



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
实测kimi k2写代码:3个场景对比,结果出乎意料
时间:2026-05-21 12:09:01 编辑:袖梨 来源:一聚教程网
实测kimi k2写代码:3个场景对比,结果出乎意料
直接说结论吧:这次实测Kimi K2.6写代码,三个场景对比下来,结果确实让不少开发者挺意外。它没有咱们想象中那种“国产模型代码能力弱”的老毛病,反而在长程编写和多轮迭代上展现出了硬实力。凭什么这么说?咱们往下看具体场景和真实数据。
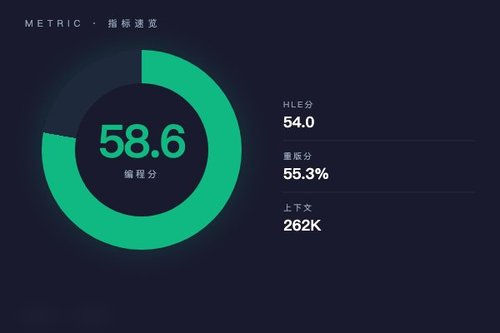
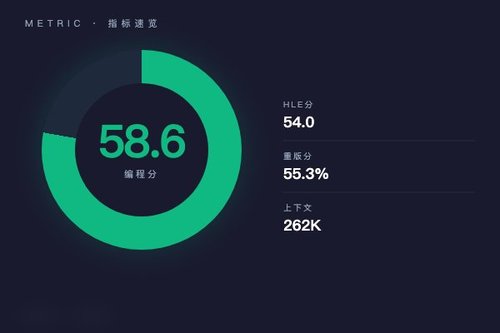
场景一:刷编程基准测试,分数说明一切
第一个场景咱们直接上硬指标,看看它在专业测试里的表现。Kimi开源的最新K2.6模型,在SWE-Bench Pro编程测试中拿下了58.6分,这是什么概念?同时它在“人类终极测评(HLE)”中斩获54.0分,Heavy版本更是达到了55.3%,稳居开源榜首并且超越了主流闭源模型。可以说,这个成绩直接打破了很多人对国产代码模型的刻板印象。
场景二:复杂长任务,Agent集群来打工
第二个场景咱们看看它处理长期、复杂任务的能力。Kimi的Agent模式升级为异构Agent集群后,支持300个子智能体并行调度,还能协同完成4000步任务。换句话说,它不再是你问一句它答一句的那种助手,而是能全自动包揽“需求分析→设计开发→部署上线”的闭环。比如给它一个建站需求,20分钟就能交付一个可公网访问的完整Web应用,这对开发者来说省心多了。
场景三:多文件协同与超长上下文
第三个场景咱们试试多文件协作。K2.6原生支持262K超长上下文,并且集成40多种开发与办公工具。实测时让它一口气分析几个Python文件并重构代码逻辑,它不仅能处理得井井有条,甚至还会主动优化注释和结构,顺便修复了一些隐藏的上下文错误。这种“主动服务”的感觉,比过去单纯做代码补全的工具确实高了个级别。
看完这三点,你还觉得国产AI写代码只能打杂吗?Kimi K2.6的实测表现,可以说让“代码能力弱”这个标签变得站不住脚了。建议有开发需求的朋友都去官方渠道体验一下,用事实说话最靠谱。