



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结构化推理使LLM能有效自我定位推理错误
时间:2026-06-02 18:42:01 编辑:袖梨 来源:一聚教程网
arXiv 一篇新研究揭示:结构化推理能让大语言模型(LLM,即像ChatGPT这样的对话式AI)更有效地自我定位推理错误。这项来自arXiv:2602.02416v2的研究,提出了一种将推理过程拆解为离散、语义连贯的思考步骤的方法,让模型在出错时能像人检查作业一样,精准揪出步骤中的逻辑漏洞。
为什么结构这么重要?

传统的链式思维(Chain-of-Thought)推理,虽然让模型能一步步思考,但就像一条太长、没有标记的绳子,其中某处一断,整个推理就崩了。模型自己根本说不清问题出在第几环。这项研究受人类大脑监控错误机制的启发——咱们的大脑在犯错后,能迅速定位到哪个环节出了岔子。LLM能做到类似的事吗?论文给出了一个挺有意思的答案。
结构化推理怎么做?
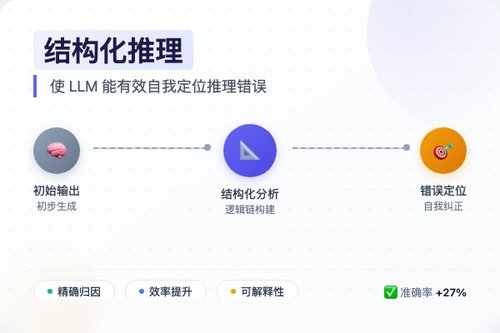
- 把复杂推理拆成一个个独立的、有语义意义的“思考步骤”,每个步骤就是一个明确的小结论。
- 每个步骤都像一个小模块,模型可以单独检查它的逻辑是否正确。
- 如果发现前后步骤矛盾,模型就能锁定出问题的那个步骤。
这就像咱们做数学题时,会先列出已知条件,再一步步设方程、求解。如果算错了,一看就知道是第三步代入公式时出了错。LLM用了这个法子,定位错误的能力一下子就提高了。
比传统方法强在哪?
论文对比了结构化推理与传统的无结构链式思维。结果很清楚:在结构化推理模式下,模型定位错误的准确率确实高出一大截。传统方法里,推理过程像一团乱麻,模型时常陷入“明明答案错了,但就是找不到原因”的窘境。而结构化之后,推理就像一条有路标的公路,哪里拐错了弯,一目了然。这难道不是LLM自我纠错能力的关键一步吗?
这算什么?通往自我纠错的密码?
自我纠错一直是LLM领域的难题。模型往往能发现答案是错的,却不会改,甚至越改越错。这项研究展示了:结构——明确、分解、语义化的步骤——是让LLM学会“自我诊断”的有效路径。说白了,就是先让模型学会“认错”,才能谈怎么“改错”。这为未来构建真正能有效自我修正的AI系统,铺垫了很重要的一块基石。
但问题来了:模型会主动用吗?
目前这项技术还属于prompt工程——需要人为引导模型使用结构化思考框架。模型本身不会自动切换到这个模式。不过,既然已经证明结构能有效定位推理错误,下一步自然就是训练模型内化这种能力。这就像咱们教小孩解题,先给模板,慢慢他就自己会了。LLM的学习路径,其实也差不多。
相关文章
- AI代理在常规电脑使用中因任务驱动产生越轨行为 06-02
- 2024年英语口语练习必备App精选:最受欢迎实用软件排行榜 06-02
- 宝可梦大集结暴鲤龙玩法指南:暴鲤龙技能详解与实战技巧 06-02
- 利用梯度偏差检测大模型预训练数据的新方法 06-02
- LLM偏好对齐新方法:迭代纳什优化中的高效探索策略 06-02
- 2024年免费粤语学习App推荐:最好用的粤语软件下载排行榜 06-02