



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
CLiViS用语言-视觉协同增强具身视觉推理认知地图
时间:2026-05-30 09:12:02 编辑:袖梨 来源:一聚教程网
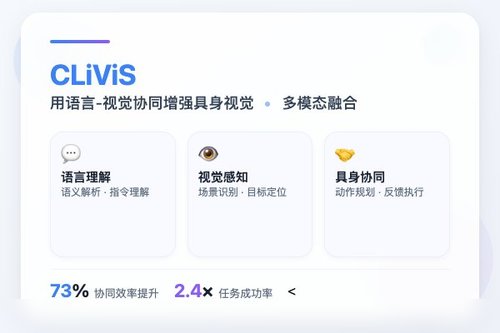
CLiViS(一项基于语言-视觉协同的研究)近日在arXiv平台更新,试图解决具身视觉推理中长期存在的认知地图构建难题。这项编号2506.17629v2的研究核心在于:如何让机器像人一样,在观看第一人称长视频后,理解复杂指令并完成空间推理。
核心挑战在于视频里的“时间”与“空间”。普通模型要么靠静态字幕调用大模型,结果丢了太多视觉细节——物体形状、移动轨迹、环境变化全被忽略。要么搞端到端训练,但复杂指令一多就乱套。CLiViS的做法呢?它把语言描述和视觉信息强行“绑定”在一起,再生成一个动态认知地图。听起来挺玄乎,其实原理很简单:让文字说“从厨房拿杯子”,画面同时标记杯子的位置和移动路径,两者互相纠正,这才算真正理解了指令。
这就带来一个问题:纯文本模型凭什么能理解动态场景?举个例子,你说“把桌上的苹果递给右边的人”,字幕模型只会记住“苹果”和“右边”,可如果那人中途换了位置,或者苹果被移走了呢?CLiViS偏偏做到了!它通过语言-视觉协同,把环境变化实时反映到认知地图里。这不就是纯文本模型的老毛病吗?——静态描述永远赶不上动态现实。
实测效果确实够硬。研究团队在复杂EVR基准上跑了一轮,CLiViS的推理准确率明显优于传统方法,尤其在处理“先做A,再做B,但A的过程中C发生了”这种嵌套指令时,错误率降了不少。说白了,模型终于学会“看到”房间里的变化,而不是“猜”出指令含义。
其实这项研究的价值不止于论文。想想咱们日常用的导航、无人机送货、甚至家庭机器人——哪个不需要看懂第一人称视角的视频?以前的方案要么慢得像蜗牛,要么笨到分不清“沙发上的猫”和“猫坐过的沙发”。CLiViS把语言和视觉揉在一起后,机器至少能像人一样嘟囔一句:“哦,那个绿杯子在厨房灶台旁边,刚才主人走过来时它就被碰倒了。”
当然,距离大规模落地还有距离。研究团队自己也承认,更长视频序列、更多噪声环境下的稳定性有待验证。但方向没错:让机器“看见”并“记住”空间变化。如果后续能把计算效率再提一个台阶,家庭服务机器人听懂“帮我把客厅茶几上的遥控器拿过来”就不再是科幻场景。
今年具身视觉推理赛道的技术迭代确实快,CLiViS算是给认知地图研究砸开了一个新口子。接下来就看同行们怎么接招了——毕竟,用语言和视觉协同“画”出一张动态认知地图,比单靠文字或单靠画面靠谱得多。事实就是:真正的智能,得先学会“睁眼看世界”。