



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
MongoDB学习以及集群搭建的实践全纪录
时间:2022-06-29 10:30:32 编辑:袖梨 来源:一聚教程网
前言
最近一些变动,有一个老项目交由我们组负责维护,碰到这样的事情我的内心是崩溃的,但还得强颜欢笑,拍着胸脯说没问题。更悲哀的是,该项目中还使用了mongo,还是自己搭建的,没有交由DBA统一管理,无奈,只能赶鸭子上架,自己学习mongo了。
为什么使用集群架构?
主从:故障转移:无法实现,如果主机宕机,需要关闭slave并且按照master模式启动。无法解决单点故障 无法autofailover 不可以自动主从的切换
为了解决主从的问题,MongoDB3.0之后出现副本集,副本集解决了故障转移的问题,但是一个副本集中的数据是相同的,无法做到海量数据的存储。所以就需要一个架构去解决这个问题。也就是分片式集群。
一个健壮的简单的MongoDB集群的搭建需要十个服务进程(分开搭建需要十台服务器),这里在一台虚拟机上进行搭建。
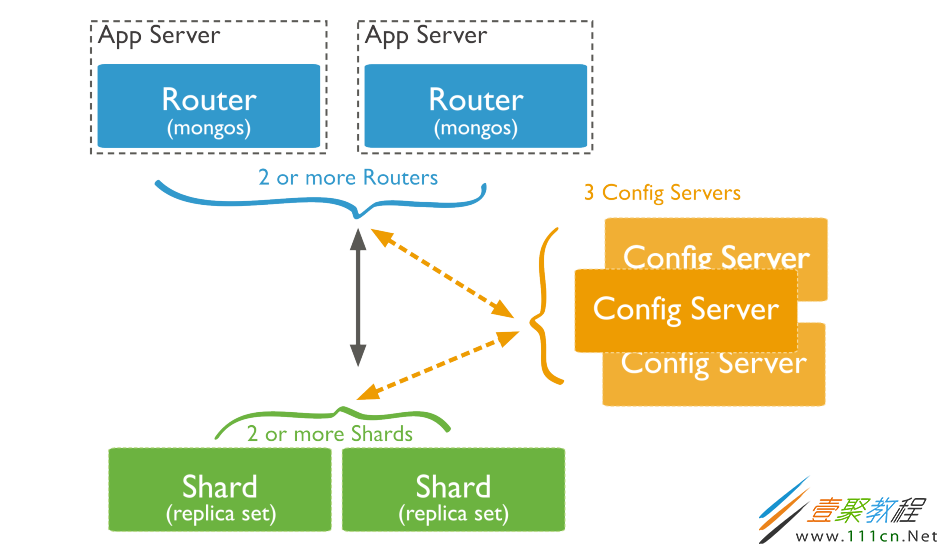
关于MongoDB
mongodb的集群搭建方式主要有三种,主从模式,Replica set模式,sharding模式, 三种模式各有优劣,适用于不同的场合,属Replica set应用最为广泛,主从模式现在用的较少,sharding模式最为完备,但配置维护较为复杂。
而目前接手过来的项目所用的就是Replica set,所以也就主要了解了这个模式。官网介绍可以点击这里
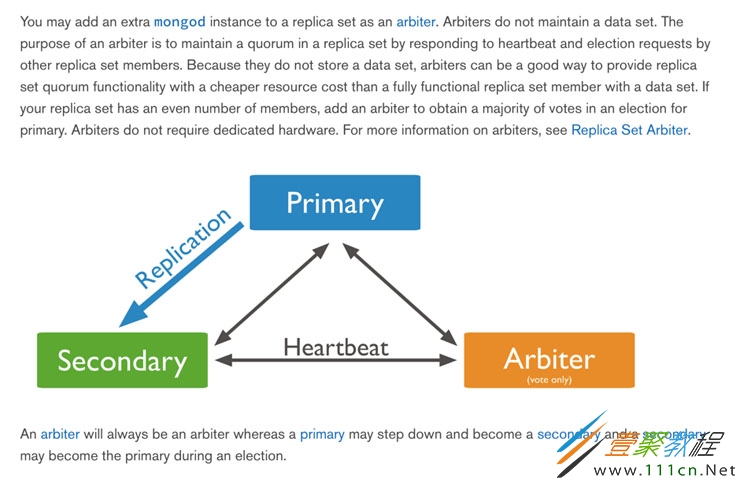
其中Replica Set模式中三类角色有必要知道下:
主节点[Primary]
接收所有的写请求,然后把修改同步到所有Secondary。一个Replica Set只能有一个Primary节点,当Primary挂掉后,其他Secondary或者Arbiter节点会重新选举出来一个主节点。默认读请求也是发到Primary节点处理的,需要转发到Secondary需要客户端修改一下连接配置。
副本节点[Secondary]
与主节点保持同样的数据集。当主节点挂掉的时候,参与选主。
仲裁者[Arbiter]
不保有数据,不参与选主,只进行选主投票。使用Arbiter可以减轻数据存储的硬件需求,Arbiter跑起来几乎没什么大的硬件资源需求,但重要的一点是,在生产环境下它和其他数据节点不要部署在同一台机器上。
注意,一个自动failover的Replica Set节点数必须为奇数,目的是选主投票的时候要有一个大多数才能进行选主决策。
搭建集群
了解了基本概念之后,就开始尝试搭建集群,为了更好的理解,特意找了三台测试机进行部署。
前期准备
首先准备三台测试机:
10.100.1.101 主节点(master)
10.100.1.102 备节点(slave)
10.100.1.103 仲裁点(arbiter)
然后就是mongo的安装包(由于线上用的是3.4.2的版本,所以保持统一)
curl -O https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.4.2.tgz
安装mongo
这里统一安装在/usr/local/mongodb下。
首先解压并重命名:
tar -zxvf mongodb-linux-x86_64-3.0.6.tgz mv mongodb-linux-x86_64-3.4.2/ /usr/local/mongodb
然后在/mongodb下新建几个文件:
#存放mongo配置文件 mkdir -p conf #存放日志文件 mkdir -p logs #存放数据文件 mkdir -p data
这里需要注意下,配置文件中配置的文件路径一定要存在,不然在启动mongo时会出错,mongo启动时也不会自动生成。
接着分配创建配置文件:
主节点:mongodb_master.conf
#master.conf dbpath=/usr/local/mongodb/data logpath=/usr/local/mongodb/logs/mongodb.log pidfilepath=/usr/local/mongodb/master.pid directoryperdb=true logappend=true replSet=testdb port=27017 oplogSize=100 fork=true noprealloc=true
备份节点:vi mongodb_slave.conf
#slave.conf dbpath=/usr/local/mongodb/data logpath=/usr/local/mongodb/logs/mongodb.log pidfilepath=/usr/local/mongodb/master.pid directoryperdb=true logappend=true replSet=testdb port=27017 oplogSize=100 fork=true noprealloc=true
仲裁点: vi mongodb_arbiter.conf
#arbiter.conf dbpath=/usr/local/mongodb/data logpath=/usr/local/mongodb/logs/mongodb.log pidfilepath=/usr/local/mongodb/master.pid directoryperdb=true logappend=true replSet=testdb port=27017 oplogSize=100 fork=true noprealloc=true
在使用上只是最基本的配置,实际场景中可以根据自己的业务需求进行配置,其他参数供参考:
--quiet # 安静输出
--port arg # 指定服务端口号,默认端口27017
--bind_ip arg # 绑定服务IP,若绑定127.0.0.1,则只能本机访问,不指定默认本地所有IP
--logpath arg # 指定MongoDB日志文件,注意是指定文件不是目录
--logappend # 使用追加的方式写日志
--pidfilepath arg # PID File 的完整路径,如果没有设置,则没有PID文件
--keyFile arg # 集群的私钥的完整路径,只对于Replica Set 架构有效
--unixSocketPrefix arg # UNIX域套接字替代目录,(默认为 /tmp)
--fork # 以守护进程的方式运行MongoDB,创建服务器进程
--auth # 启用验证
--cpu # 定期显示CPU的CPU利用率和iowait
--dbpath arg # 指定数据库路径
--diaglog arg # diaglog选项 0=off 1=W 2=R 3=both 7=W+some reads
--directoryperdb # 设置每个数据库将被保存在一个单独的目录
--journal # 启用日志选项,MongoDB的数据操作将会写入到journal文件夹的文件里
--journalOptions arg # 启用日志诊断选项
--ipv6 # 启用IPv6选项
--jsonp # 允许JSONP形式通过HTTP访问(有安全影响)
--maxConns arg # 最大同时连接数 默认2000
--noauth # 不启用验证
--nohttpinterface # 关闭http接口,默认关闭27018端口访问
--noprealloc # 禁用数据文件预分配(往往影响性能)
--noscripting # 禁用脚本引擎
--notablescan # 不允许表扫描
--nounixsocket # 禁用Unix套接字监听
--nssize arg (=16) # 设置信数据库.ns文件大小(MB)
--objcheck # 在收到客户数据,检查的有效性,
--profile arg # 档案参数 0=off 1=slow, 2=all
--quota # 限制每个数据库的文件数,设置默认为8
--quotaFiles arg # number of files allower per db, requires --quota
--rest # 开启简单的rest API
--repair # 修复所有数据库run repair on all dbs
--repairpath arg # 修复库生成的文件的目录,默认为目录名称dbpath
--slowms arg (=100) # value of slow for profile and console log
--smallfiles # 使用较小的默认文件
--syncdelay arg (=60) # 数据写入磁盘的时间秒数(0=never,不推荐)
--sysinfo # 打印一些诊断系统信息
--upgrade # 如果需要升级数据库
--fastsync # 从一个dbpath里启用从库复制服务,该dbpath的数据库是主库的快照,可用于快速启用同步
--autoresync # 如果从库与主库同步数据差得多,自动重新同步,
--oplogSize arg # 设置oplog的大小(MB)
--master # 主库模式
--slave # 从库模式
--source arg # 从库 端口号
--only arg # 指定单一的数据库复制
--slavedelay arg #设置从库同步主库的延迟时间--replSet arg # 设置副本集名称
--configsvr # 声明这是一个集群的config服务,默认端口27019,默认目录/data/configdb
--shardsvr # 声明这是一个集群的分片,默认端口27018
--noMoveParanoia # 关闭偏执为moveChunk数据保存
节点配置完之后就可以启动mongo了,cd到bin目录下:
./mongod -f /etc/mongodb_master.conf ./mongod -f /etc/mongodb_slave.conf ./mongod -f /etc/mongodb_arbiter.conf

配置节点
最后,就需要配置主、备、仲裁节点了。首先我们选择一台服务器进行连接:
./mongo 10.100.1.101:27017 >use admin
然后进行配置:
cfg={ _id:"testdb", members:[ {_id:0,host:'10.100.1.101:27017',priority:2}, {_id:1,host:'10.100.1.102:27017',priority:1}, {_id:2,host:'10.100.1.103:27017',arbiterOnly:true}] };
rs.initiate(cfg) #生效配置
如果不出意外,配置正常生效,基本也就完成了,可以通过rs.status()命令查看相关信息。
到这里,你可以登录数据库测试下成果了,看下正常的数据库操作,主从是否同步了。测试的话这里就不再多说了。
数据备份与还原
简单搭建完集群之后,需要将原来的测试环境数据迁移过来,所以涉及到了mongo的备份与还原。
相对来说还是比较容易的,通过mongodump和mongorestore来实现:
./bin/mongodump -h 10.100.1.101 -d testdb -o . # mongodump -h dbhost -d dbname -o dbdirectory # -h:MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017 # -d:需要备份的数据库实例,例如:test # -o:备份的数据存放位置 ./bin/mongorestore -h 10.100.1.102 -d testdb testdb # mongorestore -h<:port> -d dbname # --host <:port>, -h <:port>:MongoDB所在服务器地址,默认为: localhost:27017 # --db , -d :需要恢复的数据库实例 # --drop:恢复的时候,先删除当前数据,然后恢复备份的数据 # :mongorestore 最后的一个参数,设置备份数据所在位置 # --dir:指定备份的目录,你不能同时指定 和 --dir 选项。
总结
到这里,对于mongo有了一定了解和认识,也基本掌握了搭建和迁移流程,面对三无(无开发,无文档,无注释)的老项目也有点底气了,剩下的时光就要在边看代码边吐槽的日子中渡过啦,想象就心累...
相关文章
- 《星球工匠》电路板获得方法 04-19
- 《长安小时光》下载方法方法 04-19
- 《下一站江湖2》情比金坚作用介绍 04-19
- 《星露谷物语》获得地板方法 04-19
- 《下一站江湖2》虞令羽之墓开启方法 04-19
- 《下一站江湖2》神刀鬼谕获取方法 04-19