



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
HuggingFaceTB推出100M参数MoE文本生成模型nanowhale-base
时间:2026-06-02 12:42:02 编辑:袖梨 来源:一聚教程网
HuggingFaceTB推出100M参数MoE文本生成模型nanowhale-base
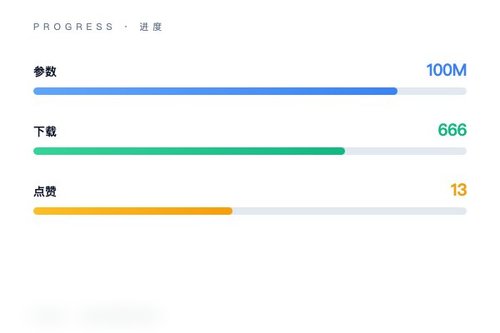
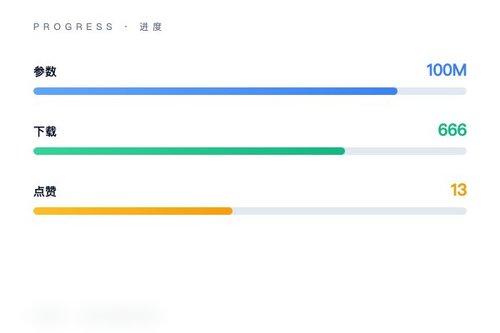
HuggingFaceTB日前在Hugging Face平台发布了名为nanowhale-100m-base的文本生成模型。这款模型拥有1亿参数,采用MoE(混合专家)架构,属于DeepSeek v4系列,主要面向对话与因果语言生成任务。模型上线后已获得666次下载和13个点赞,标签包括transformers、safetensors、custom_code等,目前处于预训练状态。
为什么说它值得关注?因为MoE架构在参数量固定的情况下,能通过激活部分专家层来提升效率。nanowhale-100m-base虽然只有1亿参数,但借助DeepSeek v4的技术积累,其文本生成能力可能超出同类模型——这确实是个挺有意思的尝试。
从Hugging Face的页面信息来看,该模型支持conversational和custom_code标签,意味着它具备对话交互能力,并且允许用户自定义代码进行扩展。对于开发者而言,这其实降低了二次开发的门槛,毕竟不用从头训练一个模型,直接基于这个预训练模型微调就行。
模型的pipeline tag明确为“text-generation”,属于因果语言模型(causal-lm)。这类模型在生成连续文本时,会基于上文预测下一个词,适合聊天机器人、故事生成等场景。不过,MoE架构的推断过程通常比普通模型更复杂,需要平衡计算资源与生成质量——这算是个技术挑战,但HuggingFaceTB显然找到了解决方案。
目前nanowhale-100m-base的下载量不算高,只有666次,但考虑到它刚上线不久,这个数据还算正常。模型的标签里还有“deepseek”和“deepseek_v4”,说明它继承了DeepSeek的优化思路。那么,它在实际任务中的表现会比同等规模的Dense模型好吗?
总的来说,这是一个轻量级但架构先进的文本生成模型。对于资源有限的团队或开发者来说,它提供了一个不错的起点:参数少、部署快,又有MoE和DeepSeek v4的加持。咱们可以期待它在社区中的进一步应用,看看它能否在小型模型中打开局面。
相关文章
- Mistral AI 发布 675B 参数大模型 Mistral Large 3 06-02
- 挖掘者米娜:气动臂环饰品获取方法详解 06-02
- 空洞骑士丝之歌:悲恸之海DLC上线前的最终更新来临 06-02
- OpenGVLab开源VideoChat-R1_5-7B视频模型 06-02
- 芒果TV怎样关联第三方账号 06-02
- 杀戮尖塔2人气飙升-制作团队放话将超越丝之歌 06-02