



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
DMA 不只是设备绕过 CPU 访问内存这么简单
时间:2026-06-12 09:18:48 编辑:袖梨 来源:一聚教程网
不经过 CPU,外设直接访问内存。
这句话不能算错。
但如果你真的拿着这句话去理解驱动,去看网卡、看 NVMe、看音视频采集,后面大概率还是会越来越糊。
因为 DMA 真正改变的,不只是“少拷贝一次数据”,也不只是“让 CPU 省点事”。它真正改变的,其实是:整个系统里数据流动的方式。
平时我们一说高性能 I/O,脑子里会想到很多东西:网卡收包、NVMe 读写、GPU 提交命令、视频采集、音频流处理。这些场景看起来差别很大,但底下往往都绕不开同一个东西:DMA。
所以 DMA 这个概念,表面上看不难,真到系统里一落地,反而特别容易把人绕进去。尤其是一旦系统里有 Cache,很多事情就会突然变得不再直观。
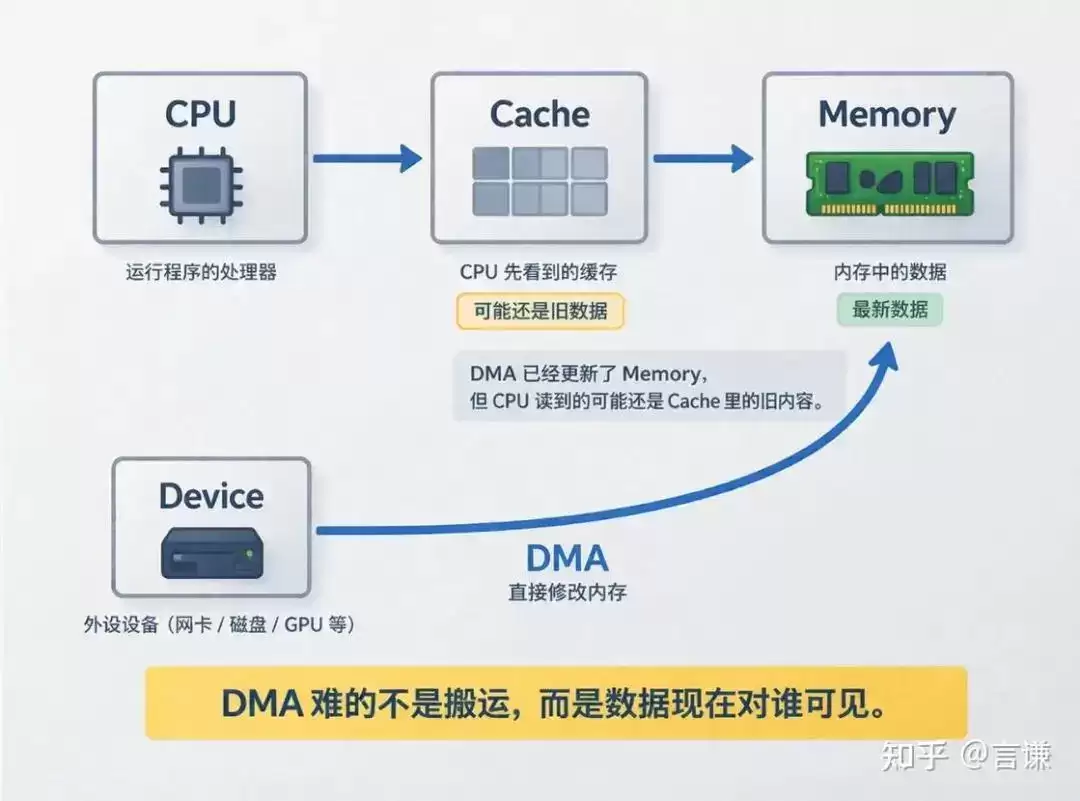
你明明觉得数据已经写好了,设备却像没看见。你明明觉得 DMA 已经写回来了,CPU 读出来却还是旧值。代码看上去没什么问题,但结果就是不对。
这时候如果还只是把 DMA 理解成“设备绕过 CPU 访问内存”,通常就不太够了。
因为真正让 DMA 变复杂的,不只是设备和内存。而是当系统里有了 Cache 之后,事情会慢慢变成:CPU、Cache、Memory、Device,这四者之间的数据可见性问题。
而 DMA 最难的地方,往往也就卡在这里。
先别急着谈 Cache。先把最基础的问题想清楚:
DMA 到底解决了什么?
如果没有 DMA,设备和内存之间交换数据,通常得让 CPU 自己参与。比如设备要把数据送进内存,路径大概就是这样:
Device → CPU → Memory
如果反过来,要把内存里的数据发给设备,也差不多:
Memory → CPU → Device
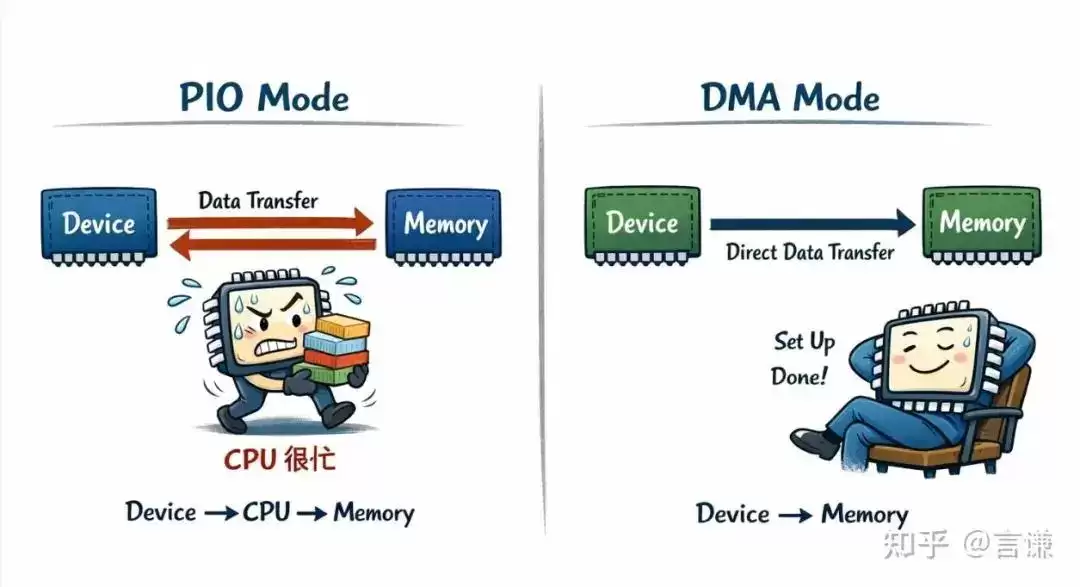
这种方式一般叫 PIO,Programmed I/O。
说白了,就是 CPU 自己一趟一趟搬。
这种模式最大的问题,不在于“不能用”,而在于太浪费 CPU。
因为 CPU 原本应该做的是控制、调度、协议处理、业务逻辑。结果现在却被拉去干体力活:不停 load,不停 store,把数据从一边搬到另一边。
DMA 的出现,就是把这件事拆出去。
它不是让 CPU 搬得更快。而是干脆说:这件事别让 CPU 一条指令一条指令去搬了,交给 DMA 去做。
CPU 自己只负责三件事:
-
先把参数配好;
-
告诉 DMA 可以开始了;
-
等搬完之后,再处理后面的逻辑。
所以 DMA 的本质,不是“更快的 memcpy”。
更接近真实的说法应该是:
DMA 把数据搬运这件事,从 CPU 的指令路径里剥离了出去。
这句话,比“绕过 CPU 访问内存”更接近它的核心。
到这里,很多人会继续问:那 DMA 为什么能提升性能?
原因其实并不神秘。
最直接的一点,是 CPU 不再是搬运工了。
以前在 PIO 模式下,CPU 得一下一下地读设备、写内存,或者从内存读出来,再写给设备。这个过程机械、重复,而且很占时间。用了 DMA 之后,CPU 至少可以把精力用在更值得它做的事情上。
第二点,是 DMA 特别适合大块数据传输。网卡包、NVMe 数据块、视频流、音频流,这类东西有个共同点:数据量大,而且是连续流动的。
这类工作交给 DMA 来做,天生就比让 CPU 一点点搬更合适。
还有一点很关键,但经常被一句话带过去,那就是:CPU 和 I/O 可以并行了。
DMA 在后台搬数据的时候,CPU 不一定非得原地等着。CPU 可以去做别的事,DMA 也在另一边继续跑。现代系统之所以能做出高吞吐 I/O,背后很大一部分基础,其实就是这种并行。
所以 DMA 不是一个“小优化”,它更像是现代高性能 I/O 的基础能力。
没有它,很多事情都能做,但很难做得漂亮。
DMA 真正好理解的时候,往往是在一个具体场景里。
比如,最经典的:网卡收包。
假设现在网卡收到了一个网络包,这个数据最终要进内存,然后操作系统协议栈再来处理。
如果按最笨的方式来,当然也能做:先让 CPU 从网卡那边把数据读出来,再由 CPU 搬进内存。
但真这么干,CPU 很快就会忙不过来。
实际系统一般不是这么做的。
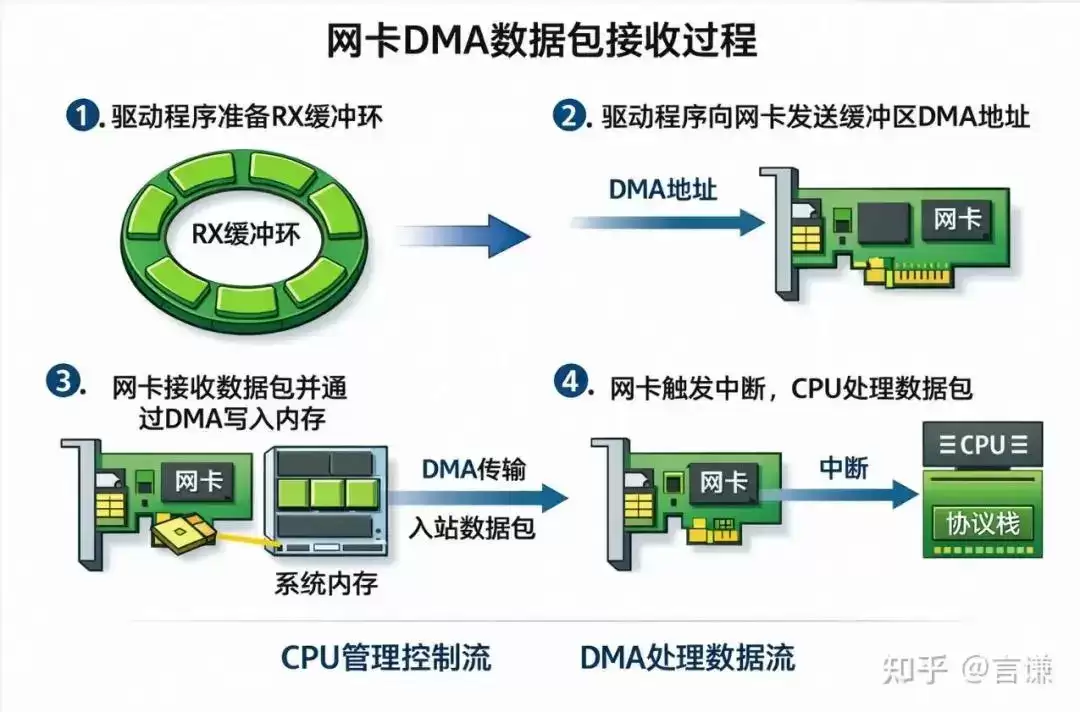
驱动通常会提前准备好一批接收缓冲区,也就是 RX ring 里的那些 buffer。这些 buffer 放在内存里,驱动会把它们对应的 DMA 地址交给网卡,相当于提前告诉它:
“后面你收到包,就直接往这些位置写。”
等网卡真的收到数据以后,它就通过 DMA,把数据直接写进这些 buffer。整个搬运过程里,CPU 不负责逐字节复制。
等数据写完了,网卡再通过中断或者轮询通知 CPU:
“数据已经到了,你现在可以来处理了。”
这时候 CPU 才开始干它真正该干的事:解析包头、跑协议栈、把数据交给上层应用。
所以这个场景里,分工其实非常清楚:DMA 负责把数据搬进来。CPU 负责在数据到了之后,处理控制和逻辑。
你一旦把网卡收包这个过程想顺了,对 DMA 的理解就会比单纯背定义靠谱很多。
如果系统里只有 CPU、Memory、Device 这三个角色,其实很多事情还没那么绕。真正让 DMA 开始变难的,往往是 Cache。
因为现代 CPU 平时访问数据,通常不是每次都直接去内存,而是优先看 Cache。这时候,系统里的参与者就不再只是三个,而是变成了:
CPU / Cache / Memory / Device
而问题也恰恰出在这里。
设备做 DMA 时,它看到的通常是 Memory。CPU 平时读写数据时,它先看到的往往却是 Cache。
只要这两个视角没同步好,麻烦就来了。
很多 DMA bug,看起来表面现象千奇百怪:设备读到旧数据、CPU 看不到 DMA 更新、偶发脏数据、CRC 错、丢包、花屏。
但往下追,经常最后都能归到同一个问题上:CPU 看到的数据,不一定等于内存里的数据。
这个地方,才是 DMA 真正开始变复杂的起点。
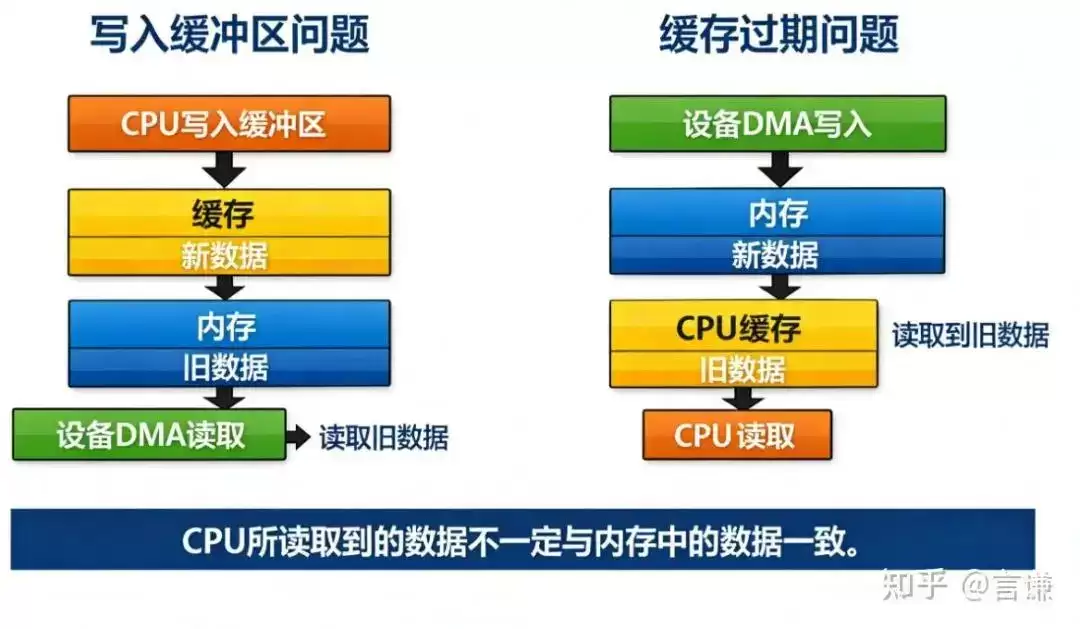
最典型的第一种情况,是:CPU 写了新数据,但设备读到的还是旧数据。
比如 CPU 往一个 buffer 里写了一堆内容。从 CPU 的角度看,这事已经结束了,因为代码已经写完了。但实际上,这些新数据可能还停留在 cache 里,并没有及时回写到 memory。
这时候设备去做 DMA 读取,它读到的是 memory 里的内容。而 memory 里如果还是旧值,那设备拿到的自然也是旧数据。
于是现象就会变成:CPU 明明写过了,设备却像没看见。
这类问题在发包、描述符更新、命令提交这类场景里都特别常见。
第二种情况,正好反过来:设备已经 DMA 写回内存了,但 CPU 看到的还是旧值。
比如设备通过 DMA 把新数据写进了 memory。但 CPU 之前已经读过这个地址,对应的 cache line 还保留着老内容。那 CPU 再去读的时候,很可能直接命中 cache,看到的仍然是旧数据。
从设备的角度看,数据明明写好了。从 CPU 的角度看,像是什么都没发生。
这个感觉特别让人头疼,因为双方都没“错”,只是它们根本没在看同一份东西。
所以很多 DMA 问题,真正麻烦的地方并不是“搬运有没有发生”,而是:这份数据现在到底对谁可见。
讲到这里,很多人会发现另一个现象:
为什么有的平台上写 DMA 驱动,感觉没那么痛苦;有的平台上却老是出各种奇怪问题?
这里就得区分两个概念了:DMA coherent,和 DMA non-coherent。
有的平台会在硬件层面帮你维护一致性。CPU 这边写了,设备那边比较容易看到;设备 DMA 写了,CPU 这边也比较容易看到更新。这类平台上,驱动开发体验会轻松很多。
但也有很多平台并不会自动替你兜这些事。这种情况下,Cache 和 Memory 之间的一致性,需要软件自己显式处理。DMA 前该同步的同步,DMA 后该失效的失效,不然 CPU 和设备看到的就很容易不是同一份数据。
很多嵌入式 SoC,尤其 ARM、RISC-V 这类平台上,DMA 问题之所以容易让人头大,很大程度上就是因为这里没有被自动抹平。
这也是为什么,同样是 DMA,大家的“使用体验”会差很多。不是 DMA 这个概念变了,而是平台替你做了多少事情,不一样。
然后很多人会很自然地想到一个办法:那我自己 flush cache,不就行了吗?
这个念头特别正常,但真写驱动时,通常不能这么想得太简单。
因为 DMA 面对的,从来不只是一个 cache flush 的问题。它经常还连着地址转换、IOMMU、内存屏障、设备可达地址范围这些事情。你以为自己在修一个 cache 问题,实际上碰到的是整套 DMA 可见性和访问语义的问题。
而且不同架构下,cache 操作方式本来就差很多。x86、ARM、RISC-V 的处理方式不一样,平台能力也不一样。驱动如果自己把这些细节写死,通常既不好维护,也很难移植。
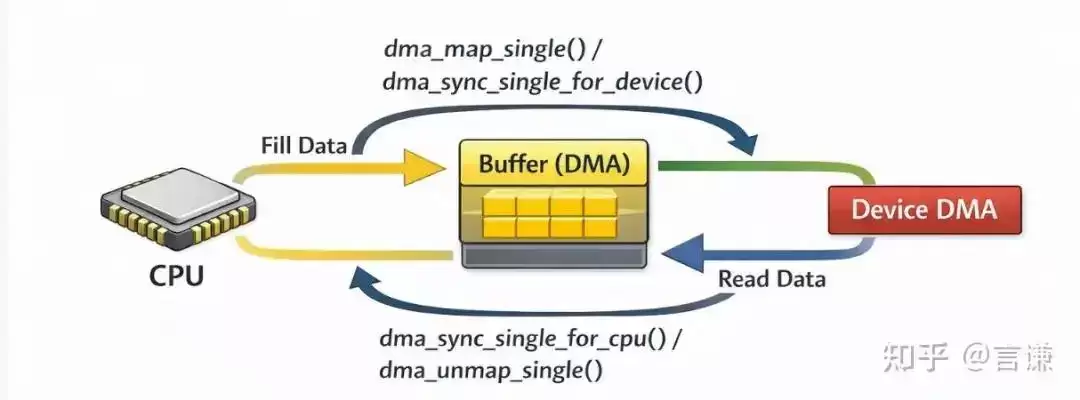
所以 Linux 才提供了 DMA API。
像dma_alloc_coherent()、dma_map_single()、dma_unmap_single()、dma_sync_single_for_cpu()、dma_sync_single_for_device() 这些接口,表面上看像是一组函数,实质上描述的是另一件事:
CPU 和设备之间,这份数据的使用权和可见性,什么时候发生切换。
也就是说,它们不是单纯在做“地址转换”或者“cache 操作”,而是在帮你表达:
现在这块数据要交给设备了;现在这块数据又交还给 CPU 了。
这么去理解 DMA API,会比把它们当成几个零散工具函数更顺。
除了可见性问题,DMA 还有一个特别容易让新手误判的点:
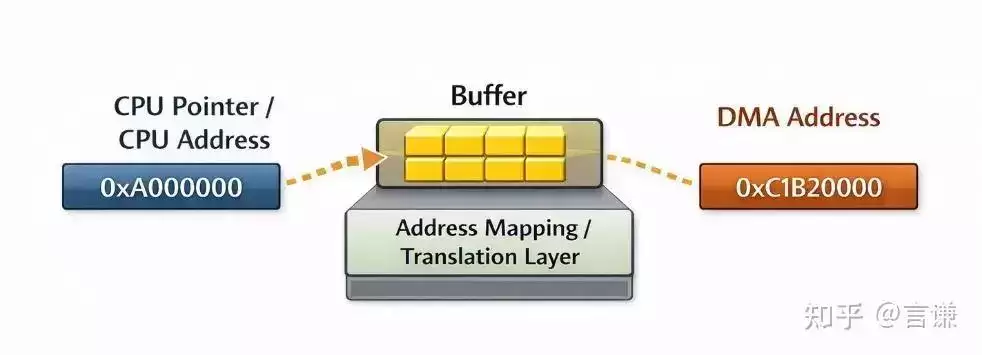
DMA 地址不是 CPU 随手拿到的那个指针。
很多人第一次写 DMA 时,都会下意识地觉得:
“这块 buffer 是我申请的,我手里已经有地址了,直接给设备不就行了吗?”
但这件事,在概念上其实并不成立。
因为 CPU 代码里拿到的,往往是 CPU 自己视角下的地址。而设备做 DMA 时,需要的是设备自己能用的地址。
中间可能会经过物理地址转换,可能有 IOMMU,也可能有平台自己的地址重映射。所以 CPU 能用的地址,不一定就是设备能直接拿去发 DMA 的地址。
这也是为什么驱动里,明明你已经有了一个 buffer,还会再冒出来一个 DMA address。
看起来像多此一举,其实不是。
它只是提醒你一件事:CPU 的地址,不等于设备的地址。
所以 DMA 真正难的地方,常常也不在“怎么搬”,而在:地址该怎么理解,数据什么时候对谁可见。
讲到这里,其实很多原来看起来很玄的现象,就都能解释了。
为什么驱动里数据明明填好了,设备却读到旧内容?因为 CPU 看到的可能只是 Cache 里的新值,Memory 那边还没同步过去。
为什么 DMA 明明已经完成了,CPU 再读还是老数据?因为设备写进的是 Memory,CPU 可能还在看自己的旧 Cache。
为什么同样的驱动逻辑,在一个平台上没事,换个平台就开始出现各种怪问题?因为平台对 DMA 一致性的处理方式不同,有的帮你做了很多,有的几乎没帮你做。
为什么 DMA API 不能随便省,不能觉得“我直接传指针也差不多”?因为它本来就在帮你处理“设备能看到什么、CPU 能看到什么”这件事。
很多时候,并不是 DMA 本身很神秘。而是你如果一直把它理解成一句很粗糙的话——“设备直接访问内存,不经过 CPU”——后面那些真正重要的问题,就都被藏起来了。
如果非要把这篇文章最后再压成一句话,那我会更想写成这样:DMA 真正难的地方,不是搬数据,而是这份数据在当前这一刻,到底对谁可见。
而如果再进一步压成一句最适合当结尾的话,那我会写:别只盯着数据搬没搬过去,更要先问一句:现在这份数据,CPU 和设备看到的是不是同一份。
因为 DMA 里的很多坑,难不在概念有多高深,而在于它把“数据搬运”这件事,变成了一个多视角的数据可见性问题。
一旦你把这一层想明白,很多原来看起来很诡异的 DMA bug,突然就没那么玄了。
相关文章
- 微信登录设备管理在哪里查看 06-12
- 百果园app如何更换头像 06-12
- 大学搜题酱怎么关闭悬浮窗 06-12
- easyrecovery如何恢复文件 06-12
- 小红书网页版如何在线刷 06-12
- 鲨鱼浏览器如何关闭书签显示 06-12