



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
前沿模型排行榜区分度下降,新度量聚焦能力耦合与权衡
时间:2026-05-30 17:06:01 编辑:袖梨 来源:一聚教程网
前沿模型排行榜的区分度正在消失,用新度量聚焦能力的耦合与权衡成为关键。日前,一篇ArXiv论文(编号2605.18840)指出,传统排行榜将模型能力视为独立轴心进行排名,但忽视了能力是否相互促进或此消彼长。研究团队对2024年至2026年间来自10个实验室的34个前沿模型进行分解分析,发现能力之间存在高度耦合(相关系数r = +0.72,p < 10⁻⁶),意味着模型能力在整体提升中更倾向于协同进化,而非单点突破。
旧榜单为什么失效了?
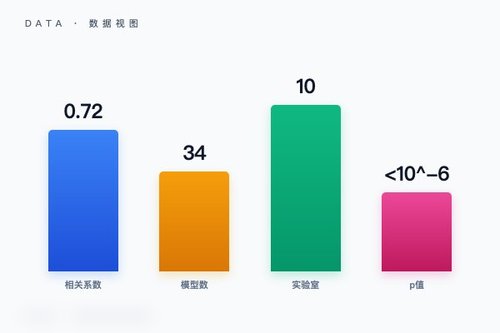
传统的SWE-bench与GPQA Diamond评分已在顶尖模型中拉不开显著差距,区分度下降。论文提出一种“h场”分解方法,将每个模型的表现拆解为整体趋势的耦合项,以及反映其能力侧重的“残差”。这种新度量关注的不是“谁排第一”,而是“这个模型在能力权衡上做了什么选择”。其实,这种思路在逻辑上挺颠覆:它不把排行榜当作试卷的分数,而是当作能力地图的等高线。
“h场”度量:从排序到诊断
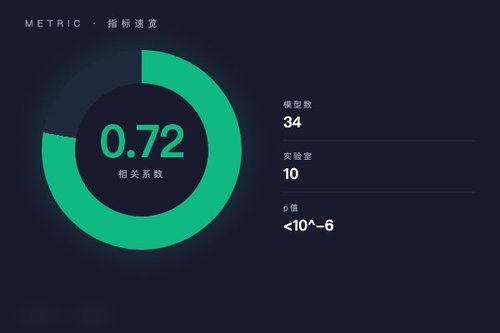
每个模型的“h场”残差能诊断出它在能力耦合中的具体角色——该模型是强化了某个维度的能力,还是在某些维度上做出了妥协?凭什么说排名没价值了呢?因为当所有模型在整体指标上都逼近得分上限时,排名信息几乎为零。反而在耦合趋势中,能力之间的互动关系才是更富信息量的信号。没错,这才是决定下一代模型应该优先攻克哪个技术瓶颈的关键。
行业启示:别只看排名了
对于AI行业而言,这份研究的实际意义在于,它提供了一个更务实的评估框架:哪些测量或压力测试对下一步最有信息价值?比如,如果一个模型在代码修复能力上表现突出,却在推理基准上发生回退,“h场”就能清晰标示出这种权衡。开发团队因此可以更快地定位出性能耦合中需要调整的张力点,而不是盲目追逐榜单上的虚高分数。
这算是一个转折点吗?
从打分到诊断,从独立排名到耦合分析,前沿模型的评价标准确实在经历一次逻辑迁移。当排行榜不再能有效区分模型优劣时,新度量聚焦的“能力耦合与权衡”就成了行业必须面对的议题。未来,判断一个模型好不好,可能不再是看它刷爆了多少项基准,而是看它在能力关系图中呈现了怎样一个合理的互补结构。
相关文章
- 工银e生活如何办理etc 05-30
- Kimi K25/DSR1模型新增TOKENSPEED_MLA注意力后端加速 05-30
- 天羽传奇新手如何玩 05-30
- Open-Sora 1.0.0 开源发布,高质量视频生成工具开放 05-30
- 空洞骑士丝之歌:骸底镇通关方法-详细攻略指南 05-30
- B站官方网站首页地址是什么 05-30