



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
语言模型规模达3.5B参数时推理与真实性从对抗转向协同
时间:2026-05-30 17:45:01 编辑:袖梨 来源:一聚教程网
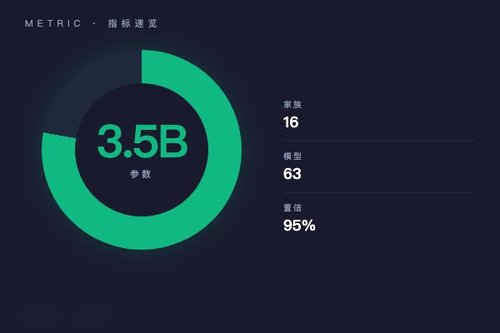
日前一篇来自arXiv的论文揭示了一个关键发现:当语言模型规模达到约3.5B参数时,其推理能力与真实性之间会从“对抗”转向“协同”。这项研究基于对16个模型家族的63个基础模型的系统测量,首次在损失曲线之外发现了这一隐藏的相变点。
临界点并非绝对,3.5B参数只是统计中心
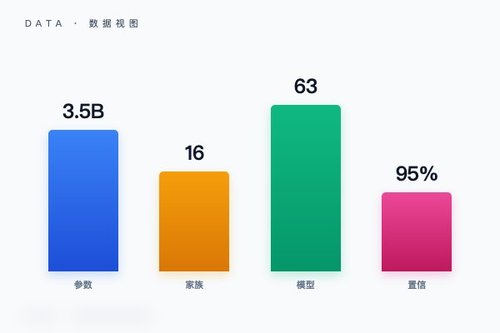
研究采用Bootstrap方法计算,在95%置信区间下,临界规模N_c介于2.9B到13.4B参数之间。这虽然表明3.5B是一个基准数值,但并不意味着所有模型都严格按照这一数字发生转换。不同的模型家族在相同规模下可能处于不同的“相位”,这背后真正的原因究竟是什么?
架构、数据与训练方法各自独立地影响相变
论文明确指出,模型尺寸并不是决定相移的唯一变量。架构设计、数据筛选策略以及训练配方都会独立地改变N_c的取值。这就好比同一道菜,食材分量固然重要,但火候与调料配比同样能改变最终风味。咱们可以理解为,一个经过精心数据清洗的3B参数模型,其真实性与推理的协同效果,可能比一个缺乏优化的7B模型更好。
对抗与协同的实质是能力耦合
在低于临界规模的阶段,模型的推理能力与真实性呈现反相关:模型越擅长推理,输出的信息反而越可能偏离事实。这听起来挺让人沮丧的,不是吗?但当规模突破临界值后,二者开始正向协作,推理能力的提升会显著增强真实性。这意味着“聪明”和“诚实”终于不再是一对矛盾。
Loss曲线之外的隐藏信号
传统上,业界依靠损失函数曲线来预测模型性能,但该研究表明损失曲线无法反映这一“关联态”的转变。确实,只看Loss会以为模型在均匀进步,实际上内部的能力耦合正在经历质变。这个隐藏信号解释了为什么某些模型在实际应用中突然变得“靠谱”。
筛选机制的独立调节作用值得关注
研究特别提到“curated training”——即经过精心策划的训练数据筛选,可以独立地移动N_c的位置。这意味着通过优化数据质量,即便参数规模没有达到3.5B,我们也能提前诱发协同效应。没错,数据的重要性再次被提到决定性高度,算是一个实用的工程启示。
临界规模为模型评估提供新维度
最后,该结论为行业提供了一套新的评估指标:在评估模型时,不应只看单个能力的分数,更应关注推理与真实性的耦合关系。这个相变点的发现,帮咱们把“模型多大才够好”这个问题,从单纯的参数竞赛拉回到能力协同的本源上来。
相关文章
- 斗罗大陆魂师对决10月19日最新兑换码领取指南 05-30
- 阶跃星辰发布Step-3.5-Flash-Base文本生成模型 05-30
- 蔚蓝档案中不破莲华怎么样 05-30
- 空气投篮是什么意思详细介绍 05-30
- 叮嗒出行app:不交押金可以租车吗 05-30
- BAAI发布Emu3.5-Image,实现图文到图像生成 05-30