



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Stability AI 开源文本生成音频模型 stable-audio-open-small
时间:2026-06-01 20:30:02 编辑:袖梨 来源:一聚教程网
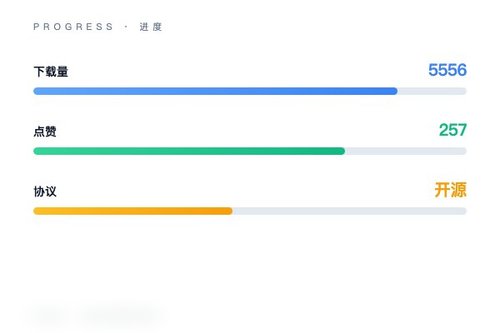
Stability AI 日前在 Hugging Face 上开源了文本生成音频模型 stable-audio-open-small。该模型基于 stable-audio-tools 框架,采用 safetensors 格式,属于 text-to-audio pipeline 类别。目前模型页面显示下载量已达 5556 次,获得 257 个点赞,社区反响确实不错。
作为一款轻量级开源模型,stable-audio-open-small 的定位很有意思。它不像某些大模型那样动辄几十亿参数,而是主打高效和实用。你可以直接输入文本描述,模型就能生成对应的音频片段——这算是对开发者非常友好的选择。模型对应的论文编号为 arXiv:2505.08175,说明 Stability AI 在学术层面也做了同步公开。
为什么社区会如此关注这个模型呢?其实原因挺直观的。文本生成音频领域过去大多被商业模型垄断,开源方案要么效果差,要么门槛高。stable-audio-open-small 的出现,等于给开发者提供了一个可以直接拿来用的基座。它使用 safetensors 格式,安全性更高,兼容性也好,部署起来没那么折腾。
从标签来看,模型许可协议标注为“other”,区域为“us”。这意味着它在使用条款上有一定的定制空间,咱们在应用前最好仔细查看具体协议内容。不过开源本身已经降低了接入门槛——你可以直接在 Hugging Face 上通过 pipeline 调用,无需自己搭建复杂的推理环境。
有意思的是,模型页面还收录了相关脚本代码(用于暗色模式切换等),但这不是重点。重点在于 stable-audio-open-small 确实把“文本生成音频”这件事变得更亲民了。要知道,过去想做个语音合成或音效生成,要么付费调用闭源 API,要么自己训练大模型,成本高得吓人。现在有了这个开源版本,很多小团队和独立开发者都能试一试。
当然,模型还处于早期阶段,下载量 5556 次比起那些动辄百万的明星模型不算大,但 257 个点赞已经说明它得到了不少从业者的认可。文本生成音频这个方向还在快速发展,stable-audio-open-small 的发布算是一个不错的起点——咱们可以期待后续社区基于它衍生出更多应用。
相关文章
- 电脑输入法设置搜狗输入法教程 06-01
- 街霸6如何试玩 06-01
- 腾讯地图标注自己店铺位置方法 06-01
- 7723游戏盒如何修改游戏? 06-01
- 荣耀magicvs2配置参数 06-01
- 蚂蚁庄园今日2月19日答案更新 06-01