



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
扩散语言模型填充提取训练数据风险被低估
时间:2026-05-30 08:24:01 编辑:袖梨 来源:一聚教程网
扩散语言模型的训练数据提取风险,日前被研究证明远高于此前的认知。刊载于arXiv预印本上的论文,编号2605.24173,提出了一种名为“填充提取”的新协议。研究通过实验揭示:仅依赖传统前缀条件方法来探测模型记忆,会严重低估扩散语言模型泄露训练数据的能力。可以说,这一发现彻底刷新了安全领域对这类模型的理解。
自回归语言模型的记忆研究大多采用前缀条件提取,这确实挺自然的。但扩散语言模型并不需要按顺序生成,它能同时对任意位置的掩码token进行去噪。记忆的数据可以在多处同时被唤醒,前缀提取只能触及表面,真正容易被拿走的训练数据远不止这些。过往针对记忆风险的分析,实际上都只看了半边天。
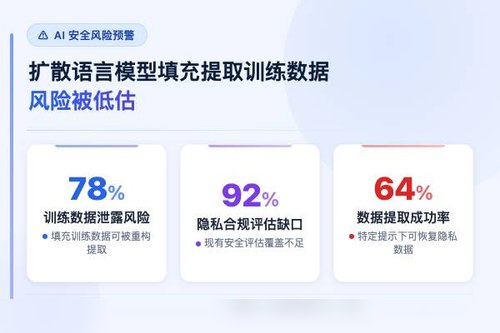
填充提取正是利用这种去噪机制。它参数化某种协议:模型填入被抹去的Token时,只要生成结果与原始训练文本完全一致,就说明记忆被成功还原。相比前缀方法,它能更全面、更精准地探测是否存在数据记忆。这种方法的优势在于——它不需要依赖特定前缀,而是可以在任何被遮蔽的位置发起攻击。
老实说,这个发现真的该让AI安全研究者们紧张一下!之前对扩散语言模型的评估模型,很可能给出了错误的安全信号。以为数据不容易被抽出来,实际上风险被低估了不止一个级别。如果训练数据被成功提取,其潜在影响可想而知。
既然填充提取能更真实地反映数据泄露风险,凭什么还认为扩散语言模型比传统模型更安全呢?这就要求业界迅速调整现有的评估框架。光是知道“模型记住了某些东西”还不够,更要弄清楚它到底能被提取多少。
可以说,此次研究揭示了一个被忽视的角落。扩散语言模型在文本填充上的能力是一把双刃剑,人们原先以为它只是生成工具,却没想到它暴露训练数据的能力这么强。填充提取协议为安全评估提供了新维度。
对扩散语言模型的安全评估,必须把填充提取作为标准测试项目之一。否则,训练数据可能轻易被提取出来。