



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
OpenGVLab开源VideoChat-R1_5-7B视频模型
时间:2026-06-02 15:06:01 编辑:袖梨 来源:一聚教程网
OpenGVLab开源VideoChat-R1_5-7B视频模型
OpenGVLab近期在Hugging Face上正式开源了VideoChat-R1_5-7B视频模型。这款模型基于Qwen/Qwen2.5-VL-7B-Instruct进行开发,定位于视频与图像文本之间的多模态理解任务,属于当前视频语言模型领域挺受关注的一个新选择。
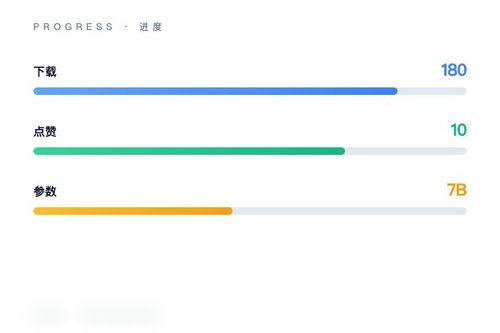
模型的核心特点
从Hugging Face页面数据看,该模型收获了180次下载与10次点赞,标签涵盖transformers、safetensors、qwen2_5_vl等多项技术指标。它支持将视频内容直接转化为文本描述,这在实际应用中确实能帮助开发者处理视频问答、内容摘要等任务。说实话,能在预训练大模型基础上快速推出专用版本,这本身就是效率的体现。
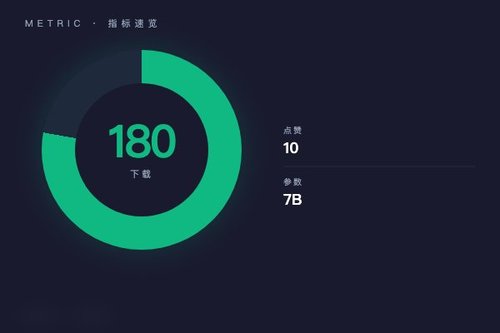
技术细节与适用场景
模型还关联了arXiv上的两篇论文(编号2509.21100与2504.06958),如果你对技术原理感兴趣,可以去查阅原始文献。它属于“video-text-to-text”管道类别,意味着输入视频或图像,输出对应的文本解读。这跟当前图像文本对话模型的热点趋势是一致的,OpenGVLab这次算是给了社区一个可复用的基础工具。
开发者的选择逻辑
为什么许多人更愿意用像Qwen2.5-VL这样的基座模型?因为它自带强大的视觉理解能力,在此基础上定制视频对话模型,能节省大量从头训练的时间。现在VideoChat-R1_5-7B直接开源出来,等于说咱们可以直接下载权重开始实验或二次开发,这难道不是一件效率爆棚的事情吗!
实际部署与后续建议
对于想尝试的团队,直接上Hugging Face搜索OpenGVLab/VideoChat-R1_5-7B即可获取模型文件。需要提醒的是,使用前务必确认硬件环境是否支持7B参数级别的推理。模型文件的safetensors格式和transformers接口兼容性都不错,部署起来属于中规中矩的难度。
这波开源的意义
可以说,OpenGVLab通过开源VideoChat-R1_5-7B,给多模态视频理解领域又添了块砖。它未必是颠覆性的突破,但胜在够用、可直接落地。对于国内外的AI开发者来说,多一个经过验证的视频语言模型可用,总归是好事。也许后期会有更多基于该模型的社区微调版本涌现,至于是不是能形成生态链,咱们可以边走边看。
相关文章
- 异环棉绒绒之乱任务通关指南:异环棉绒绒之乱任务详细攻略 06-02
- 轻量级MP3播放器_SWF运行版 V1.00 免费版 06-02
- Authorization如何防范CSRF攻击 06-02
- Hive数据库中的数据分区方法 06-02
- ubuntu如何更新定时器 06-02
- 使用env命令删除环境变量的方法 06-02