



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
NVIDIA发布Nemotron-3多模态推理模型,30B参数仅3B激活
时间:2026-05-30 19:21:01 编辑:袖梨 来源:一聚教程网
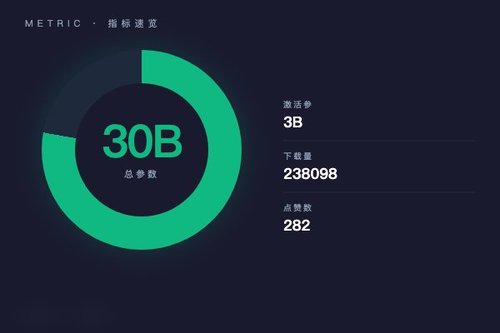
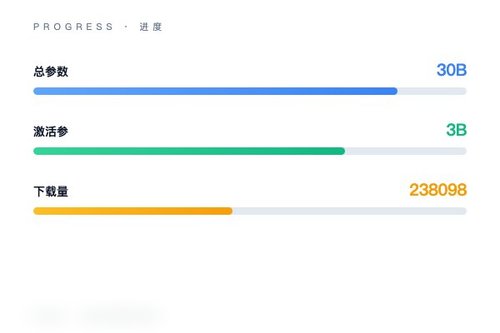
NVIDIA 日前在 Hugging Face 上发布了 Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16 模型,这是一款 30B 总参数仅 3B 激活的多模态推理模型,刚上线就拿到了 238098 次下载和 282 个赞。模型采用稀疏专家架构(MoE),推理时只激活 10% 的参数,效率确实挺高。
30B 参数只激活 3B,凭什么这么强? 答案藏在“any-to-any”这个 pipeline tag 里——模型支持图像、文本、语音等多种模态的输入输出,而不是单纯的文本聊天。它基于 NemotronH_Nano_Omni_Reasoning_V3 架构构建,再用 NVIDIA 自家的 Nemotron-Image-Training-v3 数据集进行训练,这就让它在多模态推理上有了实打实的竞争力。
多模态模型越来越多,Nemotron-3 到底哪里不一样? 其实关键在于“推理”二字。它不是简单的多模态识别模型,而是能理解图像中的逻辑关系并进行多步推理。比如说你给它一张图表,它不光能读出数字,还能分析趋势、做预测。这一点对于企业级应用来说真的很有价值。
再来看技术细节:模型使用 safetensors 格式存储权重,基于 PyTorch 框架开发,属于 transformers 生态。它支持 feature-extraction 功能,意味着开发者可以将其嵌入到更大的 AI 系统中作为特征提取模块。这种灵活性让咱们在做二次开发时省了不少力气。
开源、多模态、低激活参数——这套组合拳打得很准! 要知道,大模型部署的最大痛点是显存和算力。Nemotron-3 用 30B 总参 + 3B 激活的策略,相当于把一台“重型卡车”改装成了“轻量跑车”:功能不减,成本却大幅降低。对于中小企业来说,这确实是个好消息。
目前模型在 Hugging Face 上以 BF16 格式提供,这对于服务器端推理非常友好。NVIDIA 这次算是把推理效率做到了一个新高度——30B 参数级别里,能同时兼顾多模态和低激活的模型本来就没几个,Nemotron-3 可以说是直接抢占了先机。
相关文章
- Google AI Studio 让任何人都能在几分钟内构建原生安卓应用 05-30
- 燕云十六声驼您福嘞成就攻略-成就驼您福嘞如何完成 05-30
- 食物语t0阵容怎么搭配 05-30
- 大疆pocket3如何将视频导出到手机 05-30
- 燕云十六声路边的外卖不要采成就攻略-成就路边的外卖不要采如何完成 05-30
- Google Universal Cart上线:跨设备跨零售商追踪用户完整购物路径 05-30