



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
字节跳动发布任意到任意多模态模型Lance
时间:2026-05-30 14:42:01 编辑:袖梨 来源:一聚教程网
字节跳动发布任意到任意多模态模型Lance,这是一个能同时处理图像生成、视频生成、图像编辑和视频理解的全能型AI模型。
模型核心能力解读
这款名为Lance的模型确实挺特殊,它支持“任意到任意”的输入输出模式。这意味着用户无论是丢给它一张图片、一段视频,还是文字指令,它都能给出对应的图像或视频结果。这种能力在目前的AI圈子里可不多见,可以说是把之前分散的图像生成、视频理解等任务整合到了一起。
模型技术细节与社区反馈

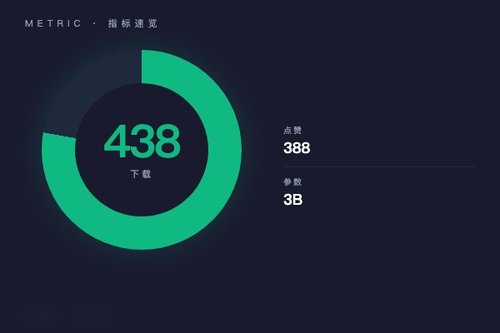
根据Hugging Face上的公开信息,Lance模型基于Qwen/Qwen2.5-VL-3B-Instruct作为底座模型,使用safetensors格式存储。目前它在平台上收获了438次下载和388个喜欢,这个数据在开源模型里算是相当不错的反响。这就说明开发者社区对它的兴趣很浓厚,凭什么?因为它真正做到了多模态的闭环。
为什么说它是“任意到任意”?
咱们仔细看它的标签:“图像生成、视频生成、图像编辑、视频理解”这些功能全部集于一身。一般的多模态模型往往只做单向转换,比如从文字到图片,或者从图片到文字。但Lance不同,它能从任意一种模态输入,输出任意一种模态结果。举个例子,你给它一段视频,它能生成新的图像;你给它一张照片,它能帮你编辑成新风格。
开源意味着什么?
模型权重已经公开在Hugging Face上,这意味着研究者和开发者可以拿它来做二次开发或商业应用。这对于加速AI在内容创作、视频分析等领域的落地很有帮助。毕竟,一个模型能同时搞定生成和理解,想想就挺省事的——何必用多个模型来回切换呢?
这会改变什么?
字节跳动这次推出的Lance,其实展示了一种趋势:AI模型正在走向功能融合。过去咱们需要分别用图像生成模型、视频编辑工具、视频理解API,现在一个模型就能包揽。这不只是技术上的进步,更可能让AI应用的开发门槛降低。