



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
HuggingFace 推出分块交叉熵损失函数,SFT 显存节省达 50%
时间:2026-05-31 19:36:02 编辑:袖梨 来源:一聚教程网
HuggingFace 在其 TRL 库 v1.4.0 版本中正式推出了分块交叉熵损失函数(Chunked cross-entropy loss),这一功能让监督微调(SFT)的显存节省最高可达 50%。对于正在被显存瓶颈困扰的开发者来说,这确实是一个实实在在的利好。
显存节省到底是怎么做到的?
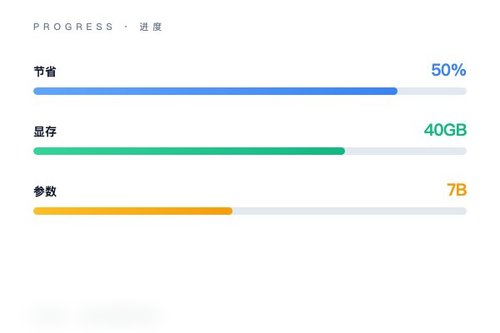
传统交叉熵损失计算需要一次性加载整个序列的 logits,这在大模型微调时往往会把 GPU 显存撑爆。分块交叉熵的思路其实挺直接——把长序列切成小块,逐块计算损失,块与块之间共享中间结果。这样一来,峰值显存占用就被大幅削平了。从官方公布的基准测试看,在相同的批量大小和序列长度下,显存占用几乎腰斩。
这对咱们的 SFT 训练意味着什么?

微调一个 7B 或 13B 参数的大模型,单卡 40GB 显存往往只能塞下很小的 batch size。如今用了这个分块损失函数,同样的硬件条件下,开发者可以把 batch size 提高一倍,或者一次吃下更长的上下文序列。没错,这确实能让实验迭代速度加快不少。更关键的是,HuggingFace 把这个功能直接集成到了 TRL 的 SFTTrainer 里,调用起来非常方便。
为什么说这个优化比想象中更有价值?
SFT 是训练指令跟随模型的关键步骤,很多研究团队需要在有限的预算内反复调整超参。把显存省下来,意味着可以在同一块 GPU 上尝试更大的模型或更长的 prompt,而不用急着去加卡。这对于学术实验室和个人开发者来说,无疑降低了参与大模型微调的门槛。你觉得呢?
值得一提的是,v1.4.0 版本除了引入分块交叉熵,还对训练流程做了其他稳定性改进。不过最亮眼的还是这个显存优化——它直接解决了 SFT 阶段一个很现实的痛点。可以说,HuggingFace 这次是又往开源生态里投了一枚实用的效率炸弹。
相关文章
- 《梦幻西游》金柳露怎么获得-宝宝洗炼详解 05-31
- Agentic Discovery of Cryomicroneedle Formulations 05-31
- 原神6.4全新版本角色抽取攻略 月之五版本抽卡建议 05-31
- nomo相机如何切换摄像头 05-31
- 魔兽世界力不从心任务怎么过 05-31
- CODA用GEMM-Epilogue重写Transformer块缓解内存瓶颈 05-31