



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
阿里达摩院开源语音识别:比Whisper快170倍还免费,CPU就能跑
时间:2026-07-01 08:47:00 编辑:袖梨 来源:一聚教程网
语音识别新选择:阿里达摩院开源FunASR,比Whisper快170倍,CPU即可流畅运行,彻底告别转录烦恼。核心内容:1. FunASR的核心优势:极速、免费、易部署,内置说话人分离等实用功能。2. 与Whisper的性能对比:在GPU和CPU上均实现数量级的速度超越。3. 快速上手指南与未来应用展望,降低技术使用门槛。
开会两小时,整理录音一整天。这是不是你的日常?(如果你使用了会议自动记录或者会议整理skill当我没说,后续本公众号会开放会议总结skill,超好用!!!)
记会议、扒播客、剪视频字幕——最烦的就是转录。Whisper 是能转,但慢,还分不清谁在说话;云服务倒是准,可每分钟都在计费。开源社区等一个"快、准、免费、能自己部署"的方案,等太久了。

现在有了。
阿里达摩院 ModelScope 团队的 FunASR,一个开源语音识别工具包——GPU 上跑到 170 倍实时速度,CPU 上 17 倍,比 Whisper 用 GPU 还快。带说话人分离、自动标点、情绪识别,全部内置,GitHub 已经 18K star。
更关键的是:一句代码,全搞定。
"以前自己搭一套语音识别,GPU 服务器是门槛。现在?一台笔记本,CPU 就够了。"

这东西到底是什么来头?
FunASR 的全称是 A Fundamental End-to-End Speech Recognition Toolkit,阿里达摩院语音团队做的,2023 年发在语音顶会 INTERSPEECH 上。但真正让它出圈的是 2024-2025 年的一系列更新——SenseVoice 模型上线、31 语言支持、vLLM 推理加速、OpenAI 兼容 API,再到最近的 MCP Server 集成,一步比一步实用。
它本质上是一套"模型 + 工具链":你给它音频,它给你带说话人标签、时间戳、标点和情绪的文本。不需要先切句、不需要单独跑 VAD、不需要另外装说话人分离工具。
和 Whisper 比,差了多少?
关键结论:FunASR 用 CPU 跑,比 Whisper 用 GPU 还快。
官方 benchmark 跑了 184 个长音频,总共 192 分钟的材料:
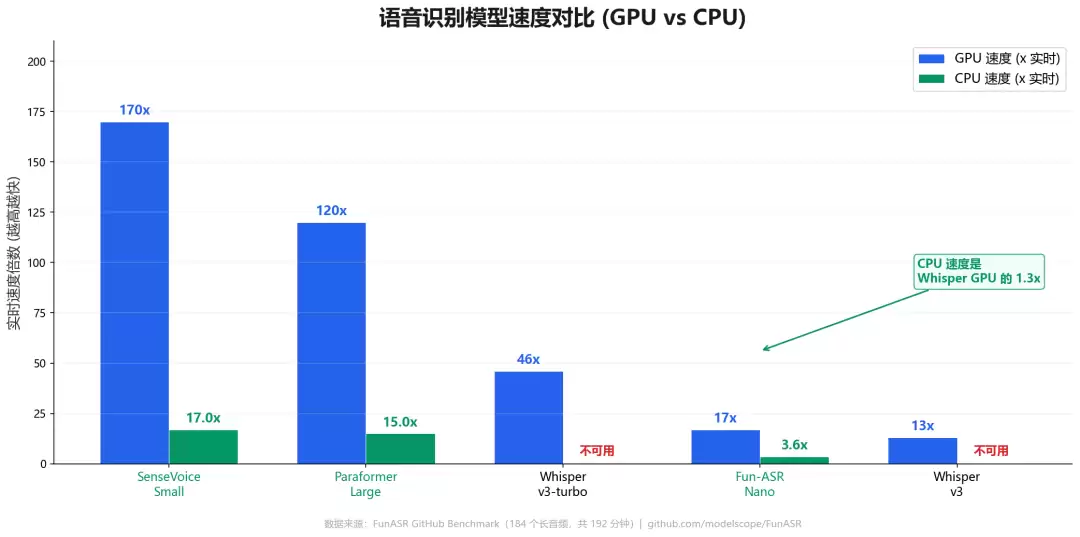
SenseVoice-Small(234M 参数)GPU 上 170x 实时速度,CPU 上 17x。作为对比,Whisper-large-v3 在 GPU 上只有 13x,CPU 根本跑不动。
Paraformer-Large(220M 参数)120x GPU / 15x CPU,是 Whisper 的 9 倍。
就连带 LLM 解码器的 Fun-ASR-Nano(800M 参数、31 语言)也能跑到 17x GPU / 3.6x CPU——比 Whisper-large-v3 还快 30%。
一句话:以前"自己部署一套靠谱的语音识别"需要 GPU 服务器,现在一台普通电脑就能跑。
第一次上手:3 步把它跑起来
好,说完了"它有多好",说"怎么用"。这章的承诺是:你按着操作一遍,能成功。
第 1 步:装 Python 依赖
这一步的目的是准备好运行环境。FunASR 需要 Python 3.8 及以上,PyTorch 和 torchaudio 必须先装。
先装 PyTorch(去 pytorch.org 选你电脑对应的版本),然后:
pip install torch torchaudio
pip install funasr
两行命令,装完就能用。
注意:PyTorch 一定要先装。如果先装 funasr 再补 PyTorch,可能会遇到版本冲突。这是上手最容易犯的错。
装完之后,验证一下:
python -c "import funasr; print(funasr.__version__)"看到版本号就说明第 1 步完成了。这一步做完,下一步才能加载模型。
第 2 步:选模型,跑第一段音频
这一步的目的:选一个适合你场景的模型,用一段示例音频验证整个流程能跑通。
推荐从 SenseVoiceSmall 开始——234M 参数,支持中英日韩粤语,速度快,自带情绪识别。日常会议记录、视频字幕完全够用。
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model = AutoModel(
model="iic/SenseVoiceSmall",
vad_model="fsmn-vad",
spk_model="cam++",
device="cuda"# 没有 GPU 改成 "cpu"
)
result = model.generate(
input="https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav"
)
for seg in result[0]["sentence_info"]:
print(f"[{seg['start']/1000:.1f}s] Speaker {seg['spk']}: {rich_transcription_postprocess(seg['sentence'])}")
输出长这样:
[0.6s] Speaker 0: 欢迎大家来体验达摩院推出的语音识别模型
这就跑通了。一句 model.generate() 替你完成了 VAD 切句、语音识别、标点、说话人分离——四件事一次搞定。
重点:device="cuda" 改成 device="cpu" 就能在没显卡的机器上跑,速度是 17x 实时——处理 1 小时音频大约 3.5 分钟。
第 3 步:换自己的音频
把上面代码里的 input URL 换成你自己的音频文件路径:
result = model.generate(input="my_meeting.mp3")
支持 WAV、MP3、M4A、FLAC 等常见格式。如果音频有多个人说话,说话人分离和情绪识别会自动生效。
这步做完,你已经拥有了一套可以日常使用的语音转写工具。
配好之后,每次使用只需要做一件事:传音频路径给 model.generate()。
如果自己操作遇到困难,找开发者朋友帮你装一次,之后你自己就能用了。
跑通之后,想切到更快的模型?试试 fun-asr-nano 配合 vLLM 加速——但先用默认的 SenseVoiceSmall 跑起来再说。
装好之后,日常怎么用
CLI 命令行:最简单的日常入口
如果你不想写 Python,命令行就够了:
# 基础转写
funasr meeting.wav
# 输出 JSON(供程序处理)
funasr meeting.wav --output-format json
# 直接出字幕文件
funasr meeting.wav --output-format srt --output-dir ./subs
# 带说话人标签 + 时间戳
funasr meeting.wav --spk --timestamps -f json
# 指定模型和语言
funasr meeting.wav --model paraformer --language zh
# 批量处理
funasr *.wav --output-format srt --output-dir ./output
--model 可选:sensevoice(默认)、paraformer、paraformer-en、fun-asr-nano。
三个进阶功能,知道就行
流式实时转写:边说话边出字,适合直播字幕。加载 paraformer-zh-streaming 模型,把音频流切成 600ms 的小块逐块送进去。配合 WebSocket 就能搭一套实时字幕系统。
情绪识别:用 emotion2vec_plus_large 模型,在转写的同时标出每句话的情绪——开心、生气、难过。适合客服质检、访谈分析。
部署成 API:一行命令起一个 OpenAI 兼容的 API 服务:
funasr-server --device cuda
然后任何支持 OpenAI API 的工具(LangChain、Dify、AutoGen)都能直接调,连 Claude 和 Cursor 都能通过 MCP Server 挂上去当语音转写工具用。
说实话,这会改变什么?
三个判断,直接说:
对个人用户:免费语音转写的门槛降到了"会装 Python"。以前你为了转个播客,要么开讯飞会员,要么付 API 费用——现在一个 pip install,数据全在自己机器上。
对小团队:内部会议记录、客服录音质检、视频字幕生成——这些场景找 SaaS 是一笔固定开支。现在一台闲置的 Linux 机器就能跑,CPU 都跑出 17x 实时。
对整个 ASR 生态:FunASR 把"免费 + 自部署 + 工业级精度 + 多语言 + 情绪/说话人"五个维度同时拉满。Whisper 做不到。MIT 协议意味着你甚至可以拿去改、做商业产品。
好,但也不全是好消息。
FunASR 的中文和东亚语言是强项——达摩院团队在中文数据上下了狠功夫。英文识别呢,Whisper 还是稳的,毕竟 OpenAI 的训练数据以英文为主。另外 Fun-ASR-Nano(31 语言、800M 参数)在纯 CPU 上 3.6x 实时——处理 1 小时音频大概要等 17 分钟,不算快,但能跑。
重点:FunASR 真正适合的人——想要免费的、能自己部署的、带说话人分离的语音转写,不介意花 5 分钟装一个 Python 包。如果你正好是这类人,今天就试试。CPU 够用了。
参考链接 [1] https://github.com/modelscope/FunASR [2] https://x.com/FakeMaidenMaker/status/2066871917022232683
点赞、转发、小心心 ❤️ 欢迎在评论区留下你的想法!
— 完 —
登录查看剩余 70% 内容
相关文章
- 南网在线APP怎样联系客服 07-01
- 南网在线APP客服咨询指引 07-01
- CAD一键转PDF图纸 07-01
- 中国蓝TV在线客服联系方法 07-01
- 蓝颜在线客服查看方法 07-01
- 恋与深空全新家园玩法攻略 深空懒人法培育花全图鉴 07-01