



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
LLM推荐基准数据泄漏陷阱:评估结果虚高不可信
时间:2026-05-29 19:45:01 编辑:袖梨 来源:一聚教程网
LLM推荐基准数据泄漏陷阱:评估结果虚高不可信
一份来自arXiv的新研究(编号2602.13626v3)揭露了LLM推荐系统评估中的一个严重漏洞。该研究指出,大语言模型在预训练或微调阶段可能已“见过”基准数据集,导致评估成绩虚高,这难道不是一种挺可怕的陷阱吗?研究人员将此现象定义为“基准数据泄漏”,认为它让模型看起来比实际更聪明。
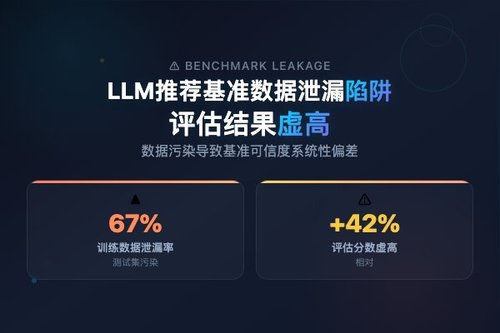
其实,基准数据泄漏的问题一直藏在角落。当LLM被当作推荐引擎时,人们往往直接拿现有数据集跑分,却忽略了模型可能在训练时已记忆了这些数据。这就好比考试前偷偷拿到了标准答案,分数再高又能说明什么呢?研究团队通过模拟不同的数据泄漏场景,证实了这种作弊般的评估会让性能数字“注水”。
那么,泄漏具体是怎么发生的呢?论文解释,当LLM在通用文本海量训练时,如果推荐系统的基准数据恰好混入其中,模型就会无意识记住。之后在同一基准上测试,结果自然漂亮。这真是一个“自我实现的预言”——模型不是学会了推荐,而是学会了回忆。
没错,这个陷阱的影响确实深远。开发者看到高精度指标,可能会误以为模型已成熟,进而匆忙部署到实际产品中。但真实用户可不会乖乖按数据集模式行为,推荐效果难免大打折扣。咱们想想,光是信任这些虚高数据,得多走多少弯路啊。
最后,研究提醒社区需要更严格的评估方案。比如,彻底隔离训练与测试数据,或者采用动态更新的基准集。靠现成的“标准答案”来测试LLM推荐能力,真的靠谱吗?或许,咱们该重新审视这些漂亮数字背后的可信度了。