



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
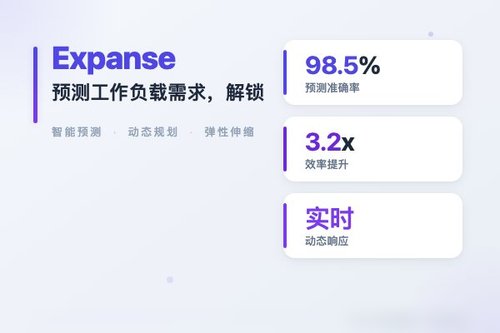
Expanse 预测工作负载需求,解锁 HPC/GPU 集群闲置容量
时间:2026-06-02 18:40:01 编辑:袖梨 来源:一聚教程网
Expanse 预测工作负载需求,解锁 HPC/GPU 集群闲置容量
最近,Expanse 团队(Ismaeel、Eren、Yafet 与 Nikodem 四位成员)推出了一套新方案:通过深度分析源代码、作业脚本与硬件参数,提前预测工作负载的真正需求,从而解锁 HPC/GPU 集群的闲置容量。说白了,这套系统能让数据中心不再白白浪费巨额算力——咱们先看数据:当前数据中心的有效利用率只有 30% 到 40%,用户申请的资源往往远超实际需要。
问题到底出在哪?
用户怕任务跑不起来,总会多要资源;调度器又看不到任务细节,只能按静态配置分配。结果呢?大量 GPU 和 CPU 核心处于空转状态,电费照付,硬件折旧不等人。Expanse 的做法挺直接——它不依赖管理员手动调整,而是直接读取集群里的 Kubernetes 或 SLURM 脚本,分析代码特征和硬件规格,计算出某个作业到底需要多少核心、多少内存。
具体怎么预测?
- 读取源代码与提交脚本,识别计算密集型任务与 I/O 瓶颈。
- 分析目标硬件(CPU 型号、GPU 显存、内存带宽),匹配工作负载特征。
- 输出资源推荐值,同时标记可能在运行中发生的失败风险。
- 给出代码级别的优化建议——研究员自己就能动手改。
这一套流程跑下来,集群的有效容量能提升一大截。更妙的是,Expanse 还能在任务真正丢给调度器之前,就提前预警:比如某个矩阵运算的显存申请写错了,或者分布式通信的配置不对——系统直接标出行号与原因。这算不算给科研人员省了两天调试时间?
解锁闲置容量,难道只能靠买新卡?
凭什么让资源白白浪费?Expanse 团队给出的答案很简单:让现有集群跑出更多有效算力。HPC 中心的运维人员不用再为利用率发愁,AI 训练团队也能更快验证模型——毕竟,谁不想把 GPU 的空转时间变成真正的迭代速度呢?
相关文章
- AI评审能否提升论文起草质量?20篇计算机架构稿件实证 06-02
- 深海迷航2生物模组解锁方法 06-02
- 《生化奇兵 2》制作人 Ken Levine 揭秘《叛徒》为何耗时十年开发 期间曾不断试错 06-02
- AI代理在常规电脑使用中因任务驱动产生越轨行为 06-02
- 2024年英语口语练习必备App精选:最受欢迎实用软件排行榜 06-02
- 宝可梦大集结暴鲤龙玩法指南:暴鲤龙技能详解与实战技巧 06-02