



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
不是哥们!内存泄露就让它漏 真的可行吗?
时间:2026-06-12 09:19:47 编辑:袖梨 来源:一聚教程网
内存泄露就让它漏,可行吗?
例如只通过malloc和new内存,每天重启服务器,不free或者delete释放内存,大家觉得这种方案可行吗?
对于这个问题,知乎上的网友们给出了不同角度的见解,以下是精选的优质回答。
1号知乎网友:Anlin
可以的!
你说的这个叫做NPI-GC*[1]。
不但有人用,而且是用在要求很高的军事软件上。
国外有个公司给导弹写的机载软件,被发现有内存泄漏+。
首席软件工程师说没关系,我们算了导弹飞行时间内最多能泄漏的内存,给导弹多配了泄漏量两倍的内存,让它随便漏。
等导弹炸了,泄漏的内存就释放了。
真是一场酣畅淋漓的垃圾回收。

2号知乎网友:Retro工房
你的想法很常见。
我维护过相当多的 GitLab。这玩意儿就是一个明确承认自己内存泄漏,并且可配置定期重启的服务:GitLab installation requirements。
Sidekiq uses a multi-threaded process for background jobs. This process initially consumes more than 200 MB of memory and might grow over time due to memory leaks.
Sidekiq(GitLab 要件之一)使用多线程进程处理后台任务。此进程初始消耗超过 200 MB 内存,并且由于内存泄漏,可能会随时间增长。
GitLab 的内存泄漏原因在于 Ruby on Rails 本身内存泄漏;而 Ruby on Rails 的内存泄漏来自于 Ruby 的内存泄漏。Ruby 的内存泄漏问题应该是从三十年前诞生的时候就有了。
而 GitLab 官方给出的对策就是:多启动一些 Sidekiq 进程并行服务,然后派一个 memory_killer 进程看着他们;哪个 Sidekiq 进程的内存使用量达到阈值了,就干死它:Reducing memory use
所以 GitLab 的内存利用率一直都是类似这个样子,在 Sidekiq 进程被干死的瞬间有一个断崖下跌,然后随着新的 Sidekiq 进程被拉起,使用率又会瞬间拉起,然后缓慢上升。循环往复:
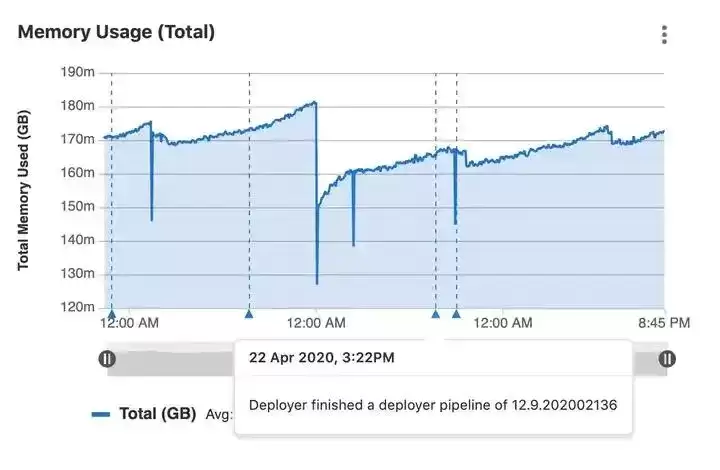
但是这个解决方式有个相当无语的缺点……GitLab 官方要求的最低配置是 8 GB 内存,就是因为要留给 Sidekiq 的内存足够的膨胀空间。其实如果不泄漏的话,对于小团队用不了这么内存。
这个问题当年可给我吓坏了,那时候也不太懂。部门提交不频繁,因此一直都没有达到重启的阈值。部门的所有代码都放在上边,就怕哪天爆了就废了。所以每天都陷入在焦虑中。后来研究明白了,也就放心了。
所以,你的想法原理上没问题。但是,如果是生产环境的话,因为要确保高可用,所以比较麻烦。你需要参考 GitLab 的机制,多起几个进程,用守护进程看着它们,再写一个 killer 机制,定期的通知内存膨胀的进程自杀掉,这样才能保障可用性。
3号知乎网友:大漠
可行。
解决不了程序的问题,就解决有问题的程序。
当年我参与的一个项目,就出现了内存泄漏,系统服务跑上一个星期必然内存耗尽崩溃。
遇到业务高峰期,两三天就崩了。
因为项目引用了太多第三方组件,还有一大堆自己人开发的库,谁也不知道是哪个环节出了问题。
项目工期紧张,仓促上线,磕磕绊绊一段时间后,内存泄漏的问题一直没解决。偏偏还总是在业务繁忙的时候崩溃,甲方业务员总是抱怨。
怎么办?这个问题不解决项目无法验收。
既然要两天才崩溃,那么我让系统服务连续运行不要超过一天,不就可以了?
真是天才一样的解决方案,我被自己高效的思维深深折服。
于是我做了一个自动重启任务,每天早上7点,在甲方公司上班之前,系统服务自动重启。为什么不是半夜0点重启?
主要是怕重启失败,会被甲方电话半夜叫到现场处理......
系统服务重启前先持久化Session和缓存,重启的时候再恢复,假装自己没重启过一样。为了防止有人在重启期间使用系统,还装模作样的在重启前发布消息:警告!系统正在结转并维护数据,暂停10分钟。
甲方居然没有察觉,还以为我们把内存泄漏问题解决了,然后项目验收通过。
4号知乎网友:孤孤无悔
在可控的情况下可行。
我的某个与机器人相关的项目,有一处内存泄漏怎么也查不出来。
泄漏速度大概是每秒4kb,猜测是我们用的工业摄像头的SDK造成的。
最后实在找不出来了,算一下发现3天才漏1GB内存,我们有8GB内存,每天重启足够了。
5号知乎网友:gashero
多年前有一位友人在某公司做运维方向的领导,级别未知。
据说他当时从一线上去,就是因为写了在Windows Server上每天重启的脚本。
对更大的领导来说,不知道他施加了什么魔法,不定期的服务器挂掉被他搞定了。
反正重启的时间段本来也没什么人玩传奇。
所以题主的想法是有适用环境的。
6号知乎网友:没那么难
Linux已经预料到了,会有粗心或者坏心的程序员漏写或者故意不释放内存的情况,为了保障系统有足够的内存资源,内存不足时会有一个叫oom-killer的进程跳出来干掉那些占用大量内存的进程。
OOM是可以设置进程优先级的,就是oom_adj,从-17到15,oom_adj值越大越容易被杀死,在 oom_adj 值相同时 , 内存占用量越大的进程 , 被杀的几率就越高。
如果不希望自己的进程被oom kill掉,可以将它设置为-17,方法:
相关文章
- 微信登录设备管理在哪里查看 06-12
- 百果园app如何更换头像 06-12
- 大学搜题酱怎么关闭悬浮窗 06-12
- easyrecovery如何恢复文件 06-12
- 小红书网页版如何在线刷 06-12
- 鲨鱼浏览器如何关闭书签显示 06-12