



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
字节跳动推出ATI模型:基于Wan2.1的图像转视频方案
时间:2026-06-02 14:48:01 编辑:袖梨 来源:一聚教程网
字节跳动推出ATI模型:基于Wan2.1的图像转视频方案
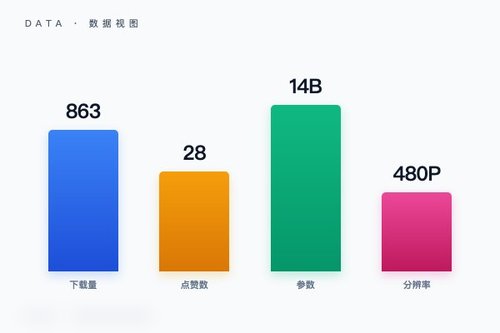
字节跳动日前在Hugging Face平台推出ATI模型,这是一套基于Wan2.1的图像转视频方案。该模型在Hugging Face上架后已经收获863次下载和28次点赞,标签显示它属于i2v(图像到视频)类别,并且使用了safetensors格式。为什么字节跳动要基于Wan2.1来开发这个模型?其实挺值得琢磨的——Wan2.1本身已经是相当成熟的图像转视频基础模型,ATI团队在它基础上做了专门的finetune,说白了就是针对特定场景进行了优化。
ATI模型的技术特色
从模型卡信息来看,ATI的基座模型明确指向Wan-AI/Wan2.1-I2V-14B-480P,这意味着它继承了Wan2.1的14B参数规模和480P分辨率处理能力。不过ATI并非简单复制,而是通过finetune方式让模型更适配特定图像转视频任务。有意思的是,模型同时标注了“base_model”和“base_model:finetune”两个关键词,这说明开发团队既保留了Wan2.1的原始架构,又加入了针对性的微调策略——咱们可以理解成既尊重原版能力,又做了定制化改造。
为什么基于Wan2.1?
Wan2.1这套模型本身就很能打,480P版本在图像转视频领域早有积累。ATI团队选择它作为基底,其实是看中了它的稳定性和泛化能力。你能想象吗?一个14B参数的模型要同时处理图像特征提取和视频帧生成,计算复杂度确实很高。ATI的做法是精准优化Wan2.1的某些环节,而不是从头训练——这不就省去了大量算力成本吗?开源社区对此反应挺积极的,毕竟用Apache-2.0许可证发布意味着任何人都可以合法地拿来用。
开源与社区价值
ATI模型选择在Hugging Face上以Apache-2.0许可证发布,这规范了使用边界——任何人都能基于它做二次开发或商业应用。模型标签里包含了“diffusers”这个关键词,说明它和扩散模型生态高度兼容。说真的,这种开源姿态对图像转视频领域是件好事,开发者可以直接下载safetensors格式的模型权重,再配合diffusers框架使用。这可能加速很多应用场景落地,比如短视频创作、广告素材生成,甚至影视前期预览。
未来想象空间
图像转视频技术现在越来越受关注,ATI模型的出现算是给这个赛道添了一把柴。它基于Wan2.1这个成熟基底,又做了针对性的finetune,算是“站在巨人肩膀上”的方案。不过话说回来,480P的分辨率限制能通过后续版本突破吗?既然模型已经开源,社区的力量或许能推动这方面改进。字节跳动这步棋走得挺聪明——把基础能力开源出来,让更多人参与优化,这确实是个良性循环。