



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
AI智能体之记忆系统:Memory
时间:2026-05-29 12:30:02 编辑:袖梨 来源:一聚教程网
记忆系统作为AI Agent的核心组件,通过分层存储与智能检索机制,有效突破了大模型在上下文记忆和持续学习方面的技术瓶颈。
记忆系统
当前AI Agent面临的主要挑战源于大语言模型固有的无状态特性和上下文窗口限制。
- 无状态性问题:每次API调用都会重置模型状态,导致对话连续性需要依赖历史记录回传,而非真正的记忆能力。
- 上下文窗口局限:即便是百万级Token的超长窗口,也难以承载长期持续的对话历史,同时会带来噪音干扰和成本上升。
- 信息组织短板:真正的记忆系统需要具备结构化存储、联想检索和智能遗忘等类人脑功能。
完整的记忆系统实质上是一个信息全生命周期管理体系,实现了以下关键功能:
- 跨会话保存用户偏好和历史交互记录
- 持续积累领域知识和执行经验
- 支持长期任务跟踪和进度管理
- 基于历史经验优化决策质量
分层架构
记忆系统的核心价值在于平衡大模型有限上下文与海量历史数据之间的矛盾。
借鉴计算机存储架构设计思路:
[ 计算机存储架构 ] [ Agent 记忆架构 ]+-------------------------+ +-------------------------+
| CPU 寄存器 | ==> | 会话记忆 (Session) | -> 原始多轮对话,直接参与当前推理
+-------------------------+ +-------------------------+
| L1 / L2 缓存 (RAM) | ==> | 短期记忆 (Summary) | -> LLM压缩后的摘要,常驻Prompt
+-------------------------+ +-------------------------+
| 外部硬盘 (SSD/DB) | ==> | 长期记忆 (Vector DB) | -> 亿级海量历史,需要时才去模糊检索
+-------------------------+ +-------------------------+
1. 会话记忆 (Session Memory)
- 实现方式:基于内存或Redis构建的严格有序消息队列。
- 核心功能:确保对话连贯性,解决代词指代等上下文依赖问题。
- 生命周期:仅保留最近3-5轮对话,会话结束时自动清除。
- 技术要求:必须保持原始对话内容,禁止LLM修改或摘要处理。
2. 短期记忆 (Short-term Memory)
- 存储形式:由LLM生成的摘要文本或结构化标签。
- 主要作用:承接超出会话窗口的重要信息,作为"前情提要"持续提供上下文。
- 更新机制:随对话进程动态调整,会话结束时可选择性地归档存储。
3. 长期记忆 (Long-term Memory)
- 技术实现:结合向量数据库和关系型数据库的混合存储方案。
- 核心价值:实现跨会话信息持久化,保存用户长期偏好和历史任务记录。
- 数据管理:永久存储,仅支持用户主动删除以符合隐私法规要求。
权衡与取舍
实际部署时需特别注意以下关键问题:
-
会话窗口优化:过小的窗口会导致细节丢失,随着上下文成本降低,建议将窗口扩展至8-10轮对话。
-
数据质量控制:
- 建立看门狗机制,仅允许通过价值评估的内容进入长期记忆库
-
一致性保障:
- 采用分布式锁或基于时间戳的单线程队列处理,避免异步更新导致记忆错乱
核心流程
记忆系统的运作包含完整的写入和读取管道:
- 写入流程:将原始对话转化为可检索记忆,包括信息提取、摘要生成、向量化索引和结构化存储
- 读取机制:按需触发检索,避免全量记忆加载导致的Prompt膨胀
有效的记忆管理必须包含以下维护机制:
-
信息压缩:
- 定期对旧对话进行递归摘要
- 合并相关原子记忆为高级别概括
-
知识提炼:通过周期性复盘,提取用户画像和业务洞察
-
智能遗忘:
- 基于时间衰减的非活跃记忆降权
- LLM评分驱动的低价值记忆清理
- 冲突信息的一致性维护与更新
三层记忆系统的协同工作流程如图所示:
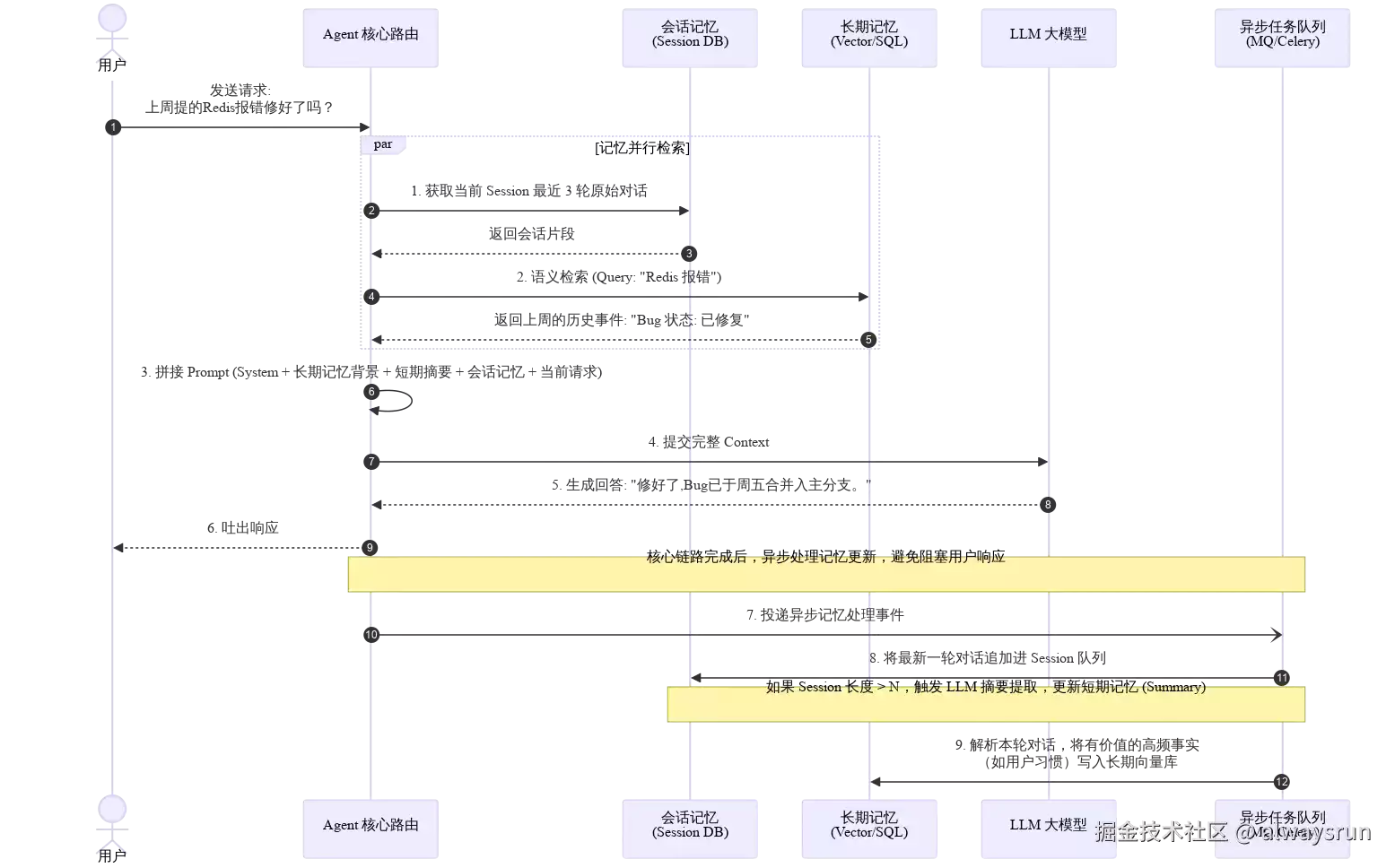
样例代码
采用外观模式实现的三层记忆系统伪代码示例:
import logging
import time
from typing import List, Dict, Any, Optional
from pydantic import BaseModel, Field# 初始化生产级日志
logging.basicConfig(level=logging.INFO, format="%(asctime)s [%(levelname)s] %(name)s: %(message)s")
logger = logging.getLogger("IndustrialMemorySystem")class ChatMessage(BaseModel):
role: str = Field(..., pattern="^(user|assistant|system)$")
content: str = Field(..., min_length=1)
timestamp: float = Field(default_factory=time.time)
class SessionMemory:
"""1. 会话记忆:严格保序的 FIFO 队列,常驻 Redis 内存"""
def __init__(self, max_len: int = 4):
self.max_len = max_len
self.queue: List[ChatMessage] = [] def append(self, message: ChatMessage):
self.queue.append(message)
# 严格控制大小,超出部分将被移出,交给短期记忆去压缩
if len(self.queue) > self.max_len:
evicted = self.queue.pop(0)
logger.debug(f"[Session Memory] Evicted oldest raw message: {evicted.content[:15]}...") def get_raw_history(self) -> List[ChatMessage]:
return self.queue.copy()
class ShortTermSummaryMemory:
"""2. 短期记忆:存储由 LLM 异步压缩后的滚动摘要(前情提要)"""
def __init__(self):
self.summary: str = "" def update_summary(self, expired_message: ChatMessage, current_summary: str) -> None:
"""
生产实践中,此处会异步调用一个低成本的小模型(如 GPT-4o-mini / DeepSeek-V3)
将老的消息融合进现有的摘要中。
"""
logger.info("[Short-Term Memory] Triggering async LLM summary consolidation...")
# 模拟 LLM 压缩
mock_llm_output = f"{current_summary} [已提炼: 用户曾提及过 {expired_message.content[:20]}]"
self.summary = mock_llm_output
class LongTermVectorMemory:
"""3. 长期记忆:连接底层的向量数据库,跨越会话持久化"""
def __init__(self, vector_db_endpoint: str):
self.endpoint = vector_db_endpoint
self._mock_db: List[Dict[str, Any]] = [] # 模拟生产中的 Qdrant / Milvus / PgVector def semantic_search(self, query: str, user_id: str, top_k: int = 1) -> List[str]:
"""具备防御性设计的向量检索"""
try:
if not query.strip():
return []
logger.info(f"[Long-Term Memory] Executing Vector Search for User {user_id}...") # 模拟向量相似度匹配
matched = [
item["content"] for item in self._mock_db
if item["user_id"] == user_id and any(w in item["content"] for w in query)
]
return matched[:top_k]
except Exception as e:
# 防御性设计:向量数据库属于外部依赖,若挂掉绝不能卡死 Agent 核心响应链路
logger.error(f"[Long-Term Memory] Vector DB query failed: {str(e)}", exc_info=True)
return [] def persist_async(self, user_id: str, content: str):
"""模拟将高价值数据异步写入消息队列,最终落盘向量库"""
try:
self._mock_db.append({"user_id": user_id, "content": content, "ts": time.time()})
logger.info(f"[Long-Term Memory] Async persisted high-value info to Vector DB.")
except Exception as e:
logger.error(f"[Long-Term Memory] Failed to persist data: {str(e)}")
class ProductionMemoryManager:
"""统一记忆管理门面 (Facade)"""
def __init__(self, session_id: str, user_id: str, db_url: str):
self.session_id = session_id
self.user_id = user_id # 初始化三层记忆
self.session_mem = SessionMemory(max_len=4)
self.short_term_mem = ShortTermSummaryMemory()
self.long_term_mem = LongTermVectorMemory(vector_db_endpoint=db_url) def get_context_for_llm(self, user_input: str) -> Dict[str, Any]:
"""【同步阶段】为 LLM 组装当前请求所需的全部上下文"""
if not user_input.strip():
raise ValueError("User input cannot be empty.") # 1. 并行/同步检索长期记忆
ltm_context = self.long_term_mem.semantic_search(query=user_input, user_id=self.user_id) # 2. 获取短期记忆摘要与会话记忆
return {
"long_term_context": ltm_context,
"short_term_summary": self.short_term_mem.summary,
"session_history": self.session_mem.get_raw_history()
} def update_pipeline_async(self, user_input: str, agent_response: str):
"""【异步阶段】对话完成后,异步更新三层记忆,解耦主线程"""
logger.info("[Pipeline] Starting asynchronous memory updates...") user_msg = ChatMessage(role="user", content=user_input)
agent_msg = ChatMessage(role="assistant", content=agent_response) # 1. 写入会话记忆。如果触发挤出,顺便更新短期摘要
# 生产环境中,此处的溢出判断可以做成 Hook 挂载到消息队列
if len(self.session_mem.queue) >= self.session_mem.max_len:
oldest = self.session_mem.queue[0]
self.short_term_mem.update_summary(oldest, self.short_term_mem.summary) self.session_mem.append(user_msg)
self.session_mem.append(agent_msg) # 2. 评估是否需要提取长期记忆(关键词触发或 LLM 意图判断)
if "修好了" in agent_response or "Bug" in user_input:
self.long_term_mem.persist_async(
user_id=self.user_id,
content=f"历史记录: 用户反馈过关于 Redis 的 Bug。最终状态: {agent_response}"
)
# ==========================================
# 生产级验证流
# ==========================================
if __name__ == "__main__":
manager = ProductionMemoryManager("sess_001", "usr_100", "milvus://localhost:19530") # 预埋一个几个周前的长期记忆
manager.long_term_mem._mock_db.append({"user_id": "usr_100", "content": "上周历史记录: Redis 发生 1024 内存溢出报错", "ts": 0.0}) print("n--- 第一轮对话:同步检索阶段 ---")
context = manager.get_context_for_llm("我上周提的那个 Redis 报错修好了吗?")
print(f"【LLM 看到的长期背景】: {context['long_term_context']}")
print(f"【LLM 看到的短期摘要】: {context['short_term_summary']}")
print(f"【LLM 看到的当前会话】: {context['session_history']}") # 模拟 LLM 给出了解答,触发异步更新
manager.update_pipeline_async(
user_input="我上周提的那个 Redis 报错修好了吗?",
agent_response="修好了,我们在代码里加上了边界校验,已经合并入主分支。"
)
记忆系统通过分层存储和智能管理机制,为AI Agent提供了类人的记忆能力,使其在复杂对话和长期任务中展现出更强大的连续性和适应性。