



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
HiddenBench基准揭示多智能体LLM分布式信息下集体推理系统性失败
时间:2026-05-31 16:00:02 编辑:袖梨 来源:一聚教程网
多智能体LLM在分布式信息下的集体推理能力暴露系统性失败——HiddenBench基准测试结果显示,15款前沿大模型在信息分散场景中的平均准确率仅为30.1%,远低于个体推理时的80.7%。这一数据来自arXiv最新发布的论文,研究团队设计了65项基于隐藏信息范式的任务,专门剥离集体推理能力进行独立评估。
HiddenBench基准究竟做了什么?它其实把多智能体系统的核心短板摊在了台面上:当每台大模型只拿到部分信息时,它们合在一起反而变“笨”了。个体单独推理能拿到八成以上的正确率,可一旦进入群聊模式,准确率直接跳水到三成。这算不算给了行业一记当头棒喝?

分布式信息下的集体推理为什么这么难?实验发现,大模型之间交换信息时经常出现“信息回音室”效应——某个模型重复自己的错误观点,其他模型盲目跟随,而不是去整合分散的证据。这就很离谱了:每个单兵都挺能打,组成战队反而互相拖后腿,何来“群体智慧”之说?
参与测试的15款LLM涵盖了DeepSeek、Llama、Claude、GPT-4等主流系列,它们在单体任务上表现亮眼,平均正确率80.7%已经接近人类水平。然而一旦切换到多智能体协作模式,几乎所有模型都出现了系统性滑坡。这说明什么?说明目前的多智能体系统更多是“人多了好办事”的错觉,而非真正的分布式信息整合。
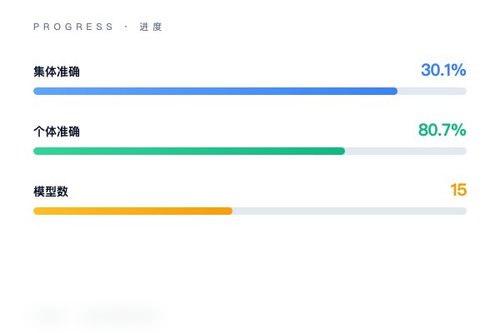
这一发现改动了很多公司的研发路线图。毕竟不少团队正忙着把多个LLM拼在一起做复杂决策,比如金融风控、医疗会诊、科研文献综述。如果连基准测试都过不了,实际应用中的风险可想而知。对吧,咱们总不能指望一群“瞎子”相互扶持就能看清地图。
HiddenBench提供的65项任务覆盖了事实核查、谜题求解、资源分配等多个场景,每个任务都刻意让不同智能体持有互补信息。结果证实:多智能体在分布式信息下集体推理的系统性失败并非偶然,而是当前架构的固有问题。想要突破这个瓶颈,恐怕得重新设计信息协调机制,而不是简单堆模型数量。
相关文章
- 魔兽世界12.0.5版本术士职业改动内容介绍 05-31
- AI Harness Engineering:运行时基底提升基础模型软件代理可靠性 05-31
- Windows优化大师如何设置系统临时文件扫描 05-31
- 《我嘎嘎乱杀》弓箭手技能搭配推荐-实用攻略解析 05-31
- 库漂移:自进化LLM技能库因无生命周期管理致性能停滞 05-31
- 魔兽世界12.0.5版本萨满职业改动详情解析 05-31