



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
字节跳动推出Video-As-Prompt-Wan2.1-14B图像转视频模型
时间:2026-06-02 14:12:01 编辑:袖梨 来源:一聚教程网
字节跳动推出Video-As-Prompt-Wan2.1-14B图像转视频模型
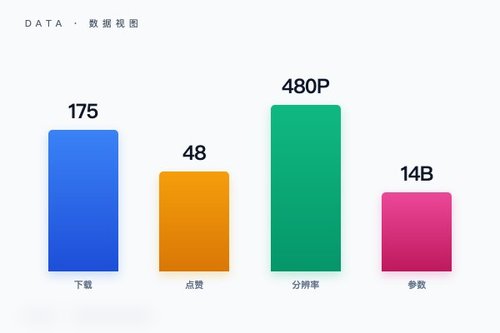
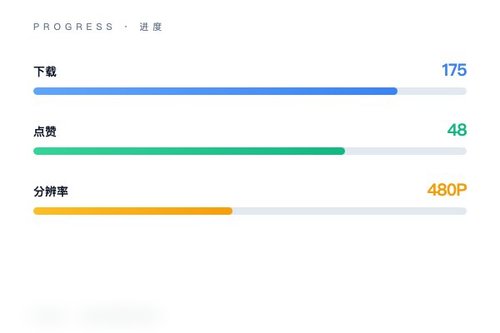
字节跳动日前向人工智能社区正式推出“Video-As-Prompt-Wan2.1-14B”图像转视频模型。这个模型已经在Hugging Face平台上线,获得了175次下载和48次点赞,看得出来开发者社区对它的关注度挺高。它基于Wan-AI的Wan2.1-I2V-14B-480P-Diffusers基础模型进行微调,专门用来把静态图片转化为动态视频。
为什么字节跳动给它起名“Video-As-Prompt”?
这个名字其实点出了它的核心思路:把一段视频当作“提示词”来指导图片生成动态内容。与传统的文字转视频不同,这个模型输入一张图片,输出一段连贯的视频画面。根据公开资料,它采用Diffusers框架的WanImageToVideoPipeline管线,模型权重使用safetensors格式存储。这种做法挺有意思,相当于让AI先理解视频的运动逻辑,再应用到静态图像上。
技术细节与开源生态
在技术层面,该模型使用了BianYx/VAP-Data数据集进行训练,并关联了Arxiv论文编号2510.20888。这意味着学界和开发者可以查阅论文了解具体原理。模型采用的Apache-2.0开源协议,确实为后续的二次开发提供了便利。不过,咱们得注意,真正的商业应用效果还需要更多测试验证。
适用场景其实很直观
图像转视频技术在短视频创作、广告素材生成、动画原型制作等领域有直接应用价值。创作者只需要提供一张静态图,就能快速生成一段动态内容。这比逐帧绘制动画要效率得多。但话说回来,目前模型输出的视频分辨率是480P,对于高清需求可能还需要进一步优化。
社区反馈与行业影响
从Hugging Face平台的数据来看,48次点赞和175次下载表明社区对这个方向是有兴趣的。毕竟在AI视频生成领域,字节跳动之前已经推出过多个模型,这次“Video-As-Prompt”方案算是给行业提供了另一种技术思路——凭什么图像转视频一定要依赖文字描述呢?直接让视频本身做提示,或许更能保留运动细节。整体而言,这是一个值得跟踪的开源项目。
相关文章
- 我的世界末影箱使用指南 06-02
- xAI去年亏64亿美元,SpaceX文件揭示Grok扩张不止 06-02
- 我的世界如何驯服马匹成为坐骑 06-02
- 洛克王国流火禁地的位置在哪里 06-02
- 英伟达第一财季净利润583亿美元同比增211% 06-02
- 5g消息详细介绍 06-02