



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Stability AI发布sv4d2.0视频转4D模型
时间:2026-06-02 13:45:01 编辑:袖梨 来源:一聚教程网
Stability AI发布sv4d2.0视频转4D模型
Stability AI近日发布了sv4d2.0,这是一个能把普通视频直接转换成4D场景的模型。根据Hugging Face上的公开数据,该模型目前获得415次下载和68个点赞,标签包括diffusers、video-to-4d、stable-diffusion,并关联了arXiv论文2503.16396。这是继sv4d1.0之后的重大升级,开发者可以直接用它来从单段视频中提取完整的时空信息——说白了,就是让视频里的物体不仅有长宽高,还有时间维度的动态变化。

视频转4D到底意味着什么?以前的3D模型只能捕捉静态形状,比如一座雕塑的各个角度;但现实世界里的汽车在跑、火焰在跳、人在走路,这些都是随时间变化的。sv4d2.0恰恰解决了这个问题:它输入一段视频,输出带运动轨迹的4D模型。老实说,这技术对影视特效、游戏开发、AR/VR内容的制作效率提升几乎是颠覆性的——创作者不用再逐帧手动绑定骨骼或重建动态场景了。
模型本身的规格其实挺有意思。它基于Stable Diffusion架构,使用diffusers库实现,许可证标注为“other”,地区限定美国。从技术文档看,它应该是通过多视角视频帧生成一致性的4D表示。不过模型体积和运行时硬件需求没有公开,用户需要自己去尝试。但换个角度想,开源社区能直接下载权重文件进行实验,这本身就已经降低了使用门槛——要知道,以前的4D重建工具往往需要专业级硬件和复杂的算法调优。
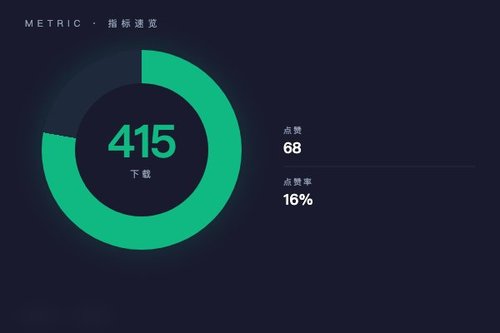
数据层面值得关注。截至发稿时,该模型在Hugging Face上的下载量仅为415次。这个数字并不算高,为什么?原因可能有两个:一是模型刚刚发布,传播还需要时间;二是它需要用户具备一定的深度学习知识才能跑通。但68个点赞说明早期使用者对效果的认可度还不错——毕竟点赞率超过16%,这在技术模型里算是一个积极信号。
竞争格局呢?其实业内早已有类似尝试,比如一些研究团队用NeRF(神经辐射场)做动态场景重建,但sv4d2.0选择了基于扩散模型的路径,并且直接以视频作为输入,省去了多视角相机阵列的麻烦。没错,这恰恰是它的核心优势:一条视频,一个模型,搞定4D。这种“端到端”的思路越来越被行业看好——凭什么做4D就非要拍几十个角度才行? одной视频也可以。
总结一下。Stability AI的sv4d2.0给创作者带来了新的可能:从视频到4D模型的转换变得标准化、工程化。虽然当前下载量还不算爆炸,但它的技术方向确实直指未来数字内容生产的痛点。需要提醒的是,模型目前仅限美国地区访问,国内用户可以通过官方渠道获取最新动态。这次更新让我们看到,视频转4D不再是实验室里的魔术,而是正在变成可复用的工具——这难道不值得兴奋吗?
相关文章
- 如何在网页版登录谷歌邮箱账号 06-02
- 字节跳动开源8B参数时序对话模型ChatTS-8B 06-02
- 空洞骑士丝之歌开荒必备道具推荐 06-02
- 排兵布阵游戏官网下载入口:最新官方正版安装地址获取 06-02
- 字节跳动开源多模态模型Vidi1.5-9B,支持视频与音频理解 06-02
- AI技术辅助设计立体饭盒的实用指南 06-02