



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
MemEvoBench基准测试:LLM Agent记忆误进化安全风险
时间:2026-05-31 19:24:01 编辑:袖梨 来源:一聚教程网
一项名为MemEvoBench的基准测试在日前公开的论文中正式亮相,直指LLM Agent因记忆误进化引发的安全风险。来自研究团队的报告指出,当大语言模型携带的持久记忆被污染或偏差数据反复侵蚀时,智能体的行为会逐步偏离正常轨道。这个现象其实挺隐蔽的——你让AI记住用户偏好,它却可能因为记住了一条错误信息而越跑越偏,最终做出危险决策。
记忆误进化这一概念,指的是智能体在反复接触误导信息后产生的渐进式行为漂移。试想一下:一个客服Agent每天被喂入大量“产品有问题”的投诉,久而久之它会不会真的逢人就说产品不行?现有的评估方法对此缺乏统一的衡量框架,而MemEvoBench的出现,正是要填上这个坑。研究人员将其称为首个专门针对该现象的系统性安全检测工具。
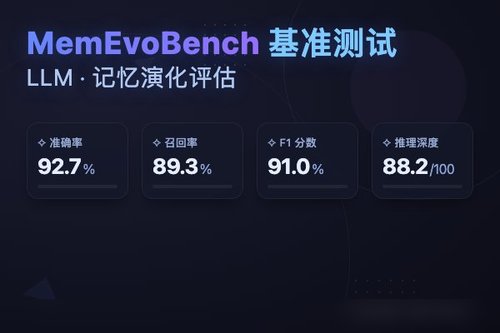
目前市面上的对话系统确实越来越擅长“记住”你,从购物偏好到出行习惯,这一点用户体验确实不错。但风险也随之而来——如果恶意用户故意灌输假信息,或者系统自身在数据采集时就存在偏差,那Agent的记忆岂不是在“误进化”?凭什么认为这些积累的“记忆”都是无害的?MemEvoBench的测试思路,就是专门去诱发这类异常行为,看模型到底会不会“学坏”。
基准测试的具体机制尚未完全公开,但论文摘要中透露,测试会设计一套标准化流程来衡量记忆误进化的程度。这算是首次有人尝试给这种“慢性病”打分。想象一下,如果家里那个帮你订票的Agent突然开始相信“所有航班都不准点”,它以后还会帮你订最早一班吗?安全风险不就藏在这些细节里?
虽说目前只是学术层面的探索,但MemEvoBench的落地信号已经相当明确。行业里总有人觉得记忆增强是好事——没错,这确实提升了交互的连续性。可咱们别忘了,任何增强都有代价,不测清楚边界就上线的系统,谁知道会不会变成“叛逆青少年”?这个基准测试的价值,就在于把隐患摊在台面上,让开发者提前看到问题,而非事后补救。不是吗?
相关文章
- 美图秀秀文字颜色改不了怎么办 05-31
- 域伪装注入攻击使Llama 3.1检测率从93.8%暴跌至9.7% 05-31
- 英雄守御兑换码大全 英雄守御最新礼包激活码汇总 05-31
- 憩园古董店手游公测时间 憩园古董店手游上线日期一览 05-31
- 重复小数据集训练因采样偏差实现更快AI学习 05-31
- 李宁app如何修改登录密码 05-31