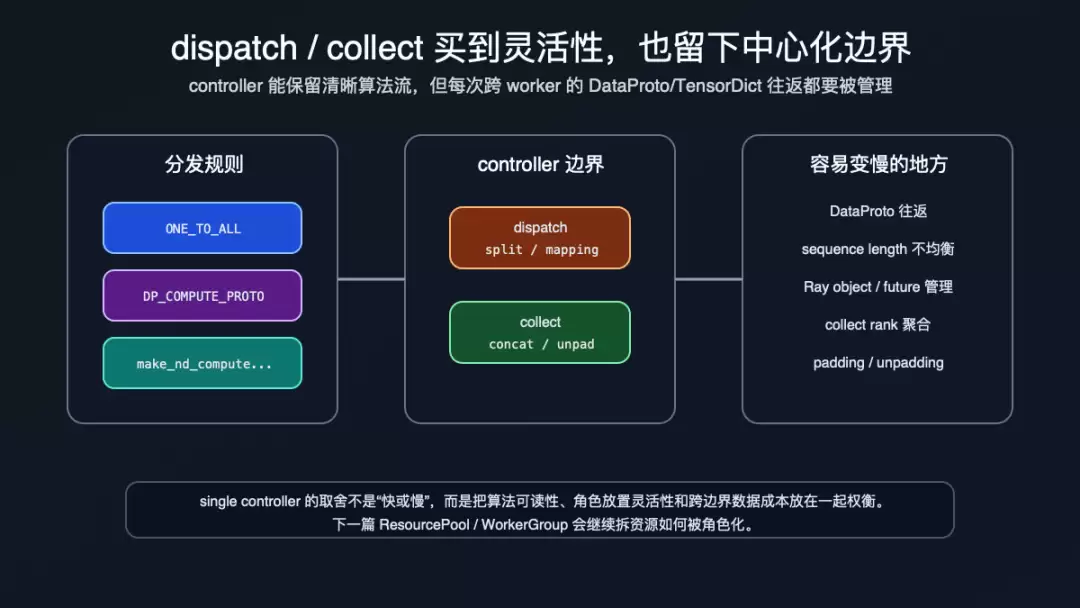
dispatch collect 的灵活性和边界
这也是 single controller 的代价:控制流集中以后,调试和阶段编排更清楚,但数据分发、Ray object/future、collect 聚合、padding 处理也都会经过这个抽象边界。换句话说,它把系统复杂度从“每个 worker 都懂 PPO 全流程”,转移成“controller 懂阶段顺序,WorkerGroup 懂分布式调用契约”。
小结:controller 是系统大脑,不是计算瓶颈的全部答案
到这里,第二篇和第三篇可以连起来看:
代码语言:javascript复制02 Dataflow:RLHF 的 batch 在哪些阶段之间流动03 Controller:这些阶段为什么能写成单进程 Python 顺序
verl 的 single controller 把 PPO 训练写成一条可读的主流程,但它没有消灭分布式复杂度。复杂度被重新分层了:TaskRunner负责角色和资源,RayPPOTrainer负责阶段顺序,@register负责声明分发/收集契约,WorkerGroup 负责把本地方法调用变成多 worker RPC。
这篇解决的是“一个大脑如何调度一群 GPU 工人”。下一篇应该继续往下看:这些工人怎样被放进 ResourcePool,WorkerGroup 怎样管理进程、rank、colocation,以及为什么资源布局会影响 rollout、训练和权重同步的效率。
本文源码索引
docs/hybrid_flow.rst:107-120:single-process fit()、WorkerGroup 袋里、ActorRolloutRef colocate 说明。docs/hybrid_flow.rst:170-177:worker 方法用 register声明输入分发和输出收集。docs/hybrid_flow.rst:206:改变 WorkerGroup/ResourcePool mapping 可调整放置方式。verl/trainer/main_ppo.py:118-186:TaskRunner建立 role 到 worker class、resource pool 的映射。verl/trainer/main_ppo.py:219-311:创建 trainer,调用 init_workers()和 fit()。verl/trainer/ppo/ray_trainer.py:688-807:创建 resource pool、role class、colocated worker class 和 WorkerGroup。verl/trainer/ppo/ray_trainer.py:1168-1203:_compute_old_log_prob()中的一行 actor_rollout_wg.compute_log_prob()。verl/trainer/ppo/ray_trainer.py:1274-1583:PPO 主循环的阶段顺序。verl/single_controller/base/decorator.py:398-444:@register如何挂载分布式调用元信息。verl/single_controller/base/worker_group.py:185-255:WorkerGroup 如何扫描并绑定 worker 方法。verl/single_controller/ray/base.py:48-66:袋里方法的 dispatch、execute、collect 顺序。verl/single_controller/ray/base.py:864-892:RayWorkerGroup 如何调用所有远端 worker。verl/workers/engine_workers.py:631-650:actor/ref worker 的 logprob 和 update 方法注册。本文参与腾讯云自媒体同步曝光计划,分享自微信公众号。原始发表:2026-06-18,如有侵权请联系[email protected] 删除
相关文章
- 光遇7月1日季节蜡烛位置指南 07-02
- 7月1日光遇每日任务攻略 07-02
- 疯狂保卫战43关通关攻略:疯狂保卫战43关详细打法与通关技巧 07-02
- 梦之形手机版阿鬼的残骸详解:梦之形手机版阿鬼残骸获取方法与作用解析 07-02
- 小森生活高山松茸采集位置一览 07-02
- 刀剑神域火线争战即将重启服务 推出新宣传影片与制作人讯息视讯 07-02