



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
MongoDB通过Map-Reduce优化提速的原理
时间:2022-06-29 10:36:15 编辑:袖梨 来源:一聚教程网
首先我们来讲讲Map-Reduce原理
Map-Reduce基本原理请见下图:
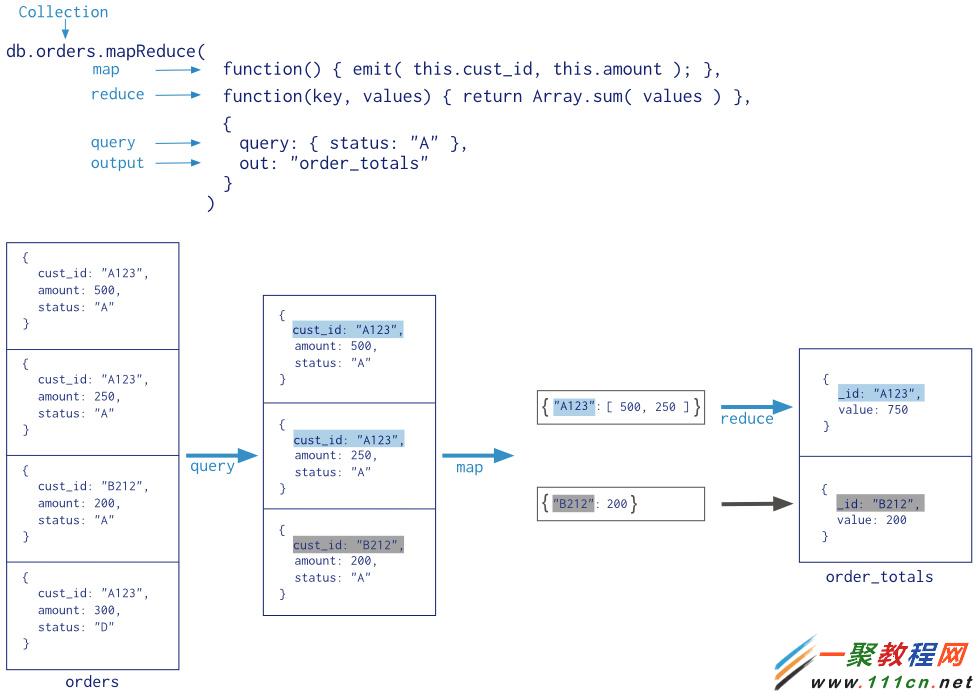
整个数据处理流程可以参见官方上图,先对要进行处理的数据进行Query,然后针对Query的数据进行map,最后针对map的数据进行reduce.
简单了解之后,我们这里取一个例子熟悉下整个过程:
数据基本格式为:
/* 0 */
{
"code" : "A",
"uid" : "id_1",
"count" : 1
}
/* 1 */
{
"code" : "A",
"uid" : "id_1",
"count" : 1
}
/* 2 */
{
"code" : "B",
"uid" : "id_1",
"count" : 1
}
/* 3 */
{
"code" : "B",
"uid" : "id_2",
"count" : 2
}
目的:根据uid计算出count的和 且 这个合涉及到哪些code.
很快就可以写出Map和Reduce函数:
var map = function() {
emit(this.uid, {"code":this.code || "", count:this.count || 1});
};
var reduce = function(key, values) {
var result = {code:{}, count:0};
values.forEach(function(val) {
result.code[val.code] = 1;
result.count += val.count;
});
return result;
}
`
结果为:
/* 0 */
{
"_id" : "id_1",
"value" : {
"code" : {
"A" : 1,
"B" : 1
},
"count" : 3
}
}
/* 1 */
{
"_id" : "id_2",
"value" : {
"code" : "B",
"count" : 2
}
}
这次我省去了query的过程,直接进行Map和Reduce,我们来拆解下过程:
首先,MongoDB会扫描整个数据表(这里省去Query)遍历所有documents,对于每个docuemnt都会根据key(uid)进行map存储.
其次,这个时候MongoDB会对记录的size进行检查( mongod checks every 100 records that the size of the map is not over 50KB, if so it runs reduce on ALL current keys. If size of map is still over 100KB, it dumps all current documents to disk in an “incremental” collection.)
最后根据map的数据进行reduce操作.
好,上面三点是大概的过程,对于Mapping过程,上面实例中会进行
{"id_1", values:[{"code":"A", "count":1}, {"code":"A", "count":1}, {"code":"B", "count":1}}
这样的Emit操作.这点是需要注意的.然后以这样得方式传入到Reduce进行处理,所以Reduce必须对values进行forEach处理.
通过上面这个过程,还有一点要非常注意:如果有很多文档,而且这些文档的分布是非常随机的,当内存比较小时,MongoDB会采取把这些数据存在一个inc自增的文档中.
比方说:我有A, B, C三个key, 每个key有100个, 但是这些key都是随机分布的 比如A…B…A…B..C…A..B..C..当我要先对A进行Emit时需要把所有是A的key的document获取出来,那么这个过程当内存很小时 需要把大部分得document存储到磁盘上.然后内存和磁盘一直交换数据,至到把A全部找出为止(期间每在内存中操作的部分A会先Emit出去).
这种操作肯定很耗时, 如果我们对key进行索引且排好序,那么排好序的A就会大部分在内存中,减少了内存和磁盘的切换次数.
所以对大数据加排序是必须要有的.这个细节至少可以提高很多倍得处理速度.
相关文章
- 夸克浏览器引擎直达-2026夸克浏览器网页版官网入口速览 03-24
- 樱花动漫官网下载入口-樱花动漫最新版本安装包安卓版 03-24
- 嘎嘎射击背包搭配指南 嘎嘎射击装备合成详细教程 03-24
- 嘎嘎射击丧尸模式玩法详解 嘎嘎射击夺金模式玩法介绍 03-24
- 知乎网页版直达-知乎网页版免费畅读 03-24
- 光遇3月12日季节蜡烛位置分享 03-24