



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
实战分享:SeaTunnel(2.3.12)高阶应用解析(一)-核心概念篇:数据流原理
时间:2026-05-22 09:15:01 编辑:袖梨 来源:一聚教程网
Apache SeaTunnel作为新一代数据集成工具,其核心数据流模型为复杂场景提供了灵活解决方案。本文将深入解析其多源汇流机制与DAG执行原理。
一句话总结(先给结论)
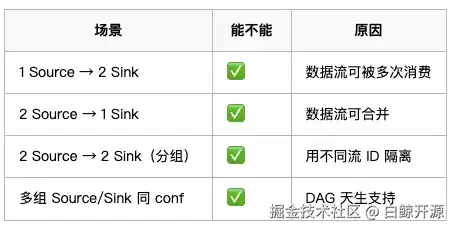
两个数据源可同时汇入单个接收端,这是SeaTunnel数据流模型的典型特征。
一、SeaTunnel的核心概念:数据流
整个系统架构完全建立在数据流这一核心概念之上。
数据流是什么?
区别于传统的数据表或文件,其本质是:
Record1 → Record2 → Record3 → ...
每个插件都在"操作数据流"
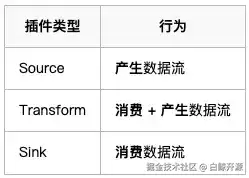
二、plugin_output/plugin_input的真实含义(非常重要)
这些配置参数需要从原理层面重新理解。
1️⃣ plugin_output
plugin_output = "source_data_output_1"
实际代表的是:
DataStream<ID = source_data_output_1>
2️⃣ plugin_input
plugin_input = "source_data_output_1"
用一句话说透
plugin_output / plugin_input = 数据流的"连接端口"
三、SeaTunnel的DAG模型(你现在已经用到了)
实际运行时会构建如下拓扑结构:
SourceA ─┐
├──► Sink
SourceB ─┘SeaTunnel内部会构建这样的DAG:
DataStream A ─┐
├──► Sink Operator
DataStream B ─┘
关键点:为什么能合并?
当配置中出现:
sink {
jdbc {
plugin_input = "a,b"
}
}
系统内部会执行以下操作:
- 汇集多个输入流
- 整合为逻辑输入流
- 按记录顺序写入
️ 特别注意:
- 这不是SQL的join操作
- 不同于SQL的union
- 属于流级别的追加合并
四、这和你理解的"SQL/ETL"有什么本质区别?
这是容易产生混淆的关键点。
SQL的世界
SELECT * FROM A
UNION ALL
SELECT * FROM B
体现的是"结果集语义"
SeaTunnel的世界
A 的 Record 流
B 的 Record 流
↓
Sink 持续消费
体现的是"流处理语义"
只要数据结构一致,即可汇入同一接收端。
五、Schema在数据流里的地位(你一定要记住)
SeaTunnel合流的前提:
- 字段数量相同
- 字段类型兼容
- 字段名称对齐(或可映射)
否则会导致:
- 运行时直接报错
- 或写入失败
实验成功的关键就在于数据结构对齐。
六、SeaTunnel的"数据流转模型"正式定义(给你一个标准版)
可直接用于方案设计和文档编写:
七、这对你Builder/Strategy设计的直接影响(重点)
设计时需要明确三个要点:
1️⃣ Builder必须支持N源到M汇
需要构建图模型而非简单映射。
2️⃣ plugin_output是核心要素
Builder中必须确保每个数据流都有明确标识。
3️⃣ Sink支持多输入流
即使配置中只指定单个输入:
plugin_input = "s1"
底层实现应为:
Set<DataStream>
八、你现在已经"踩过并验证"的几个关键事实
已验证的重要结论包括:
系统基于DAG而非线性ETL 多源可汇聚至单汇 合并是流式追加 数据结构必须对齐 配置描述的是数据流而非SQL
九、总结
SeaTunnel的核心只有3个角色
Source → Transform → Sink
(产生流) (改流) (吃流)
数据流怎么"连"?
核心机制在于:
plugin_output:标识数据流来源plugin_input:指定数据流去向
典型应用场景示例:
┌──────────┐
│ Source A │──┐
└──────────┘ │
├──▶ Sink
┌──────────┐ │
│ Source B │──┘
└──────────┘
本文系统解析了SeaTunnel的数据流机制,掌握这些原理将帮助开发者构建更高效的数据集成方案。