



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
使用JavaScript实现在线PDF压缩工具
时间:2026-06-08 08:32:54 编辑:袖梨 来源:一聚教程网
这篇只讲本项目里“PDF压缩”工具的功能层 JavaScript 实现。整个链路可以概括为:
选择 PDF -> 解析压缩参数 -> 读取并加载 PDF -> 找出可重压缩的 JPEG 图片流 -> 重新编码 -> 生成新 PDF -> 下载结果
这个工具的核心思路很明确:不直接“重写整个 PDF”,而是优先处理 PDF 内已经存在的 JPEG 图片资源,再把处理后的内容重新保存成新的 PDF 文件。
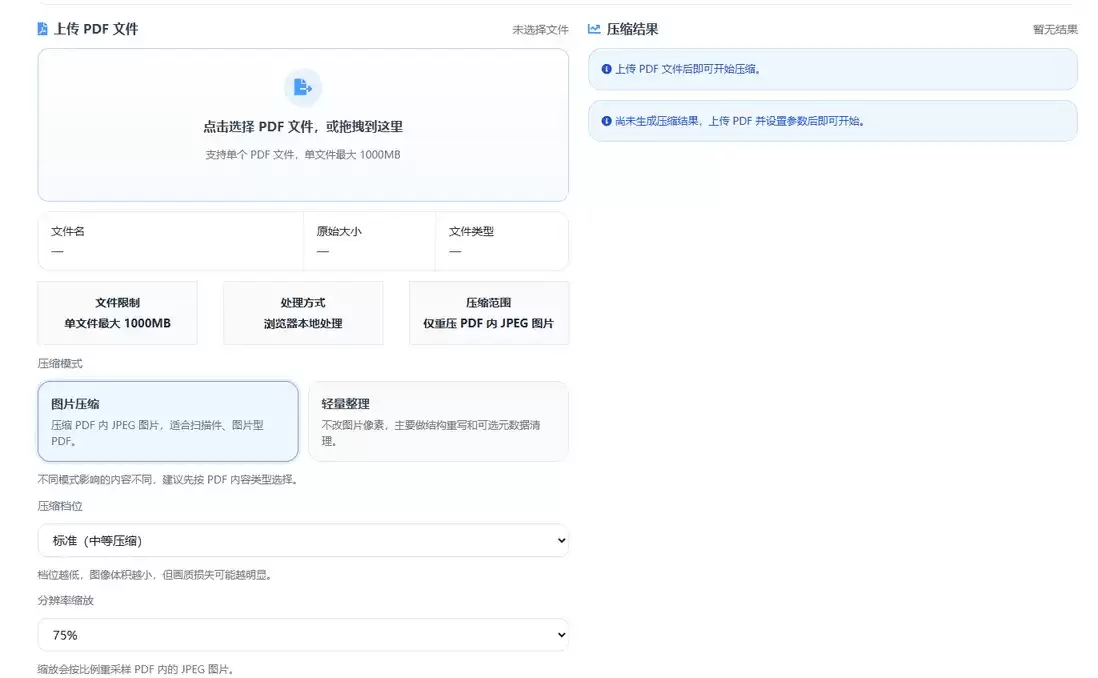
1. 参数先归一化,避免压缩流程分支失控
工具支持两种模式:jpeg-only 和 condense-lite。前者真正处理 PDF 内图片,后者主要做轻量整理。压缩前会先把算法、画质和缩放比例统一成稳定值。
function resolveAlgorithm(algorithm) { if (algorithm === PDF_COMPRESS_ALGORITHM_CONDENSE_LITE) { return PDF_COMPRESS_ALGORITHM_CONDENSE_LITE; } return PDF_COMPRESS_ALGORITHM_JPEG_ONLY;}function resolveQuality(level) { return QUALITY_MAP[level] || QUALITY_MAP.medium;}function resolveScale(scale) { var value = Number(scale); if (!Number.isFinite(value) || value <= 0 || value > 1) { return 1; } return value;}这样做的好处是,后面的压缩主流程只接收规范参数,不需要到处判断非法输入。
2. 先从 PDF 里筛出真正可压缩的 JPEG 图片流
PDF 里并不是所有资源都适合压缩。实现里会遍历 PDF 的间接对象,只保留同时满足这几个条件的对象:
- 类型是
XObject - 子类型是
Image - 过滤器里包含
DCTDecode
function listJpegStreams(pdfDoc) { var imageStreams = []; var entries = pdfDoc.context.enumerateIndirectObjects(); for (var i = 0; i < entries.length; i += 1) { var obj = entries[i][1]; if (!(obj instanceof PDFRawStream)) continue; var dict = obj.dict; var type = dict.get(PDFName.of("Type")); var subtype = dict.get(PDFName.of("Subtype")); var filter = dict.get(PDFName.of("Filter")); var filterText = filter ? String(filter.toString()) : ""; if (String(type || "") !== "/XObject") continue; if (String(subtype || "") !== "/Image") continue; if (filterText.indexOf("DCTDecode") === -1) continue; imageStreams.push({ obj: obj }); } return imageStreams;}这里的关键点是只处理 JPEG 流。这样可以避开很多复杂格式分支,让压缩行为更可控。
3. 图片重压缩的核心是“转成位图再重新编码”
拿到 JPEG 字节后,不是直接改二进制,而是走浏览器图像链路:Blob -> ObjectURL -> Image -> Canvas -> toBlob。
function recompressJpegBytes(bytes, scale, quality) { return new Promise(function (resolve) { var blob = new Blob([bytes], { type: "image/jpeg" }); var objectUrl = URL.createObjectURL(blob); var image = new Image(); image.onload = function () { var width = Math.max(1, Math.floor(image.width * scale)); var height = Math.max(1, Math.floor(image.height * scale)); var canvas = document.createElement("canvas"); var context = canvas.getContext("2d"); canvas.width = width; canvas.height = height; context.fillStyle = "#FFFFFF"; context.fillRect(0, 0, width, height); context.drawImage(image, 0, 0, width, height); canvas.toBlob(function (nextBlob) { URL.revokeObjectURL(objectUrl); if (!nextBlob) return resolve(null); nextBlob.arrayBuffer().then(function (buffer) { resolve({ buffer: new Uint8Array(buffer), width: width, height: height, }); }); }, "image/jpeg", quality); }; image.src = objectUrl; });}这一步决定了压缩效果:
quality控制 JPEG 输出质量scale控制像素尺寸缩放fillRect + drawImage保证重新绘制后的图像能稳定导出
4. 主流程按“读文件、扫图片、替换流、保存结果”推进
真正的入口函数是 compressPdfFile。它会先读取文件,再用 pdf-lib 加载 PDF,然后根据模式决定是否遍历 JPEG 图片流。
var originalBytes = await file.arrayBuffer();var pdfDoc = await PDFDocument.load(originalBytes, { updateMetadata: false,});var jpegStreams = listJpegStreams(pdfDoc);for (var i = 0; i < jpegStreams.length; i += 1) { var stream = jpegStreams[i].obj; var streamBytes = stream.contents; var converted = await recompressJpegBytes(streamBytes, scale, quality); if ( converted && converted.buffer && converted.buffer.byteLength < streamBytes.byteLength ) { stream.contents = converted.buffer; if (scale !== 1) { stream.dict.set(PDFName.of("Width"), pdfDoc.context.obj(converted.width)); stream.dict.set(PDFName.of("Height"), pdfDoc.context.obj(converted.height)); } }}这里有个很重要的判断:只有新图片字节更小,才会替换原始流。这样不会因为重复编码反而把文件变大。
5. 元数据清理是另一条独立压缩支线
除了图片重编码,这个工具还支持移除元数据。实现上会删除文档信息字典和目录上的 Metadata。
function stripPdfMetadata(pdfDoc) { var context = pdfDoc.context; var catalog = pdfDoc.catalog; var infoRef = context.trailerInfo.Info; if (infoRef) { context.delete(infoRef); context.trailerInfo.Info = undefined; } if (catalog && catalog.has(PDFName.of("Metadata"))) { catalog.delete(PDFName.of("Metadata")); }}这部分不依赖图片内容,所以即使 PDF 里没有可处理的 JPEG,仍然可能通过清理元数据得到更小的结果文件。
6. 进度、取消和结果信息都在同一条状态链上
页面层不是简单地调用一次压缩函数,而是把压缩过程拆成可感知的阶段:读取、解析、扫描图片、重编码、清理元数据、保存完成。
var result = await compressPdfFile( this.selectedFile, { algorithm: this.algorithm, quality: this.qualityLevel, scale: this.scaleValue, removeMetadata: this.removeMetadata, cancelToken: this.cancelToken, }, function (progress) { self.progressPercent = Math.max(0, Math.min(100, progress.percent || 0)); self.progressStage = String(progress.stage || ""); self.progressTotal = Number(progress.total) || 0; self.progressProcessed = Number(progress.processed) || 0; self.progressReplacedCount = Number(progress.replacedCount) || 0; },);取消机制也很直接,本质上是一个共享标记:
export function createPdfCompressCancelToken() { return { cancelled: false };}function throwIfCancelled(cancelToken) { if (cancelToken && cancelToken.cancelled) { throw createPdfCompressCancelledError(); }}压缩流程中的关键节点都会检查这个标记,这样用户点取消后,任务能在下一段异步边界及时停止。
7. 导出结果时顺手补齐“用户可理解”的信息
压缩完成后,工具不会只返回一个 Blob,还会把输出文件名、压缩前后体积、替换图片数量、压缩比例一起整理出来。
var result = { outputBlob: outputBlob, outputName: buildCompressedPdfName(file && file.name), jpegCount: jpegCount, replacedCount: replacedCount, metadataRemoved: metadataRemoved, originalSize: Number(file && file.size) || 0, outputSize: outputBlob.size, ratio: getPdfCompressionRatio(file && file.size, outputBlob.size), algorithm: algorithm,};这样页面层只需要接结果并创建下载链接,就能完整展示这次压缩是否生效、压缩了多少、实际处理了多少张图片。
这套 PDF 压缩功能的核心并不复杂,重点是把浏览器图像能力和 pdf-lib 的对象操作串起来:先定位 PDF 内可处理的 JPEG 资源,再重编码、替换、保存,最后把整个过程包装成普通用户可直接使用的 Vue 工具。
相关文章
- 《明日方舟》精一50级升80级需要多少经验-50级升到80级经验与龙门币需求分析 08-01
- 王者荣耀世界王昭君有什么技能 王昭君技能效果介绍 08-01
- Namo-Turn-Detector-v1-Korean 项目介绍:GitCode 开源模型信息整理 08-01
- 个人所得税退税申请时间是何时 08-01
- 明日方舟早露常伴我身皮肤详情 08-01
- 蛋仔派对绯梦佩姬获取方法一览 08-01