



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
InternVL3.5-241B-A28B-Flash:241B参数多模态模型仅28B激活
时间:2026-06-02 09:00:01 编辑:袖梨 来源:一聚教程网
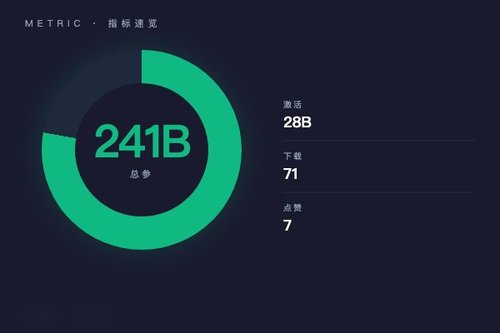
OpenGVLab 日前在 Hugging Face 发布了 InternVL3.5-241B-A28B-Flash 模型,一个总参数高达 241B、但推理时仅激活 28B 参数的多模态模型。该模型下载量已达 71 次,获得 7 个点赞,其 pipeline 标签为 “image-text-to-text”,主打图像与文本的跨模态理解。
241B 参数规模,仅 28B 激活——这效率划算吗? 模型架构采用了混合专家(MoE)设计,虽然整体参数多达 2410 亿,但在具体任务中只会调用其中约 28B 的参数。这意味着模型拥有强大的知识储备,实际运算成本却远低于同等规模的传统模型,可以说在性能与效率之间找到了一个挺巧妙的平衡点。
其实这种激活策略早已在语言模型中验证过。 InternVL3.5-241B-A28B-Flash 把它带到了多模态领域。从标签看,它支持多语言对话、特征提取以及图像-文本互生成,这就覆盖了目前主流的多模态需求。咱们想想看,一个大模型既要看懂图片又要回答相关问题,如果每次调用所有参数,算力开销确实惊人;而 MoE 结构让它只激活必要的 “专家模块”,确实是个务实的方向。
为什么这个模型值得关注? 因为它解决了多模态模型部署的一个核心痛点:参数太大会卡在显存里,参数太小能力又不够。28B 激活量大概能运行在消费级 GPU(比如 RTX 4090)或企业级推理卡上,这使得开发者无需依赖昂贵的算力集群就能进行实验。诚然,241B 的完整权重仍在那边,但大多数场景下咱们只需要那 28B 的智能就够了。

从技术角度看,这算是 MoE 架构在多模态领域的又一次落地。此前类似的稀疏激活思路多用于纯文本模型,而 InternVL3.5-241B-A28B-Flash 将其扩展到了视觉-语言任务中。它证明了即便只激活小部分参数,模型在理解图像和文字结合的任务时依然能保持较高水准。
这确实是一次令人瞩目的发布。对于关注多模态 AI 的研究者与开发者来说,InternVL3.5-241B-A28B-Flash 提供了一条低门槛、高潜力的实践路线——用一个激活参数仅 28B 的模型,去探索 241B 知识储备的上限。