



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
语言模型规模相变:推理与真实性从对抗到协同
时间:2026-05-30 17:03:01 编辑:袖梨 来源:一聚教程网
一项来自arXiv的最新研究揭示了大语言模型能力演化中隐藏的相变规律。该研究对16个模型家族共63个基础模型进行测量,发现推理能力与真实性之间并非始终协同——当模型参数量低于约35亿(2.9B至13.4B)的临界值时,两者呈现对抗关系;规模跨过临界点后,它们才转为协同配合。这一发现表明,单纯依赖损失曲线无法捕捉能力间的相互作用。
相变点:约35亿参数的分水岭
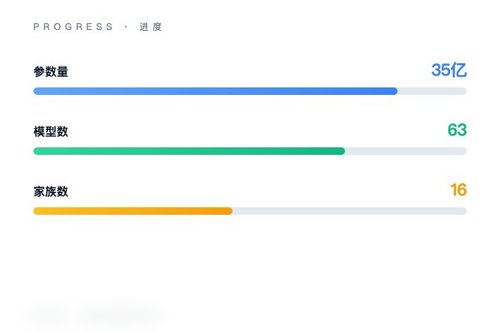
研究团队通过分析模型在不同规模下的表现,确认了“规模相变”的存在。临界规模 N_c 约为35亿参数(95%置信区间2.9B–13.4B)。低于这个数值时,模型的推理越强,其输出反而越不真实;一旦突破临界值,推理能力与真实性开始互相促进。这算是一种挺反直觉的现象——谁说大模型只是“越大越好”呢?
不只是参数规模在起作用
论文指出,模型大小并非唯一决定相变位置的因素。架构设计、数据筛选策略以及训练方式都会各自独立地移动 N_c 的值。这就意味着,即便参数规模相同,不同的训练方案可能导致模型处于完全不同的“相位”。没错,模型的能力组合其实更像一种可调的材料属性。
推理与真实性:从对抗到协同的拐点
为什么会出现这种转变?研究推测,小模型由于容量有限,推理模块与真实性模块可能争夺相同的参数资源,导致相互抑制;而当规模足够大时,模型可以同时分配专用子空间处理两项任务。这种从“资源竞争”到“分工合作”的转变,正是相变的本质。咱们能不能通过调整训练数据来提前激活协同状态?当然可以。
实用价值:为AI安全与部署提供新视角
这项研究对AI行业有直接启发。此前业界常通过扩大模型规模来提升能力,却忽略了推理与真实性之间的隐式矛盾。现在我们知道,如果模型规模处于临界值以下,盲目提升推理能力反而可能让模型更爱“编造”。这或许能解释为什么某些小模型在数学题上表现优异,却频频输出虚假信息——何来这种“聪明反被聪明误”的现象?答案就在相变规律中。
未来方向:精细调控能力协同
研究团队呼吁,未来的缩放律研究不应只关注损失值,还应追踪能力间的耦合关系。通过定向调节数据分布或架构组件,或许能将模型的 N_c 向左移动,让中等规模模型也能实现推理与真实性的协同。这确实为AI对齐提供了新的工程抓手。