



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
网络爬虫案例解析
时间:2022-06-25 23:25:22 编辑:袖梨 来源:一聚教程网
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常被称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,已被广泛应用于互联网领域。搜索引擎使用网络爬虫抓取Web网页、文档甚至图片、音频、视频等资源,通过相应的索引技术组织这些信息,提供给搜索用户进行查询。网络爬虫也为中小站点的推广提供了有效的途径,网站针对搜索引擎爬虫的优化曾风靡一时。
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
当然,上面说的那些我都不懂,以我现在的理解,我们请求一个网址,服务器返回给我们一个超级大文本,而我们的浏览器可以将这个超级大文本解析成我们说看到的华丽的页面
那么,我们只需要把这个超级大文本看成一个足够大的String 字符串就OK了。
下面是我的代码
| |
| 代码如下 | 复制代码 |
packagemain.spider; importorg.jsoup.Jsoup; importorg.jsoup.nodes.Document; importorg.jsoup.nodes.Element; importorg.jsoup.select.Elements; importjava.io.IOException; /** * Created by 1755790963 on 2017/3/10. */ publicclassSecond { publicstaticvoidmain(String[] args)throwsIOException { System.out.println("begin"); Document document = Jsoup.connect("http://tieba.baidu.com/p/2356694991").get(); String selector="div[class=d_post_content j_d_post_content clearfix]"; Elements elements = document.select(selector); for(Element element:elements){ String word= element.text(); if(word.indexOf("@")>0){ word=word.substring(0,word.lastIndexOf("@")+7); System.out.println(word); } System.out.println(word); } } } | |
我在这里使用了apache公司所提供的jsoup jar包,jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
在代码里,我们可以直接使用Jsoup类,并.出Jsoup的connect()方法,这个方法返回一个org.jsoup.Connection对象,参数则是网站的url地址,Connection对象有一个get()方法返回Document对象
document对象的select方法可以返回一个Elements对象,而Elements对象正式Element对象的集合,但select()方法需要我们传入一个String参数,这个参数就是我们的选择器
String selector="div[class=d_post_content j_d_post_content clearfix]";
我们的选择器语法类似于jquery的选择器语法,可以选取html页面中的元素,选择好后,就可以便利Elements集合,通过Element的text()方法获取html中的代码
这样,一个最简单的网络爬虫就写完了。
我选择的网址是 豆瓣网,留下你的邮箱,我会给你发邮件 这样一个百度贴吧,我扒的是所有人的邮箱地址
附上结果:
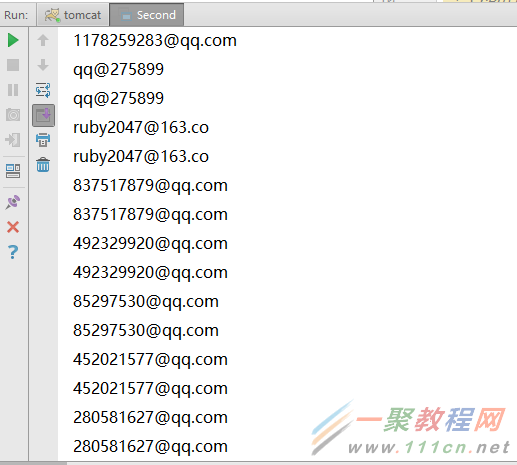
相关文章
- 《星球工匠》电路板获得方法 04-19
- 《长安小时光》下载方法方法 04-19
- 《下一站江湖2》情比金坚作用介绍 04-19
- 《星露谷物语》获得地板方法 04-19
- 《下一站江湖2》虞令羽之墓开启方法 04-19
- 《下一站江湖2》神刀鬼谕获取方法 04-19