



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
RedKnot以头部感知KV复用突破长上下文服务瓶颈
时间:2026-06-07 09:14:01 编辑:袖梨 来源:一聚教程网
RedKnot系统以头部感知KV复用技术,突破了长上下文服务瓶颈。该方案来自arXiv最新研究(论文编号2606.06256v1),针对大语言模型服务中KV缓存占据大量GPU显存、影响并发与响应速度的问题,提出了一条新的优化路径。
KV缓存成为长上下文服务的核心制约
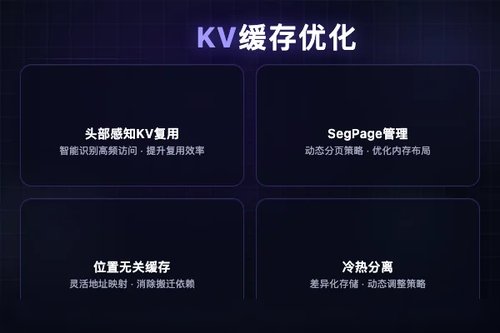
大语言模型处理长输入时,KV缓存的大小会随序列长度线性增长,很快占满GPU显存。这限制了单卡能服务的用户数量,也降低了缓存复用的效率。现有系统大多采用单一的KV缓存抽象,在位置无关缓存、前缀压缩、冷热数据分离和分布式管理等维度上缺乏灵活的优化手段。
头部感知KV复用的设计逻辑
RedKnot通过头部感知KV复用,让系统在缓存调度时能区分不同注意力头部的重要性,优先保留高频复用的缓存块。配合SegPage管理机制,缓存空间的划分更加精细,热数据与冷数据可以动态调整,避免了传统方法中“一刀切”的低效问题。
同时解决多个关联难题
在RedKnot的框架下,位置无关缓存让相同内容在不同上下文位置都能被复用;前缀压缩减少了重复内容的显存开销;冷热分离策略确保了高频访问块的优先驻留。这些能力都建立在头部感知KV复用与SegPage的基础之上,相互配合而非孤立设计。
从单一抽象到精细化管理的转变
传统KV缓存管理将整个缓存视为一个整体,难以针对不同访问模式做差异化处理。RedKnot的SegPage机制将缓存划分为更小的管理单元,让系统在内存分配、数据迁移和复用调度上有了更细的粒度控制。这种设计与头部感知KV复用结合,形成了从识别到调度再到存储的完整优化链路。
对长上下文服务的实际价值
随着大模型应用向更长上下文演进——从代码生成到多轮对话,从文档分析到复杂推理——KV缓存管理的效率直接影响服务的可用性和成本。RedKnot的方案在不改变模型架构的前提下,通过改进缓存管理层来释放性能,为AI基础设施的规模化部署提供了可行的技术方向。
相关文章
- 2026年Gemini进阶技巧:3种常见错误与排查步骤 06-07
- 怎么查询太平洋保险电子保单 06-07
- picopico如何眼熟访客 06-07
- 钓鱼人app怎么添加渔具店 06-07
- 2026年OpenAI工作流怎么搭建 3种方案对比 06-07
- Claude Code设计场景用法2026版 5个常见避坑 06-07