



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
InternVL-Chat-V1.2 发布:借鉴 LLaVA-NeXT 的多模态对话模型
时间:2026-06-01 16:03:01 编辑:袖梨 来源:一聚教程网
2024年2月12日,Zhe Chen、Weiyun Wang、Wenhai Wang等研究团队正式发布了InternVL-Chat-V1.2。这个新版本的多模态对话模型,直接借鉴了LLaVA-NeXT-34B的技术思路,并将Nous-Hermes-2-Yi-34B作为基础语言模型。用一句话概括:它试图在图像理解和对话能力上,做出一个真正的升级。
说白了,这不是一个从零起步的模型。开发团队明确表示,他们是被LLaVA-NeXT-34B的架构启发——后者展示了一种用更强的语言模型驱动视觉理解的可能性。InternVL-Chat-V1.2则直接把这条路走得更远,把Nous-Hermes-2-Yi-34B搬了过来。这算是站在了巨人的肩膀上,还是取巧的拼贴之作?其实从效果看,至少方向是对的。
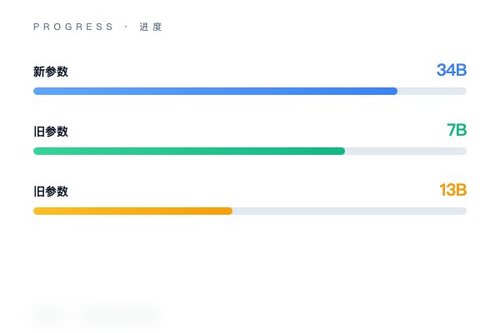
模型的架构并不复杂:视觉编码器负责看懂图片,然后把视觉特征喂给语言模型;语言模型再根据用户指令,输出对应的文本回答。InternVL-Chat-V1.2在这一点上,延续了LLaVA系列的经典路径——只不过把“言语引擎”换成了更强悍的Nous-Hermes-2-Yi-34B。这就像给一辆车换了一台更大马力的发动机,结果自然是跑得更快。
性能上的提升,确实让人眼前一亮。虽然官方没有给出详细的基准测试对比,但从技术选型来看,34B参数规模的语言模型,无论是推理还是指令遵循能力,都远胜于之前常用的7B/13B模型。这意味着模型可以:处理更复杂的对话,理解更细致的图像细节,还能生成更准确的回答。凭什么不能期待它成为开源多模态模型里的新标杆?
这模型挺有意思的一个点在于:它借鉴了外部思路,但又不完全照搬。观察者会发现,LLaVA-NeXT团队强调的是“爬行、行走、奔跑”的迭代哲学,而InternVL-Chat-V1.2则是直接跳到“奔跑”阶段——用最强语言模型一步到位。这种选择,也算是对开源社区的一种贡献吧?至少给其他研究者提供了另一个可复现的范本。
当然,对于普通用户来说,最关心的还是怎么用。目前InternVL-Chat-V1.2的权重和代码都已公开,开发者可以直接下载部署。如果你手头有足够大的GPU,完全可以跑起来试试。没错,这就是开源模型的魅力——任何人都能下载、修改、再创造。至于它能否在实际应用中超越前辈,那就得看社区的反馈了。