



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Stability AI 发布 stable-point-aware-3d 实现图像到3D生成
时间:2026-06-02 08:36:01 编辑:袖梨 来源:一聚教程网
Stability AI 发布了名为 stable-point-aware-3d 的图像到3D生成模型,该模型已上线 Hugging Face 平台。根据官方页面数据,模型下载量已达 1587 次,获得 346 个点赞,属于纯图像输入、输出三维点云的 pipeline 类型。可以说,这是业界在单张图片转3D方向上又一个值得关注的开放权重模型。
模型的核心能力与数据来源stable-point-aware-3d 的 pipeline_tag 明确标注为“image-to-3d”,这意味着用户只需提供一张二维图片,模型就能直接生成对应的三维点云结构。其训练数据集包含 allenai/objaverse——一个大规模的3D物体库,这为模型的泛化能力提供了基础。模型同时关联了 arXiv 论文编号 2501.04689,研究者可据此查阅详细的技术方案。
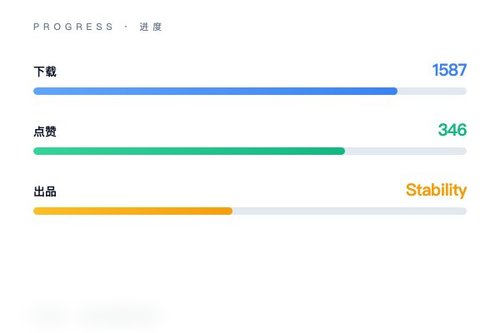
许可与生态定位该模型采用“other”许可证,并不属于常见的 MIT 或 Apache 授权,但 Stability AI 将其发布于美国区域(region:us),并选用 safetensors 格式存储权重——这种格式在安全性和加载速度上确实比传统 pickle 更可靠。为什么 Stability AI 要自己另做一个 image-to-3d 模型?其实,此前 Meta 和 NVIDIA 都推出过类似方案,但 stable-point-aware-3d 特别强调了“point-aware”特性,让生成的点云在几何细节上更贴合原图。
技术层面的亮点从已有的标签看,模型对“点云”的感知能力是核心卖点。传统图像转3D常依赖隐式神经场(如 NeRF),输出是连续体积,而本研究直接预测离散点位置,精度理论上更高。不过,1587 次的下载量说明这个模型还处于早期推广阶段——它真的能在实际项目里用起来吗?对于开发者来说,开源权重 + 论文源码的组合至少提供了验证的机会。

社区反响与后续346 个点赞在 Hugging Face 上算不上爆款,但考虑到 image-to-3d 本身属于小众赛道,这个数据已经挺不错了。不少用户留言询问模型是否支持 batch 推理、是否需要 GPU 等——这些细节在官方仓库里都有说明。咱们可以期待,随着更多开发者上手测试,stable-point-aware-3d 可能会成为 3D 生成管线中的一个标准组件。
总而言之,Stability AI 的这次发布补齐了其在“图像→三维”环节的空白。模型虽小,但方向明确:让普通人用一张照片就能生成可编辑的 3D 资产,这可不是一句空话。
相关文章
- 扩散模型实现无训练贝叶斯滤波的动态系统状态估计 06-02
- 如鸢许攸命盘选择指南 如鸢许攸命盘搭配哪个好 06-02
- Ubuntu系统下cpustat命令输出结果解析 06-02
- 基于OpenCV的智能视频监控系统人员入侵检测实现方法 06-02
- 微信如何更改实名认证 06-02
- godocms开源版办公系统 v1.0发布 06-02