



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Python 如何同时处理很多事:进程、线程、协程
时间:2026-06-09 08:19:47 编辑:袖梨 来源:一聚教程网
从全局角度理解“程序如何同时做很多事”。并发与并行、同步与异步、进程、线程、协程、GIL、锁、队列、管道、进程池、线程池这些知识点,会放到各自真正适合的位置讲。
你可以先记住一句话:
进程解决“资源隔离”和“多核计算”。
线程解决“同一个进程里并发等待 I/O”。
协程解决“用更轻量的方式组织大量 I/O 等待”。
一、先建立全局地图
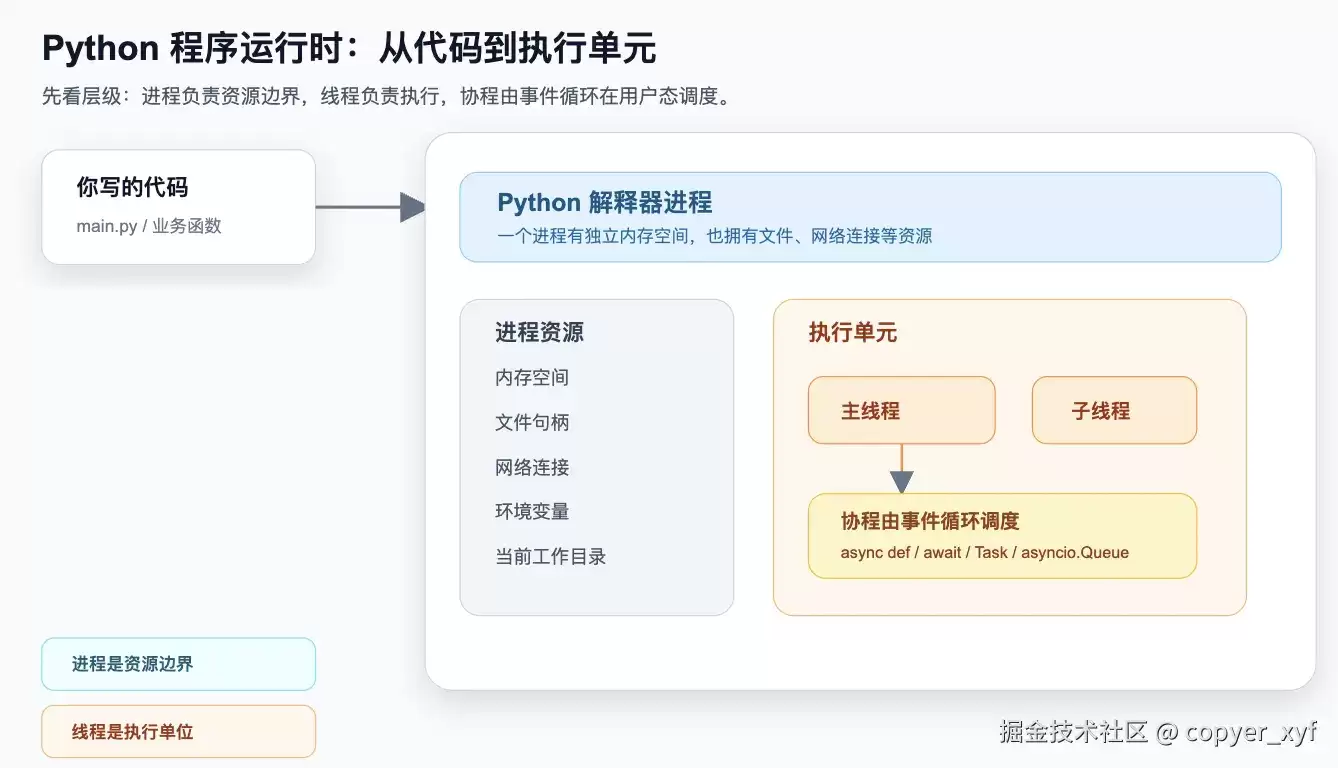
当你执行:
python main.py
本质上是启动了一个 Python 解释器进程。这个进程里至少有一个主线程,主线程从上到下执行你的 Python 代码。
看这张图时,重点抓住三层:
- 进程由操作系统创建和管理。
- 线程也由操作系统调度。
- 协程通常由程序里的事件循环调度。
所以不能简单说“协程就是更小的线程”。它们的管理者不一样。
进程更像一个资源容器,里面有自己的内存、文件句柄、网络连接和环境变量。线程是这个容器里的执行单位。协程通常运行在线程内部,由事件循环决定什么时候暂停、什么时候恢复。
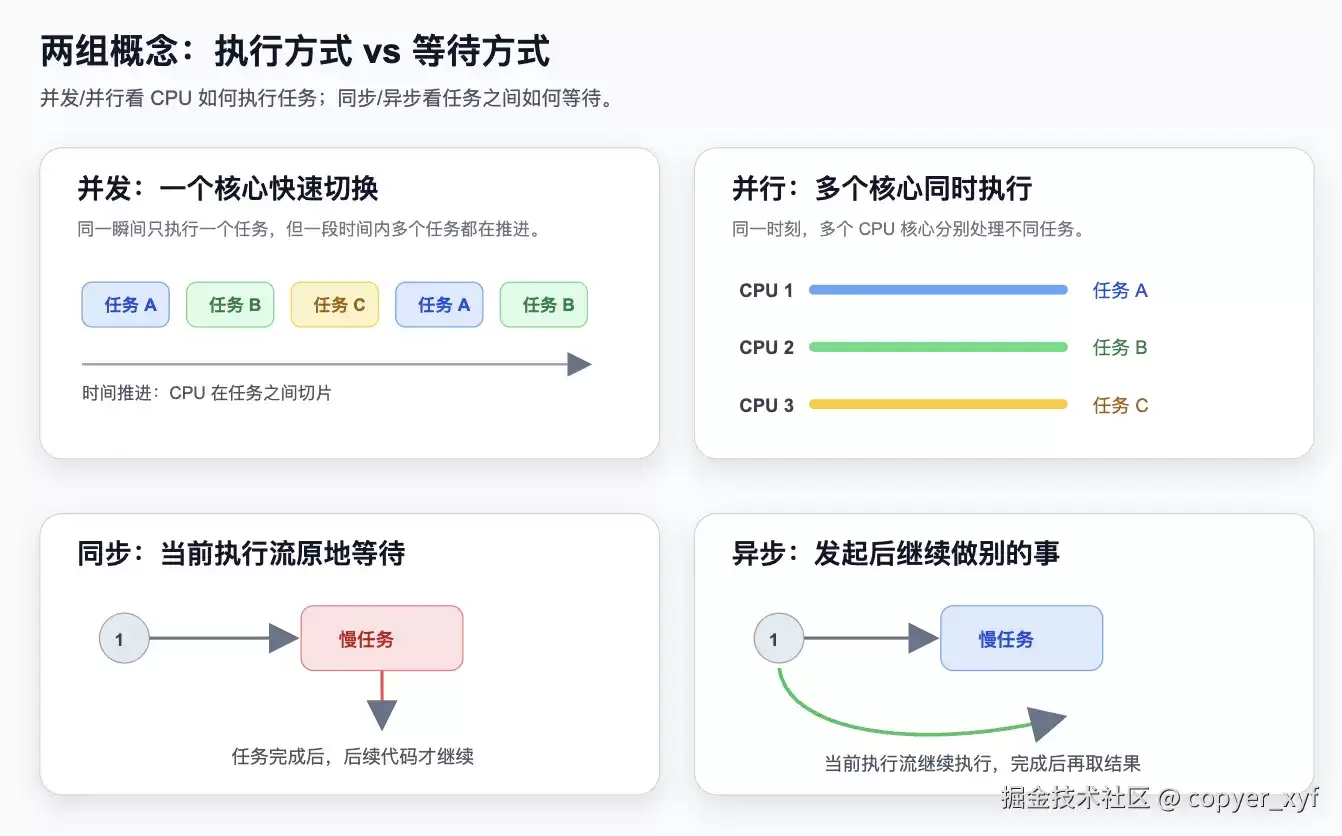
并发和并行
并发不等于并行。
单核 CPU 可以并发,因为它能快速切换任务;但单核 CPU 不能真正并行执行多个任务。
多核 CPU 可以并行,但你的程序是否能利用多核,还取决于你使用的是进程、线程、协程,以及语言运行时的限制。
同步和异步
同步 / 异步描述的不是 CPU 有几个核心,而是任务之间怎么等待。
这四个词要分开:
并发 / 并行:任务如何被 CPU 执行。
同步 / 异步:任务之间如何组织等待关系。
这里要特别注意:CPU 核心数和执行速度,不会改变任务之间的逻辑依赖关系。如果任务 B 必须等任务 A 的结果,那么 CPU 再多,也不能让 B 在 A 没有结果时正确完成。
二、什么时候该用什么
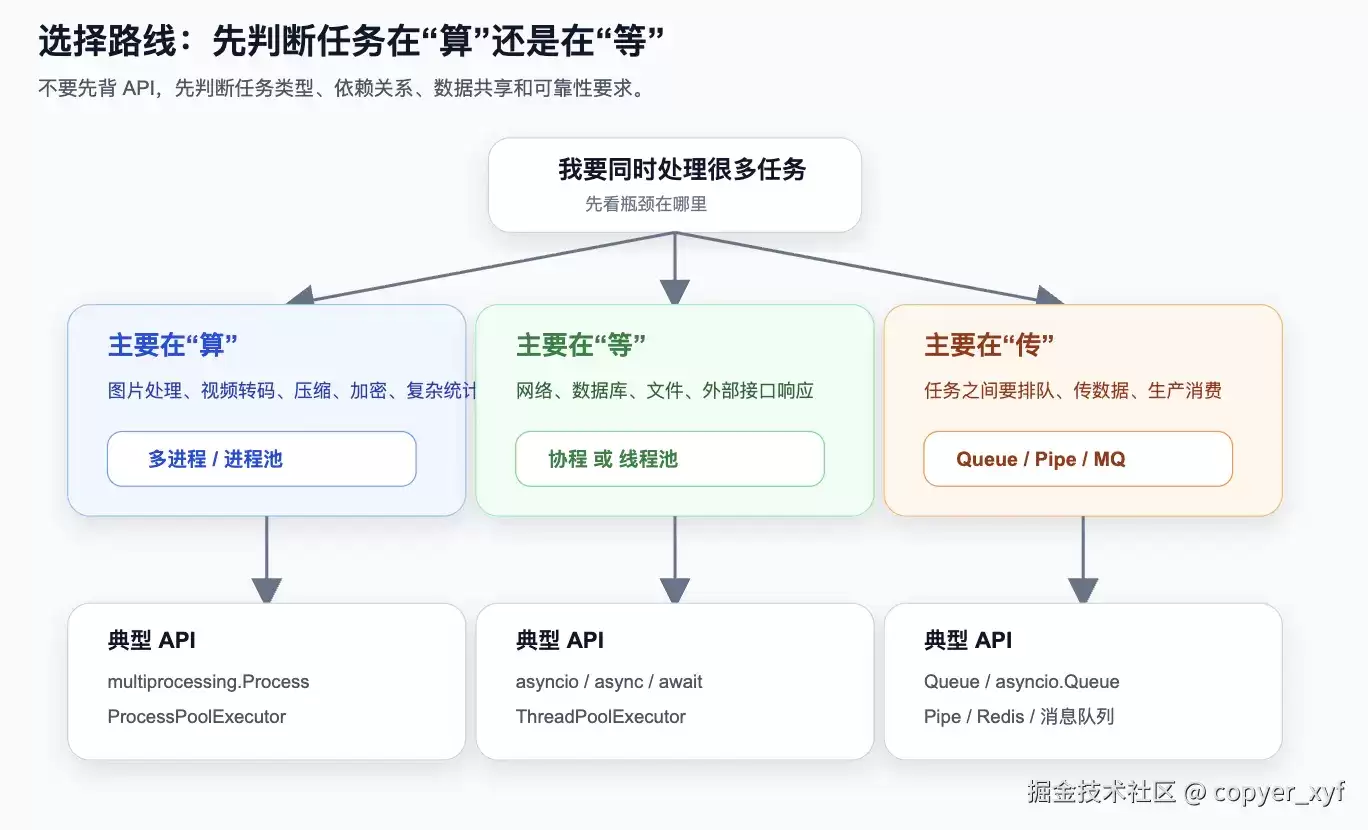
先学会判断任务类型。你要问的第一件事不是“用哪个库”,而是“这个任务主要在算、在等,还是在传数据”。
如果任务主要在算,比如图片处理、视频转码、压缩、加密、大量数学计算,优先考虑多进程或进程池。因为这类任务真正消耗 CPU,需要尽量利用多核。
如果任务主要在等,比如等网络接口、等数据库、等文件读写,优先考虑线程池或协程。因为等待期间 CPU 没有真正忙起来,关键是不要让当前执行流傻等。
如果任务之间要传数据,比如一个任务生产订单,另一个任务消费订单,就要考虑 Queue、Pipe、Redis、消息队列这类通信工具。
更具体一点:
| 场景 | 更常见选择 | 原因 |
|---|---|---|
| CPU 密集型 | 多进程 / ProcessPoolExecutor | 多个进程可以更好利用多核 |
| 同步阻塞 I/O | 多线程 / ThreadPoolExecutor | 等待 I/O 时可以切换到其他线程 |
| 异步 I/O | 协程 / asyncio | 单线程内用事件循环管理大量等待任务 |
| 任务需要隔离 | 多进程 | 一个进程崩溃,不一定影响其他进程 |
| 任务需要共享内存 | 多线程 | 同一进程内线程共享内存,但要注意锁 |
| 后台任务要可靠重试 | Celery / RQ / 消息队列 | 比本机线程/进程更适合生产环境任务系统 |
用一个更贴近底层原因的例子理解:
假设有 4 个任务,分别要做 4 道很难的数学题。
如果只安排 1 个人做,他要一题一题算:
人 A
-> 算第 1 题
-> 算第 2 题
-> 算第 3 题
-> 算第 4 题
这类任务的问题是:人一直在动脑,没有空闲时间。对应到程序里,就是 CPU 一直在计算。
如果你把这 4 道题交给 4 个线程,在 Python 里不一定能同时变快。因为同一个 Python 进程里,多个线程执行纯 Python 代码时,会受到 GIL 影响,很多时候不能真正同时跑多段 Python 计算。
更像这样:
同一个房间里有 4 个人
-> 但只有 1 支笔
-> 谁拿到笔谁算
-> 其他人只能等这支笔
这支“笔”可以粗略理解成 GIL。线程多了,但真正执行 Python 计算的机会仍然被限制住了。所以 CPU 密集型任务更常见的选择是多进程:
4 个独立房间
-> 每个房间都有自己的笔
-> 每个人可以同时算自己的题
对应到程序里:
多个进程
-> 各自有独立的 Python 解释器
-> 各自有自己的 GIL
-> 更容易利用多个 CPU 核心同时计算
这就是“主要在算,优先考虑多进程”的原因。
再看“主要在等”的任务。
假设有 4 个任务,分别是等 4 个接口返回结果:
任务 1:请求接口 A,等 3 秒
任务 2:请求接口 B,等 2 秒
任务 3:请求接口 C,等 5 秒
任务 4:请求接口 D,等 1 秒
这时人不是一直在动脑,大部分时间是在等别人回复。对应到程序里,就是线程发出网络请求后,大部分时间在等待 I/O。
如果只用一个线程,它会这样傻等:
线程 1
-> 请求接口 A,等 3 秒
-> 请求接口 B,等 2 秒
-> 请求接口 C,等 5 秒
-> 请求接口 D,等 1 秒
总时间大概就是 3 + 2 + 5 + 1 秒。
如果用多个线程,就像几个人分别去窗口排队:
线程 1 -> 等接口 A
线程 2 -> 等接口 B
线程 3 -> 等接口 C
线程 4 -> 等接口 D
这些线程大部分时间都没有占着 CPU 算东西,只是在等网络、数据库、磁盘返回结果。一个线程在等 I/O 时,操作系统可以切换到另一个线程继续执行。这样总时间更接近最慢的那个等待时间,而不是所有等待时间相加。
所以“等”适合线程,不是因为线程计算更快,而是因为:
等待 I/O 时,CPU 是空的
-> 当前线程可以先让出去
-> 其他线程可以继续推进别的任务
因此可以简单记:
算:
CPU 一直被占着
-> 多线程很难绕开 GIL
-> 多进程更容易用上多核等:
CPU 大部分时间没事做
-> 线程等待 I/O 时可以切换
-> 多线程能减少整体等待时间
理解了吗?
三、进程
进程是操作系统分配资源的基本单位。
一个正在运行的程序,背后通常对应一个或多个进程。比如浏览器是多进程架构,打开多个标签页时,浏览器可能创建多个渲染进程。Python 脚本运行时,也会有一个 Python 解释器进程。
进程的核心特点
- 进程有独立内存空间。
- 进程之间默认不共享普通变量。
- 进程之间通信成本比线程高。
- 一个进程崩溃,通常不会直接破坏另一个独立进程的内存。
- 多进程更适合 CPU 密集型任务。
查看当前进程
import osprint(f"当前进程 pid: {os.getpid()}")
print(f"父进程 pid: {os.getppid()}")
print(f"CPU 核心数: {os.cpu_count()}")
pid 是当前进程编号,ppid 是父进程编号。os.getpid()、os.getppid() 常用于确认代码到底运行在哪个进程里。
创建子进程
import os
import time
from multiprocessing import Process
def speak():
for index in range(5):
print(f"说话 {index}, pid={os.getpid()}")
time.sleep(1)
def study():
for index in range(5):
print(f"学习 {index}, pid={os.getpid()}")
time.sleep(1)
if __name__ == "__main__":
print(f"主进程 pid={os.getpid()}") # 创建 Process 对象时,只是描述“未来要创建一个子进程”。
# 此时操作系统还没有真正启动子进程。
p1 = Process(target=speak)
p2 = Process(target=study) # start() 才是真正向操作系统申请启动子进程。
p1.start()
p2.start() print("主进程继续执行")
这里的重点:
Process(target=speak):指定子进程启动后执行哪个函数。start():真正启动子进程。- 子进程启动后,操作系统会调度它运行。
Process 常见参数可以这样看:
Process(
group=None, # 保留参数,基本固定写 None,日常不用管
target=handle_order, # 子进程启动后要执行的函数
name="order-worker", # 进程名称,方便日志和调试;不传时 Python 自动生成
args=(1001,), # 传给 target 的位置参数,必须是元组或类似序列
kwargs={"debug": True}, # 传给 target 的关键字参数,字典
daemon=False, # 是否为守护进程;必须在 start() 前设置
)
新手最常用的是 target 和 args:
p = Process(target=handle_order, args=(1001,))
如果参数很多,或者想让调用更清晰,可以用 kwargs:
p = Process(
target=handle_order,
kwargs={
"order_id": 1001,
"user_name": "copyer",
},
)
需要注意:多进程要把参数传给另一个 Python 进程,所以 target 和传入参数通常要能被 Python 序列化。普通函数、字符串、数字、列表、字典通常没问题;临时写在局部作用域里的函数、复杂连接对象、打开中的文件对象就容易出问题。
为什么必须写入口保护
多进程代码里经常看到:
if __name__ == "__main__":
...
这不是形式主义。
在 Windows 和 macOS 的某些启动方式下,创建子进程时,Python 会启动新的解释器进程,并重新导入当前 .py 文件。如果没有入口保护,子进程导入文件时又执行创建子进程的代码,就可能无限创建子进程。
所以多进程代码要养成习惯:
if __name__ == "__main__":
p = Process(target=speak)
p.start()
传参数
from multiprocessing import Process
def handle_order(order_id, user_name):
print(f"处理订单: {order_id}, 用户: {user_name}")
if __name__ == "__main__":
p = Process(
target=handle_order,
args=(1001, "copyer"),
) p.start()
p.join()
args 必须是元组。只有一个参数时,要写成:
args=(1001,)
join:让当前进程等待子进程
import time
from multiprocessing import Process
def work(name, seconds):
print(f"{name} 开始")
time.sleep(seconds)
print(f"{name} 结束")
if __name__ == "__main__":
p1 = Process(target=work, args=("任务 A", 2))
p2 = Process(target=work, args=("任务 B", 3)) p1.start()
p2.start() # join 不是让 p1 等。
# join 是让执行这行代码的主进程等待 p1。
p1.join()
p2.join() print("两个子进程都结束了")
这里有一个很容易说错的点:p.join() 不是让进程 p 等,而是让“执行 join 这行代码的进程”等。
如果你这样写:
p1.start()
p1.join()
p2.start()
p2.join()
效果就是 p1 完成后才启动 p2,并发效果就没了。
更常见写法是:
p1.start()
p2.start()p1.join()
p2.join()
terminate:强制终止子进程
import time
from multiprocessing import Process
def long_task():
while True:
print("任务执行中")
time.sleep(1)
if __name__ == "__main__":
p = Process(target=long_task)
p.start() time.sleep(3) # 强制终止。
# 生产环境要谨慎,因为可能导致文件、锁、数据库连接没有正常释放。
p.terminate()
p.join() print("子进程已经终止")
terminate() 是暴力中止,不是优雅退出。实际开发里,如果任务涉及写文件、写数据库、释放锁,要优先设计“退出信号”,让任务自己收尾。
守护进程
守护进程依附于主进程。主进程结束时,守护进程会跟着结束。
import time
from multiprocessing import Process
def monitor():
while True:
print("后台监控中")
time.sleep(1)
if __name__ == "__main__":
p = Process(target=monitor) # 必须在 start() 之前设置。
p.daemon = True
p.start() time.sleep(3)
print("主进程结束")
守护进程适合后台陪跑任务,例如简单监控、日志采样。不适合必须完整执行的核心业务,因为主进程一结束,它可能来不及收尾。
进程之间默认不共享变量
from multiprocessing import Processcount = 0
def add():
global count
count += 1
print(f"子进程里的 count: {count}")
if __name__ == "__main__":
p1 = Process(target=add)
p2 = Process(target=add) p1.start()
p2.start()
p1.join()
p2.join() print(f"主进程里的 count: {count}")
你可能以为主进程最后打印 2,但它通常还是 0。
原因是:
主进程有自己的 count。
子进程 p1 有自己的 count 副本。
子进程 p2 有自己的 count 副本。
它们不是同一块内存。
如果进程之间要交换数据,要使用通信机制。
四、进程通信
进程之间不共享普通变量,所以需要专门的通信方式。
Queue
Queue 是队列,特点是先进先出。
put、get、empty、full、put_nowait、get_nowait 都属于队列操作。
import time
from multiprocessing import Process, Queue
def producer(queue):
for order_id in range(1, 6):
print(f"生产订单: {order_id}") # put:把数据放进队列。
# 如果队列满了,默认会等待。
queue.put(order_id) time.sleep(0.5) # 用 None 作为结束标记。
queue.put(None)
def consumer(queue):
while True:
# get:从队列取数据。
# 如果队列为空,默认会等待。
order_id = queue.get() if order_id is None:
print("消费者收到结束标记")
break print(f"消费订单: {order_id}")
time.sleep(1)
if __name__ == "__main__":
queue = Queue() p1 = Process(target=producer, args=(queue,))
p2 = Process(target=consumer, args=(queue,)) p1.start()
p2.start() p1.join()
p2.join()
队列常见等待行为:
from multiprocessing import Queuequeue = Queue(3)queue.put(1)
queue.put(2)
queue.put(3)# 队列满了,继续 put 会等待。
# queue.put(4)# 最多等 2 秒。
# queue.put(4, timeout=2)# 不等待,放不进去就抛异常。
# queue.put_nowait(4)
读取也是类似:
# 队列为空时,默认等待。
# value = queue.get()# 最多等 2 秒。
# value = queue.get(timeout=2)# 不等待,没有数据就抛异常。
# value = queue.get_nowait()
实际开发中,不建议用 empty() 和 full() 做严肃业务判断,因为多进程环境下,刚判断完状态就可能被其他进程改变。
Pipe
Pipe 是管道,适合两个进程之间点对点通信。
import time
from multiprocessing import Pipe, Process
def receiver(conn):
print("接收方等待数据") # recv 会阻塞,直到另一端 send 数据。
data = conn.recv() print(f"接收方收到: {data}")
conn.close()
def sender(conn):
time.sleep(2) # send 把数据发送到管道另一端。
conn.send({"type": "ORDER_DONE", "order_id": 1001}) print("发送方发送完成")
conn.close()
if __name__ == "__main__":
# conn1 和 conn2 既可以是发送方,也可以是接收方,所以是双向的
conn1, conn2 = Pipe() p1 = Process(target=receiver, args=(conn1,))
p2 = Process(target=sender, args=(conn2,)) p1.start()
p2.start() p1.join()
p2.join()
默认 Pipe() 是双向的。如果只需要单向通信,可以写:
recv_conn, send_conn = Pipe(duplex=False)
Lock
进程之间虽然不共享普通变量,但可能同时操作同一个外部资源,比如同一个文件、同一个终端输出、同一条数据库记录。
这时需要锁。
这里就是需要使用 lock, 进入关键代码前手动 acquire(),执行完后手动 release()。
import time
from multiprocessing import Lock, Process
def write_log(lock, name):
for index in range(3):
# acquire 表示“我要开始独占这段代码了”。
# 如果另一个进程已经拿到锁,这里会等待。
lock.acquire() print(f"{name}: 开始写第 {index} 行", end=" ")
time.sleep(0.2)
print("写入中", end=" ")
time.sleep(0.2)
print("写完") # release 表示“我用完了,其他进程可以进来了”。
lock.release()
if __name__ == "__main__":
lock = Lock() p1 = Process(target=write_log, args=(lock, "进程 A"))
p2 = Process(target=write_log, args=(lock, "进程 B")) p1.start()
p2.start() p1.join()
p2.join()
这段代码能工作,但它有一个明显缺点:acquire() 和 release() 必须成对出现。中间代码一旦报错,release() 可能执行不到,锁就一直不释放,其他进程会一直等。
比如这种写法就有风险:
lock.acquire()
do_something()
lock.release()
如果 do_something() 抛异常,lock.release() 就可能不会执行。
所以更推荐写成 with lock:
import time
from multiprocessing import Lock, Processdef write_log(lock, name):
for index in range(3):
# with lock 等价于:
# 进入代码块时自动 acquire。
# 离开代码块时自动 release。
# 即使中途抛异常,也会尽量自动释放锁。
with lock:
print(f"{name}: 开始写第 {index} 行", end=" ")
time.sleep(0.2)
print("写入中", end=" ")
time.sleep(0.2)
print("写完")五、进程池
如果有 100 个任务,不应该手动创建 100 个进程。
创建进程有成本,进程太多也会增加操作系统调度压力。进程池就是提前准备固定数量的 worker 进程,然后把任务分配给它们。
先看整体流程:
创建进程池
-> 提交任务
-> 进程池把任务分给 worker 进程
-> 取回结果
-> 关闭进程池
可以把进程池的 API 可以分成三层:
第一层:进程池生命周期 with ProcessPoolExecutor(max_workers=3) as executor:
... # ProcessPoolExecutor:创建进程池
# max_workers:最多同时有几个 worker 进程干活
# with:代码块结束时自动 shutdown(wait=True)
# shutdown:不用 with 时才需要手动写
第二层:提交任务的两条路线 路线 A:executor.map(func, iterable)
-> 一次提交一批任务
-> 适合“同一个函数处理一批数据”
-> 返回结果顺序和输入顺序一致
-> 更像并发版本的 for 循环 路线 B:future = executor.submit(func, *args)
-> 一次提交一个任务
-> 立刻返回 Future
-> Future 是“未来会有结果的任务凭证”
第三层:处理 Future 的几种方式 future.result()
-> 主动等待这个任务完成
-> 拿这个任务的返回值 future.add_done_callback(fn)
-> 不主动等
-> 任务完成后自动调用 fn(future) as_completed(futures)
-> 传入一组 Future
-> 谁先完成,就先处理谁
map 路线:批量提交,按输入顺序取结果
map 适合这种场景:一个函数,要处理一批数据。它的返回结果顺序和输入顺序一致。
就比如一个偏计算的例子:统计几个大数字分别有多少个因子。这个过程一直在循环取余,CPU 会持续忙着算。
import os
from concurrent.futures import ProcessPoolExecutor
def count_factors(number):
count = 0 # 这段循环没有在等网络、等数据库、等文件。
# 它一直在做取余计算,所以属于偏 CPU 密集型。
for value in range(1, number + 1):
if number % value == 0:
count += 1 return {
"number": number,
"factor_count": count,
"pid": os.getpid(),
}
if __name__ == "__main__":
numbers = [120_000, 120_001, 120_002, 120_003, 120_004, 120_005] with ProcessPoolExecutor(max_workers=3) as executor:
# 最多同时使用 3 个 worker 进程。
# 每个 worker 进程都有自己的 pid。
# 对 CPU 计算来说,多进程更容易用上多个 CPU 核心。
results = executor.map(count_factors, numbers) print(list(results))
max_workers=3 表示最多同时有 3 个 worker 进程执行任务。
submit + Future
submit 和 map 不一样。
map
-> 一次提交一批任务
-> 更像并发版本的 for 循环submit
-> 一次提交一个任务
-> 立刻返回 Future
Future 可以先理解成“未来会有结果的任务凭证”:
executor.submit(...)
-> 任务已经交给进程池
-> 现在先拿到 Future
-> 之后用 future.result() 取结果
from concurrent.futures import ProcessPoolExecutor
def square(n):
return n * n
if __name__ == "__main__":
with ProcessPoolExecutor(max_workers=3) as executor:
# submit 只负责提交任务,不会马上给你最终结果。
future = executor.submit(square, 10) # result 会等待任务完成,并拿到返回值。
result = future.result() print(result)
add_done_callback:任务完成后自动回调
如果你不想只靠 future.result() 主动等待,也可以给 Future 添加完成回调。
from concurrent.futures import ProcessPoolExecutor
def square(n):
return n * n
def handle_done(future):
# 回调函数会收到 future 自己。
# 任务正常完成时,可以用 result() 拿返回值。
print(f"任务完成,结果是: {future.result()}")
if __name__ == "__main__":
with ProcessPoolExecutor(max_workers=3) as executor:
future = executor.submit(square, 10) # add_done_callback 不会立刻执行 handle_done。
# 它只是登记一个回调:等 future 完成后再调用。
future.add_done_callback(handle_done)
回调函数必须能接收一个 future 参数。如果任务本身抛异常,在回调里调用 future.result() 时也会重新抛出这个异常。
as_completed:按完成顺序取结果
as_completed 适合这种场景:你提交了多个任务,不关心输入顺序,只想谁先完成就先处理谁。
它和 submit 是一组常见搭配:
submit 多个任务
-> 得到多个 Future
-> as_completed(futures)
-> 谁先完成,先返回谁
下面这段代码只演示 as_completed 的取结果顺序。
import time
from concurrent.futures import ProcessPoolExecutor, as_completed
def work(seconds):
time.sleep(seconds)
return f"睡了 {seconds} 秒"
if __name__ == "__main__":
with ProcessPoolExecutor(max_workers=3) as executor:
futures = [
executor.submit(work, 3),
executor.submit(work, 1),
executor.submit(work, 2),
] # 谁先完成,先处理谁。
for future in as_completed(futures):
print(future.result())
map 注重输入顺序,as_completed 注重完成顺序。
shutdown:关闭进程池
进程池用完后要关闭,否则 worker 进程和相关资源可能不能及时释放。
日常最推荐用 with,因为它会自动调用 shutdown(wait=True):
from concurrent.futures import ProcessPoolExecutor
def work(item):
return item * 2
if __name__ == "__main__":
# 进入 with:创建进程池。
with ProcessPoolExecutor(max_workers=3) as executor:
results = executor.map(work, [1, 2, 3, 4])
print(list(results)) # 离开 with:自动 shutdown(wait=True)。
如果不用 with,就要自己调用 shutdown():
from concurrent.futures import ProcessPoolExecutor
def work(item):
return item * 2
if __name__ == "__main__":
executor = ProcessPoolExecutor(max_workers=3) try:
results = executor.map(work, [1, 2, 3, 4])
print(list(results))
finally:
# 手动关闭进程池。
# wait=True 表示等待已经提交的任务执行完再真正退出。
executor.shutdown(wait=True)
进程池关闭后,不能再继续 submit 或 map 新任务。
六、线程
线程是进程内部的执行单元。一个进程至少有一个主线程,也可以创建多个子线程。
线程和进程最大的区别之一是:同一进程内的线程共享内存。
进程 A
├── 线程 1
├── 线程 2
└── 线程 3这三个线程可以访问进程 A 的同一批对象和变量。
这带来两个结果:
- 共享数据方便。
- 多线程同时改同一份数据时,需要考虑锁。
新手可以先把线程理解成“同一个办公室里的多个办事员”。他们共用一张桌子上的资料,所以传数据方便;但如果同时改同一张表,就容易把数据改乱。
在语法层面上,基本跟进程差不多。
创建线程
import os
import time
from threading import Thread, get_native_id
def speak():
for index in range(5):
print(
f"说话 {index}, "
f"pid={os.getpid()}, "
f"thread={get_native_id()}"
)
time.sleep(1)
def study():
for index in range(5):
print(
f"学习 {index}, "
f"pid={os.getpid()}, "
f"thread={get_native_id()}"
)
time.sleep(1)
if __name__ == "__main__":
print(f"主线程 pid={os.getpid()}, thread={get_native_id()}") t1 = Thread(target=speak)
t2 = Thread(target=study) t1.start()
t2.start() t1.join()
t2.join() print("两个线程执行完")
运行后你会发现:
pid 通常相同。
thread id 不同。
这说明它们属于同一个进程里的不同线程。
Thread 常见参数和 Process 很像:
Thread(
group=None, # 保留参数,基本固定写 None,日常不用管
target=fetch_user, # 子线程启动后要执行的函数
name="fetch-worker", # 线程名称,方便日志和调试;不传时 Python 自动生成
args=(1001,), # 传给 target 的位置参数,元组
kwargs={"debug": True}, # 传给 target 的关键字参数,字典
daemon=False, # 是否为守护线程;必须在 start() 前设置
)
新手最常用的还是 target 和 args:
t = Thread(target=fetch_user, args=(1001,))
如果想在日志里区分线程,可以设置 name:
t = Thread(
target=fetch_user,
args=(1001,),
name="fetch-user-1001",
)
daemon=True 表示守护线程。主程序结束时,守护线程不会阻止程序退出。它适合一些后台辅助任务,但不适合必须完整保存数据、写文件、提交数据库的任务。
线程锁
因为线程共享内存,所以多个线程可能同时修改同一个变量。
from threading import Lock, Threadcount = 0
lock = Lock()
def add_many_times():
global count for _ in range(100_000):
# 同一时刻只允许一个线程进入这个代码块。
with lock:
count += 1
if __name__ == "__main__":
t1 = Thread(target=add_many_times)
t2 = Thread(target=add_many_times) t1.start()
t2.start() t1.join()
t2.join() print(count)
锁保护的是临界区,也就是不能被多个线程同时执行的那段关键代码。
Lock 和 RLock 的区别:
Lock
-> 普通锁
-> 同一个线程拿到锁后,不能再次拿同一把锁
-> 如果重复 acquire,自己也会把自己卡住RLock
-> 可重入锁
-> 同一个线程拿到锁后,可以再次拿同一把锁
-> acquire 几次,就要 release 几次
先看 Lock 容易卡住的情况:
from threading import Locklock = Lock()
def inner():
# outer 已经拿着 lock。
# 这里再次获取同一把普通 Lock,会一直等自己释放自己。
with lock:
print("inner")
def outer():
with lock:
print("outer")
inner()
outer()
这段代码的问题不是有两个线程抢锁,而是同一个线程重复进入了同一把普通锁。
这种情况下可以用 RLock:
from threading import RLocklock = RLock()
def inner():
# RLock 允许同一个线程重复拿同一把锁。
with lock:
print("inner")
def outer():
with lock:
print("outer")
inner()
outer()
但不要一上来就把所有 Lock 都换成 RLock。大多数场景用 Lock 更直接;只有当“同一个线程可能在函数嵌套调用里重复进入同一把锁”时,才考虑 RLock。
multiprocessing 里也有 Lock 和 RLock,核心区别类似:Lock 不可重入,RLock 可重入。
线程池
和进程池的用法基本一致。
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
def fetch_user(user_id):
print(f"开始请求用户 {user_id}") # 模拟网络 I/O 等待。
# 真实项目里这里可能是 requests.get(...)、数据库查询、读文件等。
# 等待期间 CPU 没有一直忙着计算,所以适合用线程池并发等待。
time.sleep(1) return {"id": user_id, "name": f"user-{user_id}"}
if __name__ == "__main__":
user_ids = [1, 2, 3, 4, 5] with ThreadPoolExecutor(max_workers=3) as executor:
# 把 5 个用户查询任务交给线程池。
# max_workers=3 表示同一时间最多 3 个线程在处理。
futures = [
executor.submit(fetch_user, user_id)
for user_id in user_ids
] # as_completed 会按“谁先完成”返回结果。
# 这适合接口请求:哪个接口先回来,就先处理哪个结果。
for future in as_completed(futures):
print(future.result())
这个场景是 I/O 密集型:线程大部分时间在等接口返回,不是在持续占用 CPU。
七、GIL
先来看两个案例:
先看“下载文件”。
假设有 3 个图片要下载:
图片 A:等服务器返回 3 秒
图片 B:等服务器返回 2 秒
图片 C:等服务器返回 1 秒
如果只有 1 个线程,它大概会这样:
线程 1
-> 下载 A,等 3 秒
-> 下载 B,等 2 秒
-> 下载 C,等 1 秒总时间接近 3 + 2 + 1 秒
如果用 3 个线程,它大概会这样:
线程 1 -> 下载 A,等待服务器
线程 2 -> 下载 B,等待服务器
线程 3 -> 下载 C,等待服务器总时间更接近最慢的那个任务,也就是 3 秒
这里多线程有用,是因为线程大部分时间都在“等别人”。等待网络、数据库、磁盘时,CPU 没有一直忙着执行 Python 代码。一个线程在等,程序就可以切到另一个线程继续推进。
再看“做计算”。
假设有 3 个很重的计算任务:
任务 A:一直循环计算
任务 B:一直循环计算
任务 C:一直循环计算
这些任务不是在等别人,而是一直需要 CPU 执行 Python 代码。如果你把它们放到同一个 Python 进程的多个线程里,大概是这种感觉:
一个 Python 进程
线程 1:想执行 Python 计算
线程 2:想执行 Python 计算
线程 3:想执行 Python 计算但同一时刻通常只有一个线程能真正执行 Python 字节码。
这就是 GIL 要解释的现象。
GIL 是 Global Interpreter Lock,可以先理解成“同一个 Python 进程里执行 Python 代码的通行证”。一个线程想执行 Python 字节码,通常要先拿到这张通行证。
同一个 Python 进程里:线程 1 拿到 GIL
-> 线程 1 执行 Python 代码线程 2 没拿到 GIL
-> 线程 2 先等线程 3 没拿到 GIL
-> 线程 3 先等
所以对于纯 Python CPU 计算,多线程经常不是“3 个线程同时在 3 个 CPU 核心上疯狂计算”。更常见的是:多个线程轮流拿到执行 Python 代码的机会。
这就是为什么前面一直说:
任务主要在等
-> 多线程有意义
-> 因为等待期间可以切到别的线程任务主要在算
-> 多线程不一定能加速
-> 因为同一个进程里会受到 GIL 限制
那为什么“算”更常用多进程?
因为多进程不是在同一个 Python 进程里抢同一把 GIL。每个进程都有自己的 Python 解释器,也有自己的 GIL。
进程 A
-> 自己的 Python 解释器
-> 自己的 GIL
-> 可以在一个 CPU 核心上算进程 B
-> 自己的 Python 解释器
-> 自己的 GIL
-> 可以在另一个 CPU 核心上算
所以对新手来说,可以先这样记:
下载、请求接口、查数据库、读写文件
-> 大量时间在等
-> 线程有用循环计算、图片压缩、视频处理、加密压缩
-> 大量时间在算
-> 多进程更常见
这里说的是普通 CPython,也就是最常用的 Python 解释器实现。以后你可能会看到“free-threaded Python”“某些 C 扩展释放 GIL”这类说法,那是更进阶的情况。刚开始先按上面的判断就够了。
最后注意:GIL 和你自己写的 Lock / RLock 不是一回事。
GIL
-> Python 解释器内部的锁
-> 主要影响同一进程里多个线程执行 Python 字节码
-> 程序员通常不手动控制Lock / RLock
-> 你自己创建的业务锁
-> 用来保护库存、余额、文件写入、共享变量这类业务数据
-> 由你决定锁哪里、什么时候释放
所以不要因为有 GIL 就不加业务锁。GIL 不会替你保证库存、余额、文件写入这些业务数据一定正确。
八、协程
协程这一块最容易误解成“和线程差不多,都是等的时候切换”。这个感觉没有错,但还不够准确。
线程和协程都能在等待时推进别的任务,区别在于谁负责切换:
线程:
-> 由操作系统调度
-> 每个线程都有自己的执行栈
-> 线程多了,创建、切换、内存成本都会上来协程:
-> 由程序里的事件循环调度
-> 通常在一个线程里运行很多个任务
-> 只有遇到 await,当前任务才主动让出执行权
所以协程的实际意义不是“发明了一种新的等待”,而是:
用更少的线程,管理大量正在等待的 I/O 任务。
把它想成一个窗口工作人员。
普通同步代码像这样:
工作人员只处理订单 A
-> A 要等接口返回
-> 工作人员站着等 A
-> A 回来后,才处理订单 B
-> B 回来后,才处理订单 C
协程像这样:
工作人员处理订单 A
-> A 要等接口返回
-> A 在 await 这里暂停
-> 工作人员先去处理订单 B订单 B 也要等
-> B 在 await 这里暂停
-> 工作人员再去处理订单 C哪个订单的接口先回来
-> 工作人员再回到那个订单继续处理
这里的“工作人员”就是事件循环,await 就是任务主动说:“我现在要等外部结果,你先去处理别的任务。”
这和线程的区别是:
线程模型:
多个工作人员
每个人等一个窗口协程模型:
一个工作人员
同时跟进很多张等待中的单子
只在 await 这些明确的等待点切换
所以协程适合这种任务:
请求很多接口
查很多数据库
维护很多连接
等待很多文件或网络结果
它不适合用来加速纯 CPU 计算。因为 CPU 计算没有在等外部结果,也就没有多少机会通过 await 把执行权让出去。
什么时候用线程,什么时候用协程
先不要只看“任务多不多”,更关键的是看你调用的库是什么类型。
用线程:
-> 你调用的是同步阻塞库
-> 例如 requests、普通文件读写、同步数据库驱动
-> 这些库没有 await 写法
-> 把它们放到线程里等,主流程就不用一直卡着用协程:
-> 你调用的是异步库
-> 例如 aiohttp、httpx.AsyncClient、异步数据库驱动
-> 这些库本身支持 await
-> 一个事件循环就能管理大量等待任务
看两个最常见的写法对比:
# 同步库:没有 await,只能阻塞等待。
# 这种任务如果要并发处理,通常交给线程池。
def fetch_by_thread(url):
response = requests.get(url)
return response.text
# 异步库:请求时可以 await。
# 当前协程等待网络结果时,事件循环可以去调度其他协程。
async def fetch_by_coroutine(client, url):
response = await client.get(url)
return response.text
不要为了用协程而用协程。如果项目里全是同步阻塞库,把代码硬改成 async def,但里面没有真正的 await 等待点,事件循环还是会被卡住。
先认识四个核心动作
async def
-> 定义协程函数
-> 它描述“这个任务可以暂停和恢复”协程函数()
-> 只会得到一个协程对象
-> 不会立刻执行函数体asyncio.run(main())
-> 启动事件循环
-> 让 asyncio 开始调度协程await
-> 当前协程遇到等待点
-> 暂停当前协程
-> 把执行权交回事件循环
-> 等待完成后,再从暂停的位置继续
最小例子:先跑通一个协程
下面这个例子只能帮你认识语法。它只有一个任务,所以还体现不出协程的价值。
import asyncio
async def work():
print("work 开始") # asyncio.sleep 是异步等待。
# 当前协程会暂停 1 秒,但事件循环没有被卡死。
await asyncio.sleep(1) print("work 结束")
return "工作结果"
async def main():
# await work() 会执行 work。
# 当 work 内部 await 等待时,main 也会暂停等待结果。
result = await work()
print(result)
# asyncio.run 是入口。
# 没有它,协程不会真正跑起来。
asyncio.run(main())
简单理解:
async def work()
-> 定义协程函数work()
-> 得到协程对象,不是立刻执行await work()
-> 执行并等待这个协程完成asyncio.run(main())
-> 启动事件循环,运行入口协程
对比:顺序等待和协程并发等待
先看顺序等待。三个接口一个个请求:
import asyncio
async def request_api(name, seconds):
print(f"{name} 开始请求") # 用 sleep 模拟接口等待。
# 真实项目里这里通常是异步 HTTP 请求、异步数据库查询等。
await asyncio.sleep(seconds) print(f"{name} 请求完成")
return f"{name} 的响应"
async def main():
# 这里是顺序等待。
# 接口 A 完成后,才会开始接口 B。
# 接口 B 完成后,才会开始接口 C。
result1 = await request_api("接口 A", 2)
result2 = await request_api("接口 B", 1)
result3 = await request_api("接口 C", 3) print(result1, result2, result3)
asyncio.run(main())
这段代码大概要等:
接口 A 2 秒
+ 接口 B 1 秒
+ 接口 C 3 秒
= 接近 6 秒
现在改成协程并发等待:
import asyncio
async def request_api(name, seconds):
print(f"{name} 开始请求")
await asyncio.sleep(seconds)
print(f"{name} 请求完成")
return f"{name} 的响应"
async def main():
# create_task 会把协程包装成 Task,并交给事件循环调度。
# 这三行执行后,A、B、C 都开始等待。
task1 = asyncio.create_task(request_api("接口 A", 2))
task2 = asyncio.create_task(request_api("接口 B", 1))
task3 = asyncio.create_task(request_api("接口 C", 3)) # await task 不是重新执行任务。
# 它只是等待这个已经启动的任务完成,并拿到结果。
result1 = await task1
result2 = await task2
result3 = await task3 print(result1, result2, result3)
asyncio.run(main())
这段代码大概要等:
接口 A、B、C 同时开始等待
-> B 大约 1 秒后回来
-> A 大约 2 秒后回来
-> C 大约 3 秒后回来总时间更接近最慢的 C,也就是 3 秒
这就是协程的意义:不是把某一个接口变快,而是在一个接口等待时,先去推进其他接口。
gather:同时等一组任务,按传入顺序拿结果
如果你的需求是“这几个任务都跑起来,最后一起拿结果”,gather 更简洁。
import asyncio
async def request_api(name, seconds):
await asyncio.sleep(seconds)
return f"{name} 完成"
async def main():
results = await asyncio.gather(
request_api("接口 A", 2),
request_api("接口 B", 1),
request_api("接口 C", 3),
) # gather 返回结果的顺序,和传入顺序一致。
print(results)
asyncio.run(main())
create_task 和 gather 可以这样区分:
create_task
-> 先把一个协程启动成任务
-> 你后面可以单独 await 它gather
-> 同时等待一组协程或任务
-> 最后一次性拿到结果列表
as_completed:谁先完成,先处理谁
如果你不关心传入顺序,而是想接口谁先回来就先处理谁,用 as_completed。
import asyncio
async def request_api(name, seconds):
await asyncio.sleep(seconds)
return f"{name} 完成"
async def main():
tasks = [
asyncio.create_task(request_api("接口 A", 2)),
asyncio.create_task(request_api("接口 B", 1)),
asyncio.create_task(request_api("接口 C", 3)),
] # 谁先完成,as_completed 就先给谁。
for task in asyncio.as_completed(tasks):
result = await task
print(result)
asyncio.run(main())
简单对比:
gather
-> 等全部完成
-> 按传入顺序返回结果as_completed
-> 谁先完成先处理谁
-> 适合“结果一回来就要处理”的场景
不要在协程里写阻塞代码
协程能切换的前提是:是在 async def 代码中写的是异步等待,而不是普通的阻塞代码。
错误示范:
import time
async def bad_work():
# time.sleep 是同步阻塞等待。
# 它会卡住整个事件循环。
time.sleep(3)
应该写:
import asyncio
async def good_work():
# asyncio.sleep 是异步等待。
# 当前协程暂停时,事件循环还能调度其他协程。
await asyncio.sleep(3)
网络请求也是一样。requests 是同步阻塞库,不适合直接放在 async def 里大量调用。异步 HTTP 通常使用 httpx.AsyncClient 或 aiohttp。
限制并发数量
协程适合大量 I/O,但不能无限制地同时发起任务。比如一次性发起 5000 个请求,可能压垮自己,也可能压垮对方服务。
这时用 Semaphore 控制同一时间最多有多少个协程进入关键区域。
import asyncio
async def fetch(index):
await asyncio.sleep(1)
return f"第 {index} 个请求完成"
async def limited_fetch(semaphore, index):
# async with semaphore 表示:
# 同一时刻最多允许固定数量的协程进入这里。
async with semaphore:
return await fetch(index)
async def main():
# 最多同时执行 5 个请求。
semaphore = asyncio.Semaphore(5) tasks = [
limited_fetch(semaphore, index)
for index in range(20)
] results = await asyncio.gather(*tasks)
print(results)
asyncio.run(main())
Queue:协程之间传递任务
如果一个协程负责生产任务,另一个协程负责处理任务,可以用 asyncio.Queue。
producer
-> 把订单放进 queueconsumer
-> 从 queue 里取订单处理
示例:
import asyncio
async def producer(queue):
for order_id in range(1, 6):
print(f"生产订单: {order_id}") # put 是异步的。
# 如果队列满了,producer 会在这里等待。
await queue.put(order_id)
await asyncio.sleep(0.2) # 用 None 当结束信号。
await queue.put(None)
async def consumer(queue):
while True:
# get 是异步的。
# 如果队列为空,consumer 会在这里等待。
order_id = await queue.get() if order_id is None:
print("消费者结束")
queue.task_done()
break print(f"处理订单: {order_id}")
await asyncio.sleep(0.5) # 告诉队列:刚才 get 出来的任务处理完了。
queue.task_done()
async def main():
queue = asyncio.Queue() await asyncio.gather(
producer(queue),
consumer(queue),
)
asyncio.run(main())
协程里的 asyncio.Queue 和多进程的 multiprocessing.Queue 不是同一个东西,但它们都可以表达“生产者消费者”模型。
九、常见坑
把并发当成并行
协程可以高并发,但不是多核并行计算。纯 CPU 计算放进协程里,不会神奇变快。
在 async 函数里写阻塞代码
async def bad():
time.sleep(3)
这会卡住事件循环。
多进程忘记入口保护
if __name__ == "__main__":
...
多进程程序尤其要写。
以为进程之间共享普通变量
普通变量不会自动跨进程共享。要通信就用 Queue、Pipe、数据库、Redis、消息队列等。
锁拿了不释放
lock.acquire()
do_something()
lock.release()
如果 do_something() 抛异常,release() 可能执行不到。更推荐:
with lock:
do_something()
线程越多越快
线程太多会增加调度成本、内存压力和上下文切换。线程池、进程池都要设置合理的 max_workers。
没有限制协程并发
一次性发起几千个请求,可能压垮自己或对方服务。用 Semaphore、连接池、限流策略控制压力。
十、最后怎么记
进程:
操作系统分配资源的基本单位。
内存隔离,通信成本高。
适合 CPU 密集型、隔离要求高的任务。线程:
操作系统调度 CPU 的基本单位。
同一进程内线程共享内存。
适合同步阻塞 I/O,但共享数据要加锁。协程:
用户态的可暂停、可恢复执行单元。
由事件循环调度,创建和切换成本低。
适合高并发 I/O,前提是使用异步库。并发:
一段时间内多个任务都在推进。并行:
同一时刻多个任务真的在不同 CPU 核心执行。同步:
发起任务后,等它完成再继续。异步:
发起任务后,不必一直等在原地,完成后再取结果。
真正写代码时,优先按这个顺序思考:
任务主要是在算,还是在等?
任务之间有没有依赖?
任务之间要不要共享数据?
任务数量会不会很多?
失败后要不要重试?
是否需要跨机器执行?
想清楚这些,再选择进程、线程、协程,才不会被 API 牵着走。
相关文章
- 《明日方舟》精一50级升80级需要多少经验-50级升到80级经验与龙门币需求分析 08-01
- 王者荣耀世界王昭君有什么技能 王昭君技能效果介绍 08-01
- Namo-Turn-Detector-v1-Korean 项目介绍:GitCode 开源模型信息整理 08-01
- 个人所得税退税申请时间是何时 08-01
- 明日方舟早露常伴我身皮肤详情 08-01
- 蛋仔派对绯梦佩姬获取方法一览 08-01