



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Oracle RAC(4 TB ASM) 数据库恢复详细记录
时间:2022-06-29 09:33:04 编辑:袖梨 来源:一聚教程网
6月底我们接到某客户的紧急支持请求,其客户数据库在不久前由于机房停电,导致数据库重启后无法启动。
我们通过teamviewer远程初步分析了alert log以及kfed读取了几个disk 发现,数据库无法启动的根本原因在于ASM diskgroup无法mount。而ASM diskgroup 无法mount的根本原因在于,ASM元数据出现损坏,其中表现为ASM 启动时无法进行事务恢复。
这里我们先不去纠结为什么会坏。对于asm的元数据如果出现损坏,那么修复的难度可想而知。
这里我采取了非常简单的数据库恢复方案,计划用AMDU抽取数据库文件,然后将数据库open,最后再重建原数据库磁盘组,最后通过Oracle rman 的backup as copy 方式将数据库还原回去。
想象是比较美好的,经过与客户长达1天的沟通协调之后,发现客户根本协调不到存储资源,而数据库环境本地可以空间也就不足100G。我们知道,整个数据库的磁盘组是6TB,其中数据库文件大约在4T左右,显然这是比较麻烦的事情。
无奈之下,客户从京东买了一个6TB的移动硬盘,经过一番努力之后,挂上移动硬盘,通过AMDU抽取文件测试,发现速度大约为5m/s。这是一个500m的undo文件复制到移动硬盘的速度测试:
root@jlzgdb1 # time dd if=/amdu/datafiles/undotbs2.dbf of=/data/undo_test.dbf bs=8192
64001+0 records in
64001+0 records out
real 1:23.7
user 0.2
sys 2.2
大家可以计算一下,大约需要10天左右。这样是这样进行下去,那么整个恢复过程估计需要15天了,这是无法接受的。
后面跟客户了解了一下,客户的应用服务器是windows环境,我通过在windows共享文件,NFS共享到soalris,测试amdu抽取文件的速度大约可以达到15m/s。虽然这也是非常之慢的,但是相比之前已经好很多了,客户也可以接受了。
这里不得不说一下windows和Soalris之间配置NFS共享,也是一个比较麻烦的事情。折腾了几个小时才搞定这个问题。这里我简单记录一下配置的步骤,如下:
--solaris 启动nfs服务
svcadm -v enable -r network/nfs/server
--windows
安装nfs服务
设置文件夹共享,nfs共享
设置用户映射
nfsfile /v /ru=-2 /rg=-2 /s /cx F:oradata
---soalris挂载nfs
mount 172.16.30.212:/oradata /data
后续的步骤相对就简单了,都是传统的数据库恢复套路。如下是AMDU抽取文件的步骤:
......
./amdu -dis '/dev/rdsk/emcpower*' -extract JLZGRACGROUP.316 -output /data1/irms_data.dbf
./amdu -dis '/dev/rdsk/emcpower*' -extract JLZGRACGROUP.317 -output /data1/irms_data_his.dbf
./amdu -dis '/dev/rdsk/emcpower*' -extract JLZGRACGROUP.318 -output /data1/irms_index.dbf
./amdu -dis '/dev/rdsk/emcpower*' -extract JLZGRACGROUP.319 -output /data1/irms_index_his.dbf
./amdu -dis '/dev/rdsk/emcpower*' -extract JLZGRACGROUP.326 -output /data1/gis_data.dbf
./amdu -dis '/dev/rdsk/emcpower*' -extract JLZGRACGROUP.323 -output /data1/gis_index.dbf
......
这里我们需要注意的是,amdu不仅可以抽取数据文件,还可以抽取spfile、controlfile、以及redo、archivelog等。
对于AMDU工具抽取文件的过程,就单纯的命令而言,这是比较简单的。其中的关键就是我们必须知道文件在ASM diskgroup中对应的asm file number号。注意,这里的file number,并非数据库(DB)中的file number。
Oracle ASM的元数据中,其中alias directory 里面记录了数据库文件和asm 之间的一个映射关系。也就是说我们只要能够通过kfed读取alias 的数据,也就能够知道数据文件的asm file number是多少。
当然,很多情况之下,如果你添加数据库文件是alter tablespace xxx add datafile ‘+DATA’ …这样的方式,那么直接查询控制文件即可获得asm file number。这里不多说。
最后我dbv check了一下数据库文件,发现就undo存在几个坏块,其他文件均ok。不过比较郁闷的是,进行正常recover database恢复时,提示需要recover的归档找不到。这是怎么一回事呢?
我们来看下数据库文件头的scn 情况。
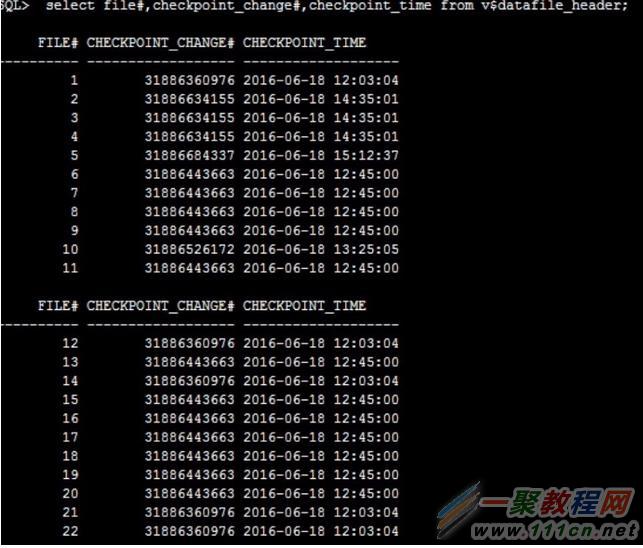
我们可以发现,从文件头的scn来看,差距大概在3个小时左右。而recover 时也确实需要比较旧的archivelog。而这中间差距的几个小时的归档,我们通过kfed 读取asm diskgroup元数据发现并没有找到。
为什么会丢失呢?其实很简单,可能这3个小时的归档也就6个archivelog,很可能在存储cache中,并没有写入到磁盘上。那么当掉电之后,这几个archivelog 肯定也丢失了。
当归档不全的情况之下,我们amdu抽取的current redo logfile已经没有意义了。我们只能将该数据库强制open,然后重建数据库。这里我简单描述一下数据库的open过程,以及恢复过程中遇到的一些错误:
首先利用amdu 抽取的控制文件进行mount,发现报如下错误:
Sat Jul 2 23:05:15 2016
ALTER DATABASE MOUNT
Sat Jul 2 23:05:19 2016
Errors in file /var/datang/oracle/admin/xxx/udump/xxx1_ora_6919.trc:
ORA-00600: internal error code, arguments: [kccpb_sanity_check_2], [3811063], [3770626], [0x000000000], [], [], [], []
Sat Jul 2 23:05:19 2016
ORA-600 signalled during: ALTER DATABASE MOUNT...
Sat Jul 2 23:05:20 2016
这个错误很常见,我们在数据库恢复过程中经常碰到该错误。假设你是第一次遇到这个错误,你该如何判断该错误是什么问题?跟什么东西有关系呢?从ORA-00600错误的关键字,kccpb可以看出,这跟控制文件有关系,其中还包含了check关键字。说明这是在数据库mount过程中,进行某些check检查,发现了某些数据异常。那么后面的2个数字:3811063,3770626是什么意思呢?
有人或许会说,这有没有可能是scn?这里不排除这种可能性,如果你稍微有一定经验,那么很容易排除这个可能性。为什么?
首先对于一个运行超过3年的Oracle数据库,scn不可能这么小。其次从Oracle 10g开始,会自动产生snap controlfile的备份,在ORACLE_HOME/dbs目录下,我们可以利用该备份进行mount,然后去检查数据库文件的scn情况。
那么这个错误到底是什么意思呢?这里我猜测肯定是某个sequence number的东西,Oracle在mount的过程中认为读取的数据应该是3811063,但是实际上读取的数据确实3770626,2者之间存在差异。也就是说,Oracle认为控制文件已经损坏。
实际上,Oracle metalink 针对该错误进行了详细描述,其实也提供了解决方案,供大家参考:ORA-00600: [kccpb_sanity_check_2] During Instance Startup (文档 ID 435436.1)
看过该文档的人应该都知道,解决该错误的方法就是利用备份进行恢复,要么就是重建控制文件。既然如此,那么我们就来重建控制文件吧:
CREATE CONTROLFILE REUSE DATABASE "JLZGDB" NORESETLOGS ARCHIVELOG
MAXLOGFILES 192
MAXLOGMEMBERS 3
MAXDATAFILES 1024
MAXINSTANCES 32
MAXLOGHISTORY 18688
LOGFILE
GROUP 1 (
'/data1/redo12.log',
'/data1/redo11.log'
) SIZE 100M,
GROUP 2 (
'/data1/redo22.log',
'/data1/redo21.log'
) SIZE 100M,
GROUP 3 (
'/data1/redo31.log',
'/data1/redo32.log'
) SIZE 100M,
GROUP 4 (
'/data1/redo41.log',
'/data1/redo42.log'
) SIZE 100M
-- STANDBY LOGFILE
DATAFILE
'/amdu/datafiles/system01.dbf',
'/amdu/datafiles/undotbs1.dbf',
'/amdu/datafiles/sysaux.dbf',
'/amdu/datafiles/users.dbf',
'/amdu/datafiles/undotbs2.dbf',
'/data1/irms_data.dbf',
'/data1/irms_data_his.dbf',
'/data1/irms_index.dbf',
'/data1/irms_index_his.dbf',
'/data1/gis_data.dbf',
'/data1/gis_index.dbf',
'/data1/ams_java_data.dbf',
'/data1/rdms_itf.dbf',
'/data1/rdms_data.dbf',
'/data1/rdms_app.dbf',
'/data1/rdms_indxitf.dbf',
'/data1/rdms_indxdata.dbf',
'/data1/rdms_indxapp.dbf',
'/data1/sde.dbf',
'/data1/bjdvdata.dbf',
'/amdu/datafiles/undotbs3.dbf',
'/data1/nc_data01.dbf'
CHARACTER SET ZHS16GBK
;
重建完毕之后,进行一次不完全恢复,然后尝试直接open数据库,发现遇到如下错误:
Sat Jul 2 23:36:08 2016
Errors in file /var/datang/oracle/admin/jlzgdb/udump/xxx1_ora_22249.trc:
ORA-00600: internal error code, arguments: [2662], [7], [1821589910], [7], [1821750102], [8388617], [], []
Sat Jul 2 23:36:09 2016
Errors in file /var/datang/oracle/admin/xxx/udump/xxx1_ora_22249.trc:
ORA-00600: internal error code, arguments: [2662], [7], [1821589910], [7], [1821750102], [8388617], [], []
Sat Jul 2 23:36:09 2016
Error 600 happened during db open, shutting down database
USER: terminating instance due to error 600
Instance terminated by USER, pid = 22249
这个错误也很常见。很多人都已经知道如何处理这种情况下,那就是推进SCN。那么这里如何推进scn呢?
由于该数据库是Oracle 10g,且没有安装最新的psu;因此我们可以直接使用oracle 10015 event来推进scn,命令如下:
alter session set events ’10015 trace name adjust_scn level n’;
其中的n表示level,那么这个level应该是多少呢?应该是4*7=28,为了稳妥期间,我们一般设置比28稍微大一点,因此可以设置30.
经过10015 event的处理之后,再次open数据库,你会发现数据库已经open了,但是很快就会crash。因为会如下错误:
*********************************************************************
Database Characterset is ZHS16GBK
Opening with internal Resource Manager plan
where NUMA PG = 1, CPUs = 64
Sat Jul 2 23:49:14 2016
Errors in file /var/datang/oracle/admin/jlzgdb/udump/jlzgdb1_ora_27273.trc:
ORA-00600: internal error code, arguments: [4194], [58], [41], [], [], [], [], []
Doing block recovery for file 2 block 33408
Block recovery from logseq 1, block 61 to scn 32212254769
Sat Jul 2 23:49:15 2016
同一,该错误也太常见了。我们知道,对于ORA-00600 后面的错误编号,如果是在4000–6000的范围中,那么表示跟undo有关系。实际上我们之前dbv检查文件也确实发现undo有极少量的坏块存在。那么这里怎么处理这个问题呢?
既然undo存在文件,那么我们知道数据库在open的时候需要进行事务的rollback,而事务回滚则跟undo存在极大关系。那么这里我们可以通过几种方式来解决该问题:
1、通过undo_manangment=manual
2、._offline_rollback_segments
3、10513 event来禁止smon 进行事务恢复.
很明显,这里我选择第一种方式,更为简单,通过修改pfile即可很快解决该问题。通过参数修改很顺利打开了数据库,然后检查alert log发现会有如下类似的错误:
Sat Jul 2 23:59:20 2016
Errors in file /var/datang/oracle/admin/xxx/bdump/xxx1_j004_6045.trc:
ORA-12012: error on auto execute of job 42567
ORA-08102: index key not found, obj# , file , block ()
ORA-08102: index key not found, obj# ORA-08102: index key not found, obj# 5099, file 1, block 11186 (2)
, file , block ()
该错误,我相信不少同学都遇到过。从该错误的提示来看,就非常明确了,index key not found。也就是说这是index的问题。那么是什么对象呢? 也就是我们的obj# 5099。 对于object号大于56的,那么我们可以直接rebuild处理。
alert log中其实还有一些其他的错误,这里我们不在一一列举说明。前面已经提到过,由于cache丢失,那么数据库中的很多数据可能都不一致,如果通过修复alert log中的错误,然后提供业务运行,那么存在极大的风险。因此建议重建数据库比较好一些。
这里我们首先将undo进行重建处理,这样可以绕过很多错误,接着开始进行数据库重建工作。