



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Scaling Search Relevance: Augmenting App Store Ranking with LLM-Generated Judgme
时间:2026-06-03 16:04:01 编辑:袖梨 来源:一聚教程网
arXiv日前发布了一项新研究,题为《Scaling Search Relevance: Augmenting App Store Ranking with LLM-Generated Judgme》,核心目标是用大语言模型生成的评价来优化应用商店的搜索相关性。研究指出,大型商业搜索引擎都在追求更高的相关性,帮助用户快速找到他们想要的内容。可是,光靠用户点击或下载这种行为数据还不够,文本层面的语义匹配也得跟上才行。
为什么偏偏要用大语言模型来干这事?
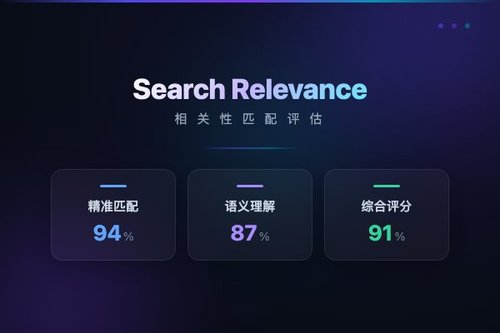
其实挺简单的,搜索优化向来有两个互补的目标:行为相关性和文本相关性。行为相关性看的是用户点了什么、下载了什么,这类标签好收集、量也大。但文本相关性就麻烦多了,它要判断一个结果跟查询的语义匹不匹配,这得靠专家来标注,成本高、量也少。那怎么补上这个短板呢?研究人员系统评估了各种大模型配置,发现LLM(也就是大语言模型)生成的评价可以作为有效的补充标签。
这不是正好解决了咱们日常搜索时的痛点吗?

想想看,在应用商店里搜一个词,翻了好几页都找不到想要的应用,那多半是文本相关性没对齐。LLM生成的判断能把查询和应用的语义理解得更到位,从而让排序模型学到更全面的相关性信号。这不就是提升搜索体验的关键一步?
研究还特别提到,他们对比了几种大模型配置,最终找到了一个挺靠谱的方案。这意味着不光理论可行,实际操作也有章可循。毕竟,应用商店的搜索结果直接关系到用户体验和开发者的收入,能多一个精准的评判维度,绝对是好事。
可以说,这项研究验证了在缺乏专家标注的场景下,LLM确实能派上用场。它给搜索相关性领域打开了一个新思路:让行为信号和文本信号之间不再偏科,而是互相补充。大家不妨期待一下,未来咱们在应用商店里找应用,会不会更顺心一些?