



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
字节跳动开源Vidi1.5-9B:基于Gemma-2的视频音频多模态模型
时间:2026-06-02 14:33:01 编辑:袖梨 来源:一聚教程网
字节跳动日前开源了Vidi1.5-9B,一款基于Gemma-2的视频音频多模态模型。该模型已在Hugging Face上架,下载量已有35次,收获10个点赞。它不是那种只读论文不开放权重的“画饼”项目,而是实打实把模型文件发了出来——许可证是CC-BY-NC-4.0,非商用场景下研究者可以随便玩。
Vidi1.5-9B的基座是Google的Gemma-2-9B-it,字节跳动在此基础上做了视频和音频输入的适配。标签里写着dattn_gemma2,暗示可能有动态注意力机制来处理时序信息。两个arXiv论文编号2504.15681和2511.19529挂在上面,想深挖技术细节的可以自己去翻。说实话,把视频和音频塞进同一个9B模型,挺考验架构设计的。

多模态模型咱们见多了,但能同时理解视频画面和音频内容的不算多。Vidi1.5-9B直接给了一个现成的方案:输入一段视频,它既能识别视觉动作,又能听出背景音里的对话或环境声。这种能力放到智能安防、内容审核、视频检索这些场景里,实用价值确实高。凭什么说它重要?因为它降低了多模态研究的门槛——你不需要从零训练,拿这个开源权重微调就行。
开源这件事本身,字节跳动近两年动作越来越快。从语言模型到视觉模型,再到现在的音视频多模态,几乎每个热门方向都跟进了。Vidi1.5-9B选Gemma-2做基座,也说明他们对Google生态的兼容态度——毕竟Gemma-2本身是轻量级开源模型,社区生态成熟,微调工具链齐全。这对后来的开发者而言,算是省了不少麻烦。
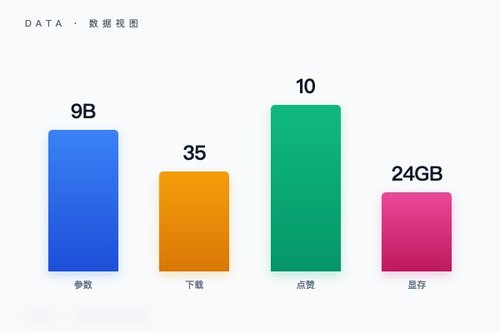
目前模型只提供了safetensors格式,权重安全且加载效率高。虽然下载量才35,但考虑到发布时间不长,关注度还在爬坡。如果要自己跑跑看,建议配24GB以上的显存,毕竟9B参数加上视频帧处理,显存压力不小。不过,连个门槛都不设的话,凭什么让真正想用的人珍惜?
最后提一句,模型是非商用许可,搞研究没问题,商业化得找字节跳动谈授权。这种“先开源蹭热度,后收费赚合作”的打法,咱们在AI行业见得还少吗?但不管怎么说,有得用总比没得用好——尤其是这个视频音频双模态的开源模型,确实给学术界和工业界都塞了一把好用的钥匙。